第二篇 核心技术篇
第三章 网络爬虫实现原理与实现技术
3.1 网络爬虫实现原理详解
不同类型的网络爬虫,其实原理也是不同的,但在实现原理中,会有很多共性。在此
以通用网络爬虫和聚焦网络爬虫来分别讲解网络爬虫的实现原理。
1 通用网络爬虫
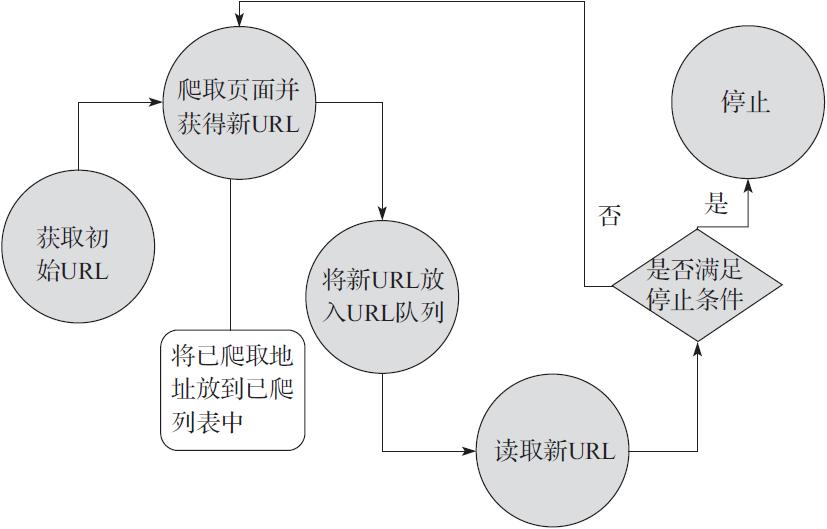
首先我们来看通用网络爬虫的实现原理。通用网络爬虫的实现原理及过程可以简要
概括如下:
1)获取初始的URL。初始的URL地址可以由用户人为地指定,也可以由用户指定的某
个或某几个初始爬取网页决定。
2)根据初始的URL爬取页面并获得新的URL。获得初始的URL地址之后,首先需要爬
取对应URL地址中的网页,爬取了对应的URL地址中的网页后,将网页存储到原始
数据库中,并且在爬取网页的同时,发现新的URL地址,同时将已爬取的URL地址
存放到一个URL列表中,用于去重及判断爬取的进程。
3)将新的URL放到URL队列中。在第2步中,获取了下一个新的URL地址之后,会将新
的URL地址放到URL队列中。
4)从URL队列中读取新的URL,并依据新的URL爬取网页,同时从新网页中获取新URL,
并重复上述的爬取过程。
5)满足爬虫系统设置的停止条件时,停止爬取。在编写爬虫的时候,一般会设置相
应的停止条件。如果没有设置停止条件,爬虫则会一直爬取下去,一直到无法获
取新的URL地址为止,若设置了停止条件,爬虫则会在停止条件满足时停止爬取。
以上过程就是通用网络爬虫实现过程和基本原理。接下来就说明聚焦网络爬虫的基本
原理与实现过程。
2 聚焦网络爬虫
聚焦网络爬虫,由于其需要有目的的进行爬取,所以对于通用网络爬虫来说,必须
要增加目标的定义和过滤机制,具体来说,其执行原理和过程需要比通用网络爬虫
多出三部,即目标的定义、无关链接的过滤、下一步要爬取的URL地址的选取等。
如3-2所示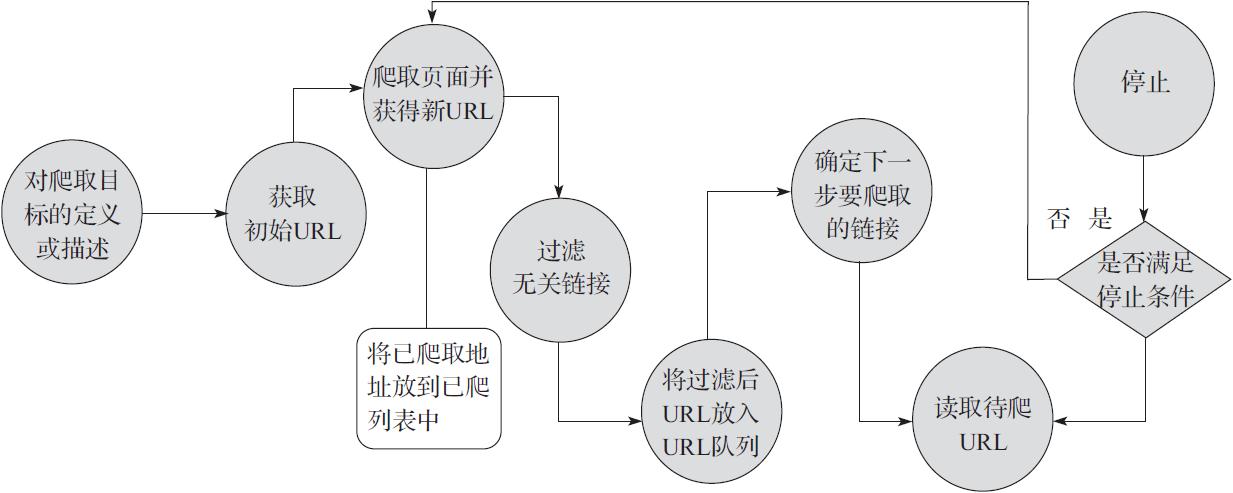
1 对爬取目标的定义和描述。在聚焦网络爬虫中,我们首先需要依据爬取需求定义好
该聚焦网络爬虫爬取的目标,以及进行相关的描述。
2 获取初始的URL。
3 根据初始的URL爬取页面,并获得新的URL
4 从新的URL中过滤与爬取目标无关的链接,同时也需要将以爬取的URL地址存放到
URL列表中,哟牛股屈从和判断爬取的进程。
5 将过滤后的链接放到URL队列中。
6 从URL队列中,根据搜索算法,确定URL的优先级,并确定下一步要爬取的URL地址。
在通用网络爬虫中,下一步爬取哪些URL地址,是不太重要的,但是在聚焦网络爬
虫中,由于其具有目的性,故而下一步爬取哪些URL地址相对来说是比较重要的。
对于聚焦网络爬虫来说,不同的爬取顺序,可能倒是爬虫的执行效率不同,所以,
我们需要依据搜索策略来确定下一步需要爬取哪些URL地址。
7 从下一步要爬取的URL地址中,读取新的URL,然后依据新的URL地址爬取网页,
并重复上述爬取过程。
8 满足系统中设置的停止条件时,或无法获取新的URL地址时,停止爬行。