前言
关于值类型和引用类型,这又是一个十分沉重的话题。
一般人都知道:
1、C#中又两大数据类型,即:值类型和引用类型。
2、值类型存在在栈(又称“堆栈”)上,引用类型存储在堆上。
3、值类型转换为引用类型会发生“装箱”,引用类型转换为值类型会发生“拆箱”;装箱和拆箱过程会比较耗费资源(.NET后来提供了泛型来优化这一个过程)。
以上这些观点,首先是有错误的,其次是很肤浅的。
这里的堆和这里的栈
这里的堆和栈并不是直接等于数据结构中的堆栈。堆和栈都是内存中的空间,在C#世界中,内存不止这两个角色:在C#中,内存分成5个区,即:
1、堆
2、栈
3、自由存储区、全局/静态存储区
4、常量存储区
众所周知,在32位操作系统中分配给每个进程的最大内存是2G(总共4G,系统隐藏了2G,如果是企业用户则分配为3G隐藏1G)。而我们从任务管理器中很容易看出我们会有多个进程同时发生,这样4G*n 常常超出我们内存条容量大小。所以:这里的内存,并不是指内存条的内存容量,而是虚拟内存(硬盘存储)
堆、栈(堆栈)是做什么的
栈负责保存我们的代码执行(或调用)路径,而堆则负责保存对象(或者说数据,接下来将谈到很多关于堆的问题)的路径。
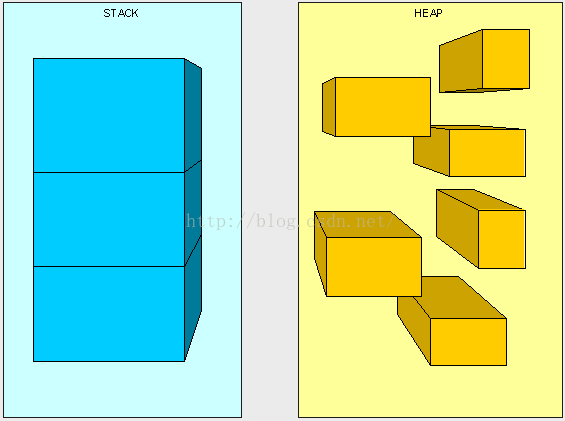
可以将栈想象成一堆从顶向下堆叠的盒子。当每调用一次方法时,我们将应用程序中所要发生的事情记录在栈顶的一个盒子中,而我们每次只能够使用栈顶的那个盒子。当我们栈顶的盒子被使用完之后,或者说方法执行完毕之后,我们将抛开这个盒子然后继续使用栈顶上的新盒子。堆的工作原理比较相似,但大多数时候堆用作保存信息而非保存执行路径,因此堆能够在任意时间被访问。与栈相比堆没有任何访问限制,堆就像床上的旧衣服,我们并没有花时间去整理,那是因为可以随时找到一件我们需要的衣服,而栈就像储物柜里堆叠的鞋盒,我们只能从最顶层的盒子开始取,直到发现那只合适的。
如何决定放哪儿?
1. 引用类型总是放在堆中。(够简单的吧?)
2. 值类型和指针总是放在它们被声明的地方。(这条稍微复杂点,需要知道栈是如何工作的,然后才能断定是在哪儿被声明的。)
就像我们先前提到的,栈是负责保存我们的代码执行(或调用)时的路径。当我们的代码开始调用一个方法时,将放置一段编码指令(在方法中)到栈上,紧接着放置方法的参数,然后代码执行到方法中的被“压栈”至栈顶的变量位置。通过以下例子很容易理解...
下面是一个方法(Method):
public int AddFive(int pValue)
{
int result;
result = pValue + 5;
return result;
}
现在就来看看在栈顶发生了些什么,记住我们所观察的栈顶下实际已经压入了许多别的内容。
首先方法(只包含需要执行的逻辑字节,即执行该方法的指令,而非方法体内的数据)入栈,紧接着是方法的参数入栈。(我们将在后面讨论更多的参数传递)
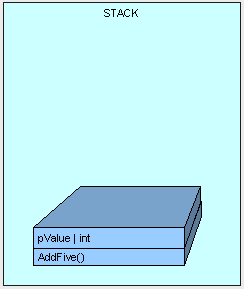
接着,控制(即执行方法的线程)被传递到堆栈中AddFive()的指令上,

当方法执行时,我们需要在栈上为“result”变量分配一些内存,
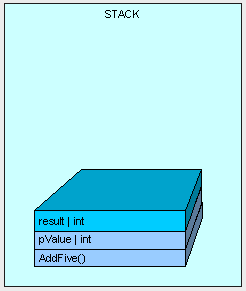
方法执行完成,然后方法的结果被返回。
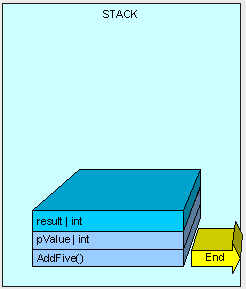
通过将栈指针指向AddFive()方法曾使用的可用的内存地址,所有在栈上的该方法所使用内存都被清空,且程序将自动回到栈上最初的方法调用的位置(在本例中不会看到)。
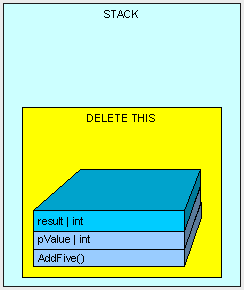
在这个例子中,我们的"result"变量是被放置在栈上的,事实上,当值类型数据在方法体中被声明时,它们都是被放置在栈上的。
值类型数据有时也被放置在堆上。记住这条规则--值类型总是放在它们被声明的地方。好的,如果一个值类型数据在方法体外被声明,且存在于一个引用类型中,那么它将被堆中的引用类型所取代。
来看另一个例子:
假如我们有这样一个MyInt类(它是引用类型因为它是一个类类型):
public class MyInt
{
publicint MyValue;
}
然后执行下面的方法:
public MyInt AddFive(int pValue)
{
MyInt result = new MyInt();
result.MyValue = pValue + 5;
return result;
}
就像前面提到的,方法及方法的参数被放置到栈上,接下来,控制被传递到堆栈中AddFive()的指令上。
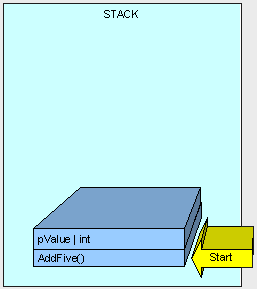
接着会出现一些有趣的现象...
因为"MyInt"是一个引用类型,它将被放置在堆上,同时在栈上生成一个指向这个堆的指针引用。
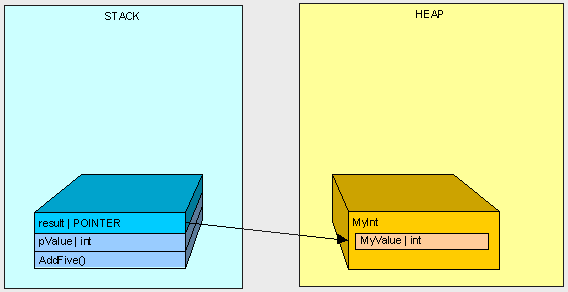
在AddFive()方法被执行之后,我们将清空...
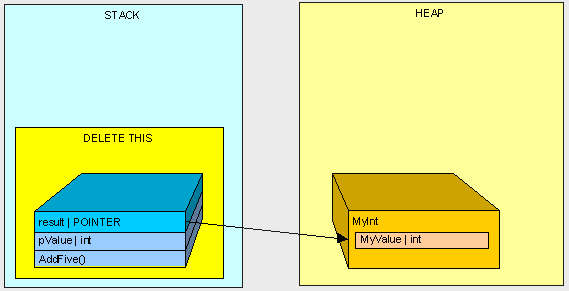
我们将剩下孤独的MyInt对象在堆中(栈中将不会存在任何指向MyInt对象的指针!)
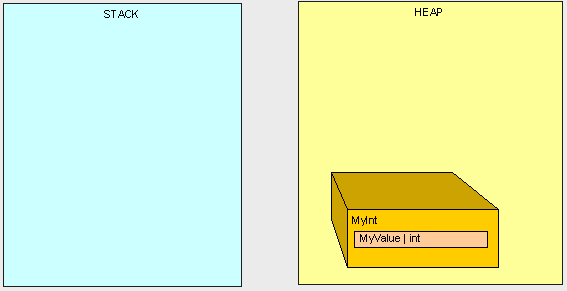
这就是垃圾回收器(后简称GC)起作用的地方。当我们的程序达到了一个特定的内存阀值,我们需要更多的堆空间的时候,GC开始起作用。GC将停止所有正在运行的线程,找出在堆中存在的所有不再被主程序访问的对象,并删除它们。然后GC会重新组织堆中所有剩下的对象来节省空间,并调整栈和堆中所有与这些对象相关的指针。你肯定会想到这个过程非常耗费性能,所以这时你就会知道为什么我们需要如此重视栈和堆里有些什么,特别是在需要编写高性能的代码时。
内存中是如何存放的?
我们还是从这下面这一张图片开始说起吧:
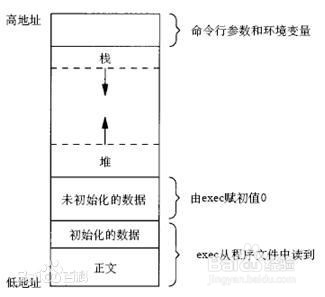
高、底地址,我们姑且认为没用实际意义,就像给内存空间编号(内存中按一字节即8位位一单元,依次编号)
下面举两个例子来说明:加入我们的搞地址开始位置编号是100000,低地址开始位置编号是100
1、
当前的堆栈指针为100000,这表明它的下一个自由存储空间从99999开始,当我们在C#中声明一个int类型的变量A,因为int类型是四个字节,所以它将分配在99996到99999这个存储单元中。如果我们接着声明double变量B(8字节),该变量将分配在99988到99995这个存储单元。 如果代码运行到他们的作用域之外,这时候A和B两个变量都将被删除,此时的顺序正好相反,先删除变量B,同时堆栈指针会递增8,也就是重新指向到99996这个位置;接下来删除变量A,堆栈指针重新指向10000。如果两个变量是同时声明的。如int A,B,此时我们并不知道A和B的分配顺序,但是编译器会确保他们的删除顺序正好和分配顺序相反。
2、
了解堆栈上的分配方式之后,很明显,它的性能相当高,同时我们也发现了它的一个缺点:变量的生存期必须嵌套。这对于某些情况来说是无法接受的,有时候我们需要存储一些数据并且在方法退出后仍然能保证这部分数据是可以使用的。为此,虚拟内存另外分配了一部分区域,我们称之为托管堆。托管堆和传统的堆很大的一个不同点在于,托管堆在垃圾收集器的控制下进行工作。引用类型就分配在托管堆上,下面我们来看看引用类型的分配过程。
假设我们需要声明一个Person类并对它进行实例化。 Person p = new Person(); 首先, 系统会在堆栈上给p这个变量在堆栈上分配存储空间,当然它只是一个引用而已,用来存放Person实例在托管堆上的位置,并没有存放真正的Person实例。因为它仅仅是存放一个地址(一个整数值),所以它将在堆栈上占据4个字节的空间。接下来Person实例将会被存放在托管堆上。和堆栈不同,托管堆是由下往上分配的,假设这个实例需要占据10个字节,假设托管堆上的地址为100,那么它将分配在100到109这个存储单元。 需要注意的是,这个分配和实例的大小有关,如果实例小于85000字节,它会被分配在托管堆。如果超过了85000字节,它将被分配在LOH上 。
由此可见,这个分配过程比值类型的分配方式更为复杂,因此也就不可避免的有性能方面的损耗。这也是为什么对于小数据量的数据结构我们更愿意使用结构而不是类
一生二,二生万物
“一”是object,“二”是值类型和引用类型,“万物”就是C#程序员的各种代码和程序。