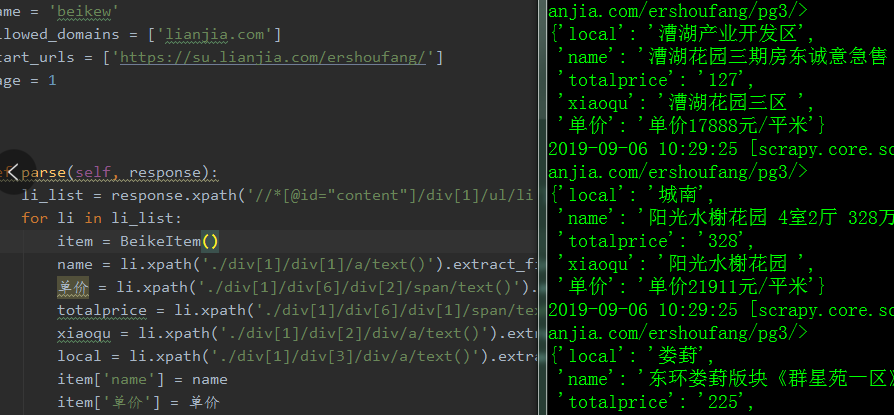
直接上代码,顺便在这里记录,时间2190906.
刚开始爬贝壳网的,发现有反爬虫,我也不会绕,换了链家网,原来中文也可以做变量。
spider.py
1 # -*- coding: utf-8 -*- 2 import scrapy 3 4 from beike.items import BeikeItem 5 6 class BeikewSpider(scrapy.Spider): 7 name = 'beikew' 8 allowed_domains = ['lianjia.com'] 9 start_urls = ['https://su.lianjia.com/ershoufang/'] 10 page = 1 11 12 13 def parse(self, response): 14 li_list = response.xpath('//*[@id="content"]/div[1]/ul/li') 15 for li in li_list: 16 item = BeikeItem() 17 name = li.xpath('./div[1]/div[1]/a/text()').extract_first() 18 单价 = li.xpath('./div[1]/div[6]/div[2]/span/text()').extract_first() 19 totalprice = li.xpath('./div[1]/div[6]/div[1]/span/text()').extract_first() 20 xiaoqu = li.xpath('./div[1]/div[2]/div/a/text()').extract_first() 21 local = li.xpath('./div[1]/div[3]/div/a/text()').extract_first() 22 item['name'] = name 23 item['单价'] = 单价 #在这里试试中文的,才知道原来中文也可以做变量 24 item['totalprice'] = totalprice 25 item['xiaoqu'] = xiaoqu 26 item['local'] = local 27 yield item 28 29 if self.page <= 50:#这里爬取了50页数据,可以随意更改 30 self.page += 1 31 url_new = str(self.page) 32 new_page_url = 'https://su.lianjia.com/ershoufang/pg' + url_new 33 yield scrapy.Request(url = new_page_url, callback = (self.parse))
item.py
1 import scrapy 2 3 class BeikeItem(scrapy.Item): 4 xiaoqu = scrapy.Field() 5 name = scrapy.Field() 6 单价 = scrapy.Field() 7 totalprice = scrapy.Field() 8 local = scrapy.Field()
settings.py
1 BOT_NAME = 'beike' #这些代码在settings里启用或者添加的。 2 SPIDER_MODULES = ['beike.spiders'] 3 NEWSPIDER_MODULE = 'beike.spiders' 4 FEED_EXPORT_ENCODING ='utf-8' 5 FEED_EXPORT_ENCODING = 'gb18030' 6 ROBOTSTXT_OBEY = True 7 DOWNLOAD_DELAY = 1
只用到了3个y文件,其他的都是命令生成的,保持默认。
执行结果: