
1、CISC、RISC
复杂指令集(Complex Instruction Set Computing,简称 CISC):CPU 的指令集里的机器码是固定长度。计算机历史的早期,所有的 CPU 其实都是 CISC。计算机设计和制造还是严格受硬件层面的限制。CPU 指令集的设计,需要仔细考虑硬件限制。为了性能考虑,很多功能都直接通过硬件电路来完成。为了少用内存,指令的长度也是可变的。
精简指令集(Reduced Instruction Set Computing,简称 RISC):CPU 的指令集里的机器码是可变长度。随着计算机技术的发展,计算机的性能越来越好,存储的空间也越来越大了。实际在 CPU 运行的程序里,80% 的时间都是在使用 20% 的简单指令。

在 RISC 架构里面,CPU 选择把指令“精简”到 20% 的简单指令。而原先的复杂指令,则通过用简单指令组合起来来实现,让软件来实现硬件的功能。这样,CPU 的整个硬件设计就会变得更简单了,在硬件层面提升性能也会变得更容易了.RISC 的 CPU 里完成指令的电路变得简单了,于是也就腾出了更多的空间。这个空间,常常被拿来放通用寄存器。因为 RISC 完成同样的功能,执行的指令数量要比 CISC 多,所以,如果需要反复从内存里面读取指令或者数据到寄存器里来,那么很多时间就会花在访问内存上。于是,RISC 架构的 CPU 往往就有更多的通用寄存器。
2、微指令
指令译码阶段,译码器将机器码翻译成几条微指令,这里的微指令是固定长度的 RISC 风格的。这些微指令放到一个微指令缓冲区里面,然后再从缓冲区里面,分发给到后面的超标量,并且是乱序执行的流水线架构里面。
缺点是需要更复杂的电路和更长的译码时间。
3、图形渲染的流程
图像进行实时渲染的过程,可以被分解成下面这样 5 个步骤:
顶点处理(Vertex Processing)
图元处理(Primitive Processing)
栅格化(Rasterization)
片段处理(Fragment Processing)
像素操作(Pixel Operations)
这一连串的过程,也被称之为图形流水线或者渲染管线。
4、图形加速卡(GPU)
图形渲染的流程是固定的,那我们直接用硬件来处理这部分过程,因为整个计算流程是完全固定的,不需要流水线停顿、乱序执行等等的各类导致 CPU 计算变得复杂的问题。也不需要有什么可编程能力,只要让硬件按照写好的逻辑进行运算就好了。
5、现代 GPU 的三个核心创意
(1)芯片瘦身
CPU中拿来实现处理乱序执行、进行分支预测,以及高速缓存部分,GPU 里不需要,GPU 的整个处理过程是一个流式处理(Stream Processing)的过程。因为没有那么多分支条件,或者复杂的依赖关系,可以把 GPU 里这些对应的电路都可以去掉。只留下取指令、指令译码、ALU 以及执行这些计算需要的寄存器和缓存就好了。

(2)多核并行和 SIMT
这样一来, GPU 电路就比 CPU 简单很多了。就可以在一个 GPU 里面,塞很多个这样并行的 GPU 电路来实现计算,就好像 CPU 里面的多核 CPU 一样。和 CPU 不同的是,我不需要单独去实现什么多线程的计算。因为 GPU 的运算是天然并行的。

CPU 里有一种叫作 SIMD 的处理技术。这个技术是说,在做向量计算的时候,要执行的指令是一样的,只是同一个指令的数据有所不同而已。在 GPU 的渲染管线里,这个技术可就大有用处了。
GPU 就借鉴了 CPU 里面的 SIMD,用了一种叫作SIMT(Single Instruction,Multiple Threads)的技术。SIMT 呢,比 SIMD 更加灵活。在 SIMD 里面,CPU 一次性取出了固定长度的多个数据,放到寄存器里面,用一个指令去执行。而 SIMT,可以把多条数据,交给不同的线程去处理。各个线程里面执行的指令流程是一样的,但是可能根据数据的不同,走到不同的条件分支。这样,相同的代码和相同的流程,可能执行不同的具体的指令。这个线程走到的是 if 的条件分支,另外一个线程走到的就是 else 的条件分支了。GPU 设计就可以进一步进化,也就是在取指令和指令译码的阶段,取出的指令可以给到后面多个不同的 ALU 并行进行运算。这样,我们的一个 GPU 的核里,就可以放下更多的 ALU,同时进行更多的并行运算了。

(3)GPU 里的“超线程”
GPU 里的指令,可能会遇到和 CPU 类似的“流水线停顿”问题。遇到停顿的时候,调度一些别的计算任务给当前的 ALU。要针对这个任务,提供更多的执行上下文。
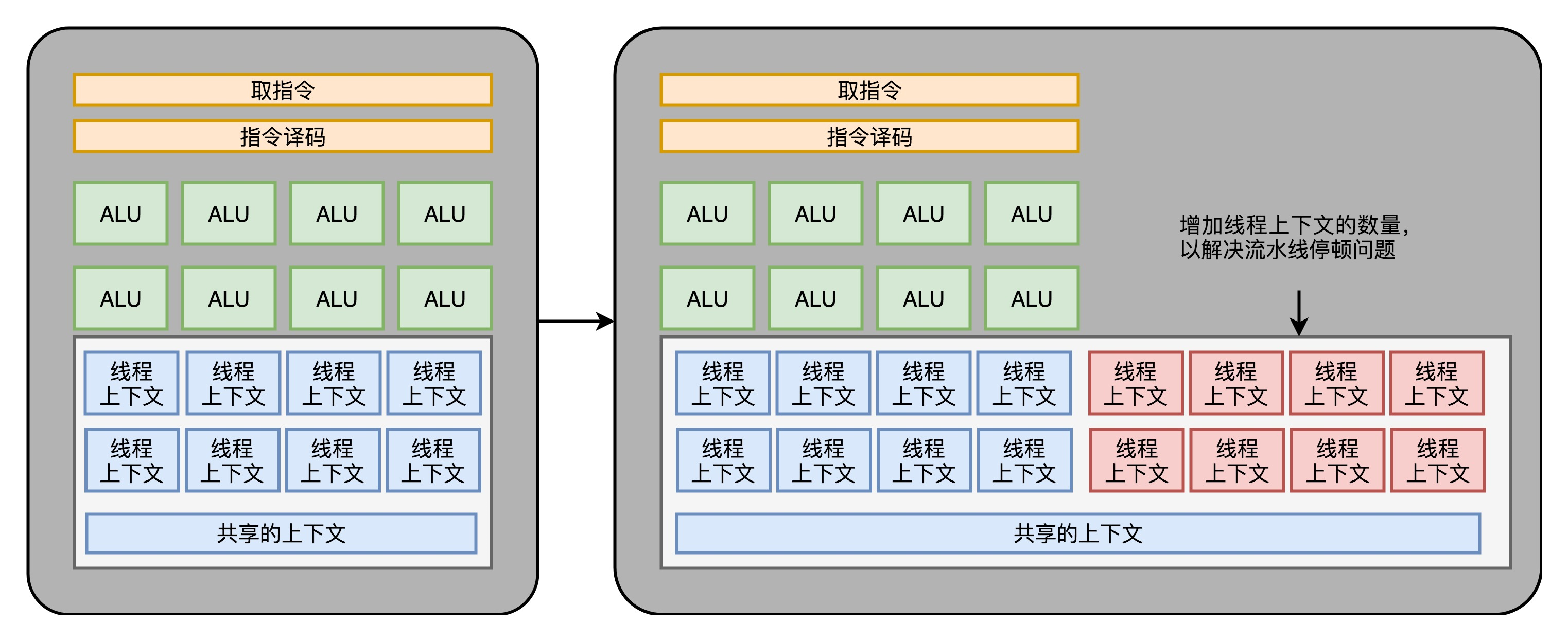
GPU 里面的多核、多 ALU,加上多 Context,使得它的并行能力极强。同样架构的 GPU,如果光是做数值计算的话,算力在同样价格的 CPU 的十倍以上。而这个强大计算能力,以及“统一着色器架构”,使得 GPU 非常适合进行深度学习的计算模式,也就是海量计算,容易并行,并且没有太多的控制分支逻辑。
使用 GPU 进行深度学习,往往能够把深度学习算法的训练时间,缩短一个,乃至两个数量级。而 GPU 现在也越来越多地用在各种科学计算和机器学习上,而不仅仅是用在图形渲染上了。