3.2 爬行策略
现在我们初步掌握了网络爬虫的实现原理以及相应的工作流程,下面来了解网络爬
虫的爬行策略。
在网络爬虫爬取的过程,在待爬取的URL列表中,可能会有很多URL地址,那么这些URL地址
,爬虫应该有怎样的爬取顺序呢?虽然对于通用网络爬虫而言,爬取顺序并不是那么重要。
而对于聚焦网络爬虫而言,爬取的顺序非常重要,而爬取的顺序就是有爬行策略决定。
爬行策略有深度优先爬行策略、广度优先爬行策略、大站优先爬行策略、反链策略、其他
爬行策略等。
如图3-3所示,假设有一个网站,ABCDEFG分别为站点下的网页,图中箭头表示网页的层次结构
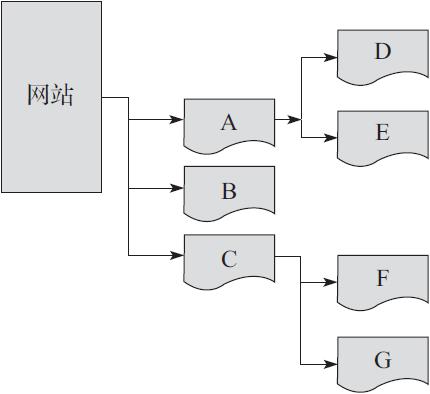
若该网站的所有网页都在爬行页面中,采取不同的爬行策略,则其爬取顺序不同。
比如,按照深度优先爬行策略爬取的话,它会首先爬取第一个网页,然后再进一步对该网页
下面的链接进行爬取。其爬行顺序为:A-> D -> E -> B -> C -> F -> G
而如果是按照广度优先爬行策略去爬取的话,则会爬取同一层次的网页,将同一层次网页爬取
之后再选择下一层次的网页去爬行。其爬行顺序为:A -> B -> C -> D -> E -> F -> G
我们也可以采取大战爬行策略。我们可以按对应网页所属站点进行分类,如果某个网站的
页面数量多,我们就称其为大战,按照这种策略,网页数量越多则网站越大,然后,优先
爬取大站中URL地址。
一个网页的反向链接数,指的是该网页被其他网页指向的次数,这个次数在一定程度上代
表着该网页被其他网页的推荐次数。所以,如果按反链策略去爬行的话,那么哪个网页的
反链数量越多,则哪个网页将被优先爬取。但是,在实际情况中,如果单纯按反链策略去
决定一个网页的优先程度的话,那么可能会出现大量的作弊情况。比如,做一些垃圾站群,
并将这些网站互相链接,如果这样的话,每个站点都将获得较高的反链,从而达到作弊的
目的。作为爬虫项目方,我们当然不希望受到这种作弊行为的干扰,所以,如果采用反向
链接策略去爬取的话,一般会考虑可靠的反链数。
除了以上这些爬行策略,在实际中还有很多其他的爬行策略,比如OPIC策略、
Partial PageRank策略等。