一, 时间模块
1. 时间格式
时间戳格式 / float 数据类型 / 格林威治时间 (给机器看的)
print(time.time())
结构化时间 / 时间对象 (从给机器看转换成给人看的过度)
能够通过 . 属性名来获取对象中的值
print(time.strftime( ' %Y-%m-%d ' ))
格式化时间 / 字符串时间 / str数据类型 (主要方便给人们看的)
可以通过你需要的格式来显示时间
time_obj = time.localtime()
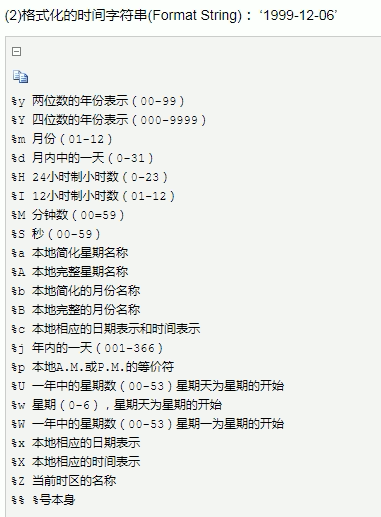
2.
struct_time 表示结构化时间 ;
Format string 表示格式化时间;
Timestamp 表示时间戳时间.
print(time.time()) #表示此刻时间戳时间 print(time.localtime(1500000000)) #表示该时间戳的结构化时间 time_obj = time.localtime(1500000000) #时间戳时间转换成结构化时间 format_time = time.strftime('%y-%m-%d' , time_obj) #结构化时间 #转换成格式化时间 print(format_time) #2018-8-8 格式化时间 struct_time = time.strptime('2018-8-8','%Y-%m-%d') #格式化时间#转换成结构化时间 print(struct_time) print(time.mktime(struct_time)) #结构化时间转换成时间戳时间
二, sys模块 (和Python解释器联系的)
sys.ext() 结束程序 (强制解释器停止)
sys.argv
print(sys.argv)
结果为列表类型
第一个元素是执行这个文件的时候,写在Python命令后面的第一个值 之后的元素在执行Python
的启动的时候可以写多个值(cmd中),都会被依次添加到列表中
三, os模块

print(os.getcwd()) 当前文件的工作路径 即 在哪执行该文件,getcwd的结果就是哪个路径 并非该
文件路径
创建文件夹 / 删除文件夹
os.mkdir('dir/dir2') 创建单级文件夹 若 dir 目录存在则 dir2 可以创建,否则不能创建
os.makedirs('dir1/dir2/dir3') 创建多级文件夹 创建多级嵌套文件夹dir1 dir2 dir3 若文件夹存
在则报错
os.makedirs('dir1/dir2/dir3' , exist_ok=True) 若存在不报错,会覆盖原文件夹
os.rmdir('dir1dir2/dir3') 只能删去一级 不能删除非空文件夹
os.removedirs('dir1dir2/dir3') 递归向上删除文件夹,从最底层开始向上删除空文件夹,若上一级目录
有其它文件则停止
os.listdir() 查看某一路径下的所有文件及其文件夹,以列表的形式存放
os.stat() 获取文件 / 目录信息

path系列

os.path.abspath() 若给的是相对路径则会返回绝对路径,若给的路径不规范 (/) 则会改正
os.path.get.size() 查看文件 / 文件夹大小 (所有文件夹大小都是4096)
四, 序列化模块
字典,列表,数字,对象等序列化成字符串 (序列化)
字符串反序列化成字典,列表,数字,对象等 (反序列化)
1. 为什么要序列化
把内容写入文件
网络传输数据
2. 方法
json : (限制较多)
dic = {'aaa':'bbb','ccc':'ddd'}
str_dic = json.dumps(dic) #序列化
print(dic)
print(str_dic,type(dic))
#结果:
{'aaa':'bbb','ccc':'ddd'}
{"aaa":"bbb","ccc":"ddd"} <class 'str'>
ret = json.loads(str_dic) # 反序列化
print(ret,type(ret))
#结果:
{'aaa':'bbb','ccc':'ddd'} <class 'dict'>
写入文件:(对文件操作用dump /l oad)
dic = {'aaa':'bbb','ccc':'ddd'}
with open ('json_dump','w') as f:
json.dump(dic,f) # 把字典以字符串的方式写入
with open ('json_dump') as f:
print(type(json.load(f)))
#结果 <class 'dict'>
3. json限制 :
json格式的key必须是字符串数据类型
import json dic = {1:2,3:4} str_dic = json.dumps(dic) print(str_dic) #结果 {"1":2,"3":4} #json格式的 key 必须是字符串数据类型,如果是数字为 key,那么dump之后就# 会强行转换成字符串数据类型 dic = {'abc':(1,2,3)} str_dic = json.dumps(dic) #json print(str_dic) new_dic = json.loads(str_dic) print(new_dic) #结果 {"abc":[1,2,3]} {'abc':[1,2,3]} #对元组做value的字典会把元组强制转换成列表 dic = {(1,2,3):'abc'} str_dic = json.dumps(dic) #json print(str_dic) #结果 报错 #不支持,
json格式中字符串只能是双引号(" ")
lst = ['aa',123,'bb'] with open('json_demo','w' ) as f : json.dump(lst,f) #结果 ["aa",123,"bb"] 若在文件中把双引号改为单引号则反序列读取报错 with open ('json_dem') as f: ret = json.load(f) print(ret) #结果 ['aa',123,'bb']
能够多次dump变量/对象,但是不能load多个变量/对象 , 可以用dumps/loads操作
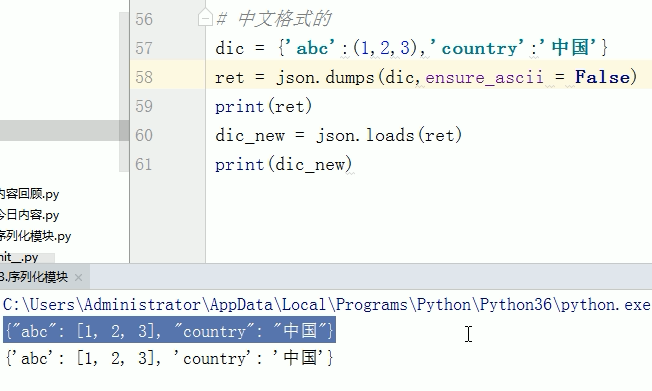
中文格式
dic = {'abc':(1,2,3) , 'cour':'中国'}
ret = json.dumps(dic)
print(ret) # 在序列化中 汉子 会编程unicode编码
#结果 {"abc":[1,2,3] , "cour":"u4e2du56fd"}
dic_new = json.load(ret)
print(dic_new)
#结果 {'abc':(1,2,3) , 'cour':'中国'} 不影响反序列化
dumps中参数 ensure_ascii 表示用ascii存储
json 其他参数(存的时候浪费空间)
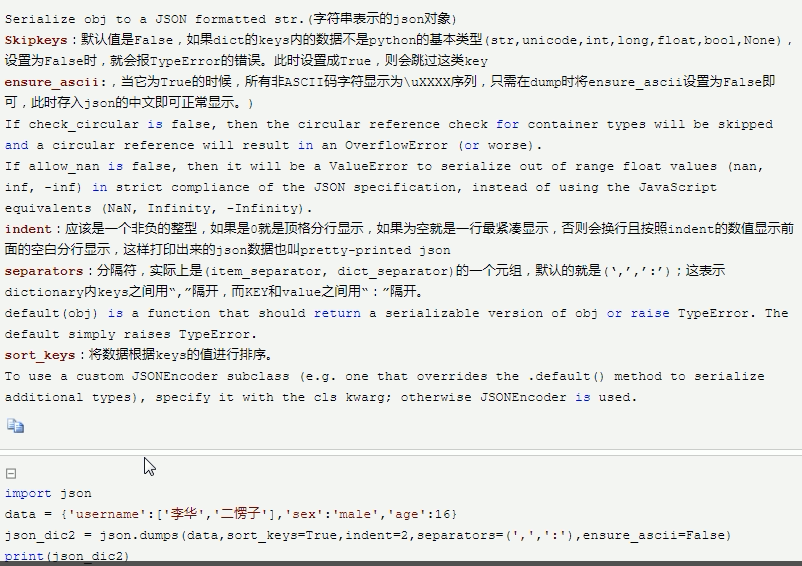
左后一段中 : sort_keys=True表示以key的值排序 ; indent = 2 表示缩进单位 ;
separators = (',',':') 表示以 ',',':' 为分隔符 ; ensure_ascii = Flaser 表示用汉字
set 类型不允许进行序列化
pickle: (支持几乎所有对象)
import pickle dic = {1:(1,2),('a','b'):4} #key为数字,元组类型 pic_dic = pickle.dumps(dic) print(pic_dic) #结果 一串bytes类型(不会报错) new_dic = pickle.loads(pic_dic) print(new_dic) #结果 {1:(1,2),('a','b'):4}
对于对象序列化需要这个对象对应的类在内存中
class Student : def __init__(self,name,age) : self.name = name self.age = age hehe = Student('hehe',83) with open('pickle_demo', 'wb' ) as f : pickle.dump(hehe,f) with open('pickle_demo', 'rb' ) as f : haha = pickle.load(f) print(haha) #结果 hehe # 在对文件操作时应该以 rb / wb 等的形式打开 pickle 只支持bytes类型
能够多次dump变量/对象,而且能load多个变量/对象
不可以for循环文件句柄,因为文件写入是bytes类型,没有分隔符,不能分行.
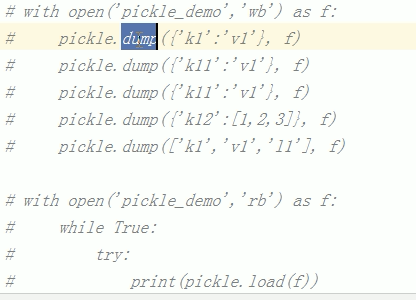

shelve: open()方法
一次性存进去的key值,可以用key的方式全部拿出来,不用一个一个拿出来
用法:
import shelve f = shelve.open('shelve_demo') f['key'] = {'k1':(1,2),'k2':'v2'} f.close() f = shelve.open('shelve_demo') con = f['key'] f.close() print(con) #结果 {'k1':(1,2),'k2':'v2'}
注意:shelve 不支持多个应用同一时间往同一个文件进行写操作,但是在只读操作下允
许通过读操作打开文件 . 然而读操作时不稳定,不排除写的可能.

hashlib (摘要算法的模块)
能够把一个字符串数据类型的变量转换成一个定长的密文的字符串,字符串里的每一个字符
都是十六进制
对于同一个字符串,无论多长只要相同的,在任何环境下,多次执行,在任何语言中使用相同
算法/手段得到的结果永远是相同的 , 只要是不是相同的字符串结果一定不同
md5()算法 : 32位的字符串
update() ; hexdigest() 方法
用法 : 登录验证 ; 文件内容的一致性校验 ; 大文件的已执行校验
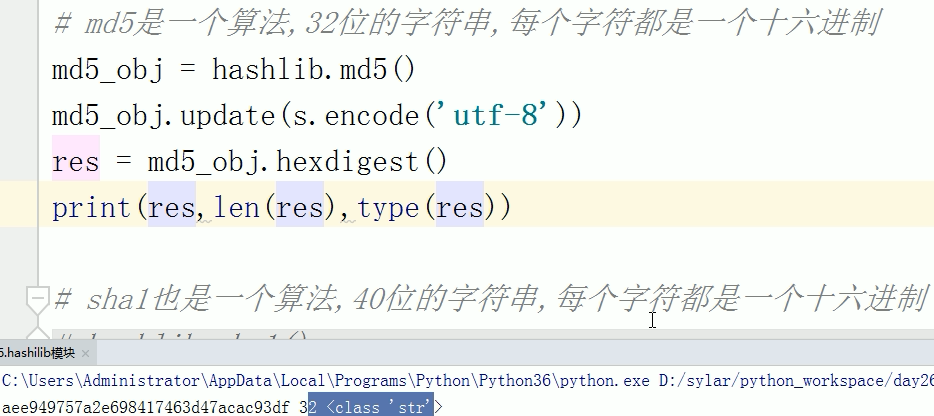
sha1()算法 :40位的字符串
用法和md5算法相同
md5算法计算简单,计算相对较快,
sha1算法相对复杂,计算速度慢
注意 : 俩种算法都不能倒推,不能直接通过密文的字符串倒推出原字符串值
动态加盐:
md5obj = hashlib.md5(username) #username 为盐 #例如 : 游戏昵称不一样,动态加盐后安全性更高 md5obj.update(passwd) #对passwd进行加密/摘要 md5obj.hexdigest()

检验俩个文件内容是否一致

大文件的已执行校验:
对同一字符串的几个阶段的分别摘要的结果 , 和整体摘要结果一样
md5_obj = hashlib.md5() md5_obj.update('hello,dazhi,sb'.encode('utf-8')) print(md5_obj.hexdigest()) md5_obj = hashlib.md5() md5_obj.update('hello'.encode('utf-8')) md5_obj.update('dazhi'.encode('utf-8')) md5_obj.update('sb'.encode('utf-8')) print(md5_obj.hexdigest())
configparser
有一个固定格式的配置文件
有一个对应的模块去帮你做这个文件的字符串处理
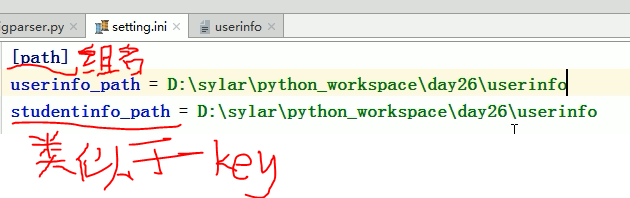

用法:
import configparser #导入模块 config = configparser.Configparser() #实例化对象 config['DEFAULT'] = {'Serve':'45' 'Compre':'yes' 'Compre':'9' } #将要写入的组名和内容
#该组为全局组,可以通过其他组拿到
config['bitbucket.org']={'user':'hg'}
with open('example.ini','w') as f :
config.write(f) #此write是config对象的,不是 f 句柄或文件的
print('bitbucket.org' in config) #True 有该组则返回 T 没有返回 F
print(config['bitbucket.org'] ['user']) #hg
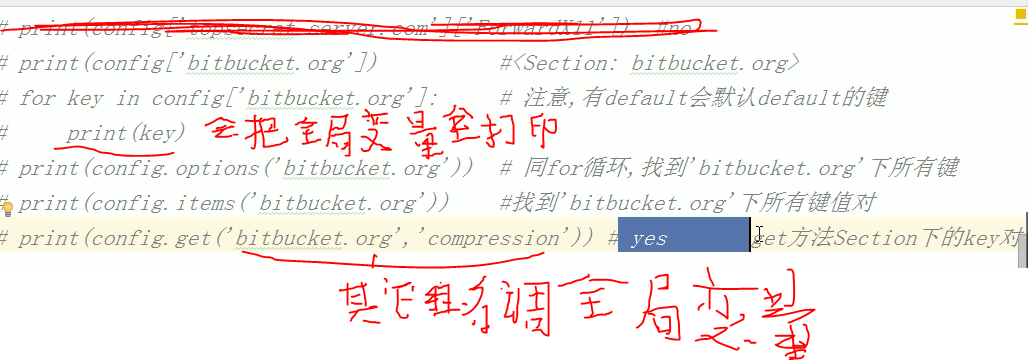
增删改操作

logging
功能 : 1. 日志格式的规范 2. 操作的简化 3. 日志分级
模块的使用 :
普通配置型 简单的 可制定化差
对象配置型 复杂的 可定制化强
日志的分级

级别由高到低

配置报错格式
import logging logging.basicConfig(level=logging.INFO, format='%(asctime)s%(filename)s%[line:%(lineno)d]%(levelname)s%(message)s', #报错时间 ; 错误文件 ; 哪行报错 ;报错级别 ; 错误信息 datefmt='%a,%d %b %Y %H:%M:%S',#时间格式,可以自定义 filename='/tmp/test.log', #把报错写入文件 filemode='w')
..........
#不能将一个log信息即输出到屏幕 又输出到文件


logger对象的形式操作日志文件
既能往文件里输入还能往屏幕上输出
import logging # 创建一个logger对象 logger = logging.getLogger() # 创建一个文件操作符 fh = logging.FileHandler('logger.log',encoding='utf-8') # 创建一个屏幕管理操作符 fh = logging.StreamHandler() # 创建一个日志输出的格式 format1 = logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(message)s') # 文件管理操作符 绑定一个 格式 fh.setFormatter(format1) # # 屏幕管理操作符 绑定一个 格式 sh.setFormatter(format1) logger.setLevel(logging.DEBUG) # logger对象 绑定 文件管理操作符 logger .addHandler(fh) # logger对象 绑定 屏幕管理操作符 logger.addHandler() logger.debug('debug message') logger.info('我的信息') logger.warning('warning message') logger.error('error message') logger.critical('critical message')