注意力seq2seq模型
大部分的seq2seq模型,对所有的输入,一视同仁,同等处理。
但实际上,输出是由输入的各个重点部分产生的。
比如:
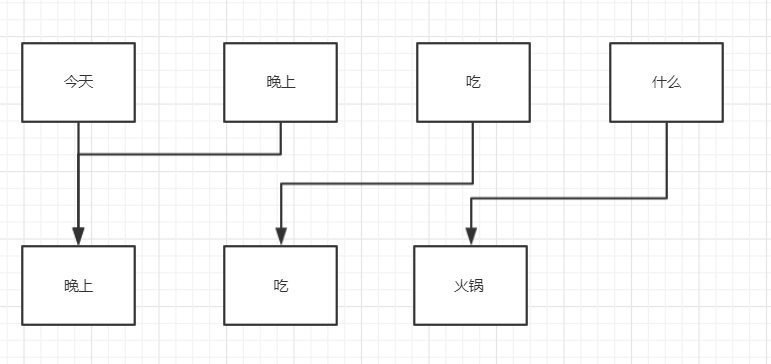
(举例使用,实际比重不是这样)
对于输出“晚上”,
各个输入所占比重: 今天-50%,晚上-50%,吃-100%,什么-0%
对于输出“吃”,
各个输入所占比重: 今天-0%,晚上-0%,吃-100%,什么-0%
特别是在seq2seq的看图说话应用情景中

睡觉还握着笔的baby
这里的重点就是baby,笔!通过这些重点,生成描述。
下面这个图,就是attention的关键原理

tensorlfow 代码
encoder 和常规的seq2seq中的encoder一样,只是在attention模型中,不再需要encoder累计的state状态,需要的是各个各个分词的outputs输出。
在训练的时候,将这个outputs与一个权重值一起拟合逼进目标值。
这个权重值,就是各个输入对目标值的贡献占比,也就是注意力机制!
dec_cell = self.cell(self.hidden_size)
attn_mech = tf.contrib.seq2seq.LuongAttention(
num_units=self.attn_size, # 注意机制权重的size
memory=self.enc_outputs, # 主体的记忆,就是decoder输出outputs
memory_sequence_length=self.enc_sequence_length,
# normalize=False,
name='LuongAttention')
dec_cell = tf.contrib.seq2seq.AttentionWrapper(
cell=dec_cell,
attention_mechanism=attn_mech,
attention_layer_size=self.attn_size,
# attention_history=False, # (in ver 1.2)
name='Attention_Wrapper')
initial_state = dec_cell.zero_state(dtype=tf.float32, batch_size=batch_size)
# output projection (replacing `OutputProjectionWrapper`)
output_layer = Dense(dec_vocab_size + 2, name='output_projection')
# lstm的隐藏层size和attention 注意机制权重的size要相同