预备知识:
管道:它是一个单向的,可以把前一个的数据输出导向到下一个命令的工具,这样可以实现多个命令组合处理一套数据。
它的符号是 "|" 管道只能处理经过前面一个命令传过来的正确信息,也就是standard output的信息,对于standard error并没有直接处理。一般会忽略。
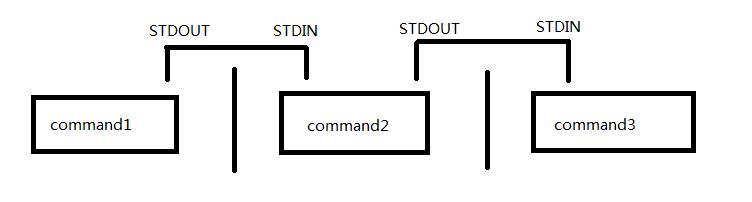
过程就如上图所示的,前面命令的标准输出变为下一个命令的标准输入。
注意:
- 管道命令仅处理standard output,对于standard error会予以忽略。
- 管道命令必须能够接收来自前一个命令的数据成为standard input 继续处理才行。
soga,那么接下来看一些命令对管道的应用。
1.选取命令:cut,grep
- cut 选取命令,以行为单位处理信息。
#cut [-bn] [file] 或 cut [-c] [file] 或 cut [-df] [file] #参数 -b 以字节为单位进行分割。这些字节忽略多字节字符边界,除非指定-n参数 -c 以字符为单位进行分割 -d 自定义分隔符,默认为制表符 -f 依据-d参数的分割字符将一段信息分割为数段,用-f取出第几段的意思 -n 取消分割多字节字符,仅和-b标志一起使用。如果字符的最后一个字节落在由-b标志的List参数指示的</br>范围之内,该字符将被写出,否则该字符被排除(看不懂)
cut一般以什么为依据呢? 也就是说,我怎么告诉cut我想定位到的剪切内容呢?
cut命令主要是接受三个定位方法:
第一,字节(bytes),用选项-b
第二,字符(characters),用选项-c
第三,域(fields),用选项-d指定,-f来指定取出哪一段
- grep 前面的cut是取出一行中的某些字符,而grep是来筛选某一行存在你需要的信息,则把该行拿出来
# grep [-acinv] [--color=auto] '查找的字符串' filename 参数: -a 将binary文件以text的方式查找数据 -c 计算查找到匹配字符串的次数 -i 忽略大小写 -n 顺便输出行号 -v 反向选择,即显示没有“查找字符串”的那一行 --color=auto 将查找到的字符串的关键词加上颜色
grep还有一些高级的用法,在我的另外一篇文章中有介绍:grep的高级用法
2.排序命令:sort, wc,uniq
主要用于在你不需要查看具体数据,而是只是想查看关键字的出现次数等情况。
- sort 进行排序,根据不同的关键词。因为可能是字符排序,所以这里需要确定你的系统的编码,最好是LANG=C
# sort [-fbMnrtuk] [file or stdin] 参数: -f 忽略大小写 -b 忽略最前面的空格符部分 -M 以月份名字进行排序(默认是以文本类型进行排序) -n 使用纯数字进行排序 -r 反向排序 -u 就是uniq,相同的数据只出现一行 -t 分隔符,默认以 [tab] 键为分割 -k 以那个区间来进行排序的意思
#对passwd文件进行排序 $ cat /etc/passwd | sort ... #如果需要取第三列来进行排序呢 $ cat /etc/passwd | sort -t ':' -k 3
sort命令很有用,解决很多时候我们需要排序的麻烦。
- uniq 相当于sort的 -u 选项 取出一些重复的数据。
# uniq [-ic] -i 忽略大小写 -c 对重复信息计数
- wc 计数工具
wc [-lwm] 参数: -l 仅列出多少行 -w 仅列出多少字(英文单词) -m 多少字符
默认不加选项的会输出三个数字,分别代表行,字数,字符数