目录
Ch1 简介
1.1 实验方法
1.2 评价指标
1.2.1 用户满意度
1.2.2 预测准确率
Ch2 协同过滤(CF):通过分析用户的行为来推荐
(购买本商品的用户还购买了……)
2.1 基于用户的CF (UserCF)
对于用户U,找与其相似的用户A,把A喜欢的推荐给U
2.1.1 计算用户间相似度
2.1.2 UserCF算法
2.2 基于物品的CF (ItemCF)
用户U购买过物品A,所以可能还喜欢(与A相似的)物品B
2.2.1 UserCF存在的问题:
2.2.2 计算物品间相似度
2.2.3 ItemCF
2.2.4 改进:
(1) 用户活跃度对物品相似度的影响:IUF
(2) 归一化物品相似度
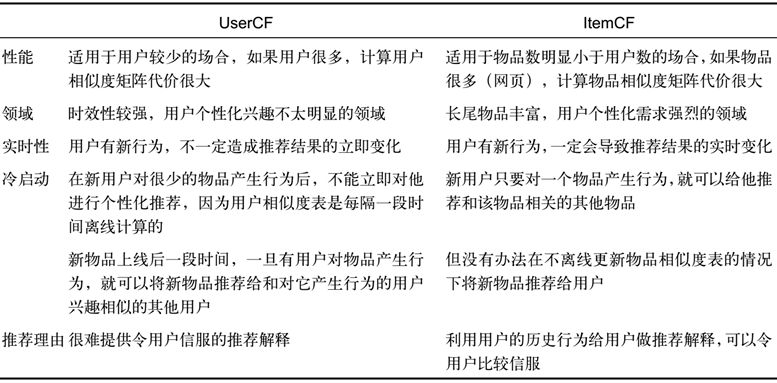
2.3 UserCF和ItemCF比较
2.4 Latent Factor Model
LFM重点解决对物品自动聚类的问题,通过一个trained model来进行。
2.5 Graph Based Model
Ch3推荐系统冷启动问题
Ch4利用用户标签数据
让普通用户给物品打标签
4.1用户标签介绍
4.2 基于标签的推荐系统
4.2.1 评价指标
4.2.2 推荐算法
(1) 基本算法
(2)改进:Tag Based TFIDF
(3)改进:标签扩展
(4)改进:标签清理
(5)改进:Graph Based Model
4.3 给用户推荐标签
给用户提供几个备选的tag,协助用户给物品打标签。
Ch5 利用上下文信息
上下文:用户所处的时间/地点/……
5.1 时间效应
5.2 时间上下文推荐算法
最近最热门
时间上下文相关的ItemCF算法
时间上下文相关的UserCF算法
时间段图模型
Ch6 利用社交网络数据
6.1 推荐算法
基于邻域的社会化推荐算法
基于图的社会化推荐算法
实际系统中的社会化推荐算法
社会化推荐系统和协同过滤推荐系统
信息流推荐
6.2 给用户推荐好友
基于内容的匹配
推荐用户属性相似的
基于共同兴趣的好友推荐
推荐兴趣相同的,用UserCF
基于社交网络图的好友推荐
Ch7实例
7.1 推荐系统架构
7.2 推荐引擎架构
Ch8评分预测问题
评分预测问题就是如何通过已知的用户历史评分记录预测未知的用户评分记录。
Ch1 简介
1.1 实验方法: 原书P39
|
Offline |
在dataset上training/testing |
|
Online |
将系统上线做AB testing |
|
用户调查 |
让真实用户来测试推荐系统 |
AB测试:AB测试是一种很常用的在线评测算法的实验方法。它通过一定的规则将用户随机分成几组,并对不同组的用户采用不同的算法,然后通过统计不同组用户的各种不同的评测指标比较不同算法,比如可以统计不同组用户的点击率,通过点击率比较不同算法的性能。对AB测试感兴趣的读者可以浏览一下网站http://www.abtests.com/,该网站给出了很多通过实际AB测试提高网站用户满意度的例子,从中我们可以学习到如何进行合理的AB测试。AB测试的优点是可以公平获得不同算法实际在线时的性能指标,包括商业上关注的指标。AB测试的缺点主要是周期比较长,必须进行长期的实验才能得到可靠的结果。因此一般不会用AB测试测试所有的算法,而只是用它测试那些在离线实验和用户调查中表现很好的算法。其次,一个大型网站的AB测试系统的设计也是一项复杂的工程。一个大型网站的架构分前端和后端,从前端展示给用户的界面到最后端的算法,中间往往经过了很多层,这些层往往由不同的团队控制,而且都有可能做AB测试。如果为不同的层分别设计AB测试系统,那么不同的AB测试之间往往会互相干扰。比如,当我们进行一个后台推荐算法的AB测试,同时网页团队在做推荐页面的界面AB测试,最终的结果就是你不知道测试结果是自己算法的改变,还是推荐界面的改变造成的。因此,切分流量是AB测试中的关键,不同的层以及控制这些层的团队需要从一个统一的地方获得自己AB测试的流量,而不同层之间的流量应该是正交的。
长尾理论:人们只关注曝光率高的项目,而忽略曝光率低的项目。试验表明,位于长尾位置的曝光率低的项目所产生的利润不低于曝光率高的项目的利润。推荐系统正好可以给所有项目提供曝光的机会,以此来挖掘长尾项目的潜在利润。
1.2 评价指标:
1.2.1 用户满意度
搜集/问卷调查用户的行为/反馈
1.2.2 预测准确率
用离线实验(Dataset)计算
评价指标:
(1) TopN推荐:Recall/Precision 原书P43

(2) 预测用户评分:RMSE/MAE 原书P42

(3) Others: 原书P44-50
覆盖率(coverage)描述一个推荐系统对物品长尾的发掘能力。覆盖率有不同的定义方法,最简单的定义为推荐系统能够推荐出来的物品占总物品集合的比例。
多样性描述了推荐列表中物品两两之间的不相似性。因此,多样性和相似性是对应的。
新颖的推荐是指给用户推荐那些他们以前没有听说过的物品。
Ch2 协同过滤(CF):通过分析用户的行为来推荐
(购买本商品的用户还购买了……)
2.1 基于用户的CF (UserCF) 原书P58
对于用户U,找与其相似的用户A,把A喜欢的推荐给U
2.1.1 计算用户间相似度 原书P62-66


改进1:建立倒排表,加速计算

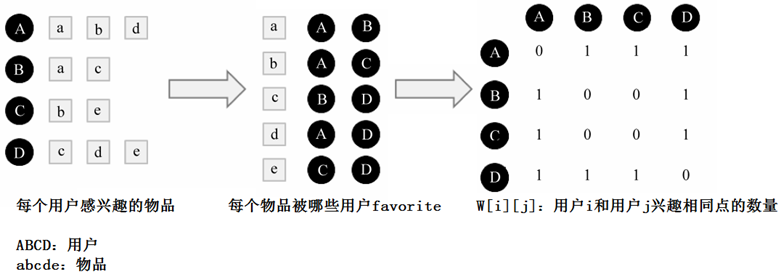
改进2:

2.1.2 UserCF算法 原书P63

2.2 基于物品的CF (ItemCF) 原书P68
用户U购买过物品A,所以可能还喜欢(与A相似的)物品B
2.2.1 UserCF存在的问题: 原书P68
基于用户的协同过滤算法在一些网站(如Digg)中得到了应用,但该算法有一些缺点。首先,随着网站的用户数目越来越大,计算用户兴趣相似度矩阵将越来越困难,其运算时间复杂度和空间复杂度的增长和用户数的增长近似于平方关系。
2.2.2 计算物品间相似度 原书P70

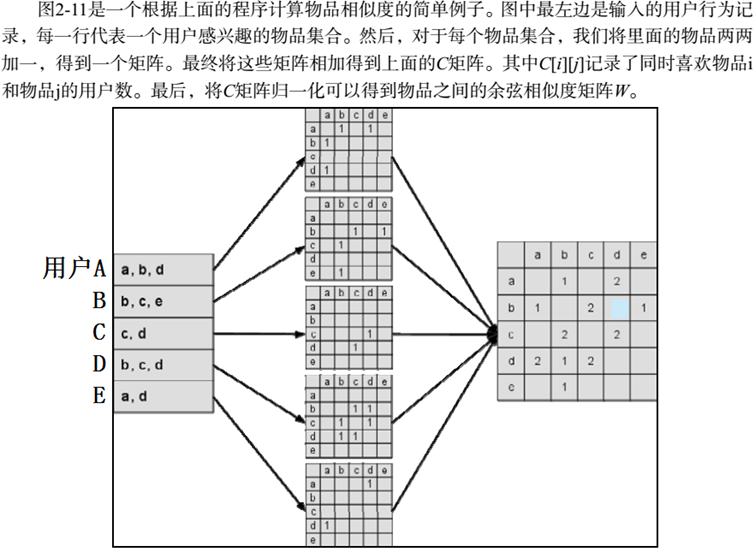
2.2.3 ItemCF 原书P70-73

2.2.4 改进: 原书P74-46
(1) 用户活跃度对物品相似度的影响:IUF

上面的公式只是对活跃用户做了一种软性的惩罚,但对于很多过于活跃的用户,比如上面那位买了当当网80%图书的用户,为了避免相似度矩阵过于稠密,我们在实际计算中一般直接忽略他的兴趣列表,而不将其纳入到相似度计算的数据集中。
(2) 归一化物品相似度
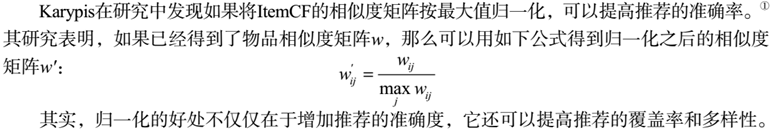
2.3 UserCF和ItemCF比较 原书P76-78
2.4 Latent Factor Model 原书P83-89
把物品归为类,先以类为单位处理用户数据/推荐,再从这一大类中找出用户喜欢的物品。
LFM重点解决对物品自动聚类的问题,通过一个trained model来进行。
问题:没有负样本如何训练?
Sol:找热门的、用户没有过行为的物品作为负样本。对于一个用户,从他没有过行为的物品中采样出一些物品作为负样本,但采样时,保证每个用户的正负样本数目相当。
Example:

2.5 Graph Based Model
(略)
Ch3推荐系统冷启动问题
解决方案:
利用用户注册信息
用户注册时填写的个人信息
选择合适的物品启动用户的兴趣
在新用户第一次访问推荐系统时,不立即给用户展示推荐结果,而是给用户提供一些物品,让用户反馈他们对这些物品的兴趣,然后根据用户反馈给提供个性化推荐。
利用物品的内容信息 原书P106-110
UserCF:利用物品的内容信息,将新物品先投放给曾经喜欢过和它内容相似的其他物品的用户。ItemCF:利用物品的内容信息计算物品相关表,并且频繁地更新相关表
话题模型:任何模型都有一个假设, LDA作为一种生成模型,对一篇文档产生的过程进行了建模。话题模型的基本思想是,一个人在写一篇文档的时候,会首先想这篇文章要讨论哪些话题,然后思考这些话题应该用什么词描述,从而最终用词写成一篇文章。因此,文章和词之间是通过话题联系的。
LDA中有3种元素,即文档、话题和词语。每一篇文档都会表现为词的集合,这称为词袋模型(bag of words)。每个词在一篇文章中属于一个话题。令D为文档集合, D[i]是第i篇文档。 w[i][j]是第i篇文档中的第j个词。 z[i][j]是第i篇文档中第j个词属于的话题。
LDA的计算过程包括初始化和迭代两部分。首先要对z进行初始化,而初始化的方法很简单,假设一共有K个话题,那么对第i篇文章中的第j个词,可以随机给它赋予一个话题。同时,用NWZ(w,z)记录词w被赋予话题z的次数, NZD(z,d)记录文档d中被赋予话题z的词的个数。
foreach document i in range(0,|D|):
foreach word j in range(0, |D(i)|):
z[i][j] = rand() % K
NZD[z[i][j], D[i]]++
NWZ[w[i][j], z[i][j]]++
NZ[z[i][j]]++
在初始化之后,要通过迭代使话题的分布收敛到一个合理的分布上去。伪代码如下所示:
while not converged:
foreach document i in range(0, |D|):
foreach word j in range(0, |D(i)|):
NWZ[w[i][j], z[i][j]]--
NZ[z[i][j]]--
NZD[z[i][j], D[i]]--
z[i][j] = SampleTopic()
NWZ[w[i][j], z[i][j]]++
NZ[z[i][j]]++
NZD[z[i][j], D[i]]++
LDA可以很好地将词组合成不同的话题。这里我们引用David M. Blei在论文中给出的一个实验结果。他利用了一个科学论文摘要的数据集,该数据集包含16 333篇新闻,共23 075个不同的单词。通过LDA,他计算出100个话题并且在论文中给出了其中4个话题排名最高(也就是p(w|z)最大)的15个词。从图3-12所示的聚类结果可以看到, LDA可以较好地对词进行聚类,找到每个词的相关词。
在使用LDA计算物品的内容相似度时,我们可以先计算出物品在话题上的分布,然后利用两个物品的话题分布计算物品的相似度。比如,如果两个物品的话题分布相似,则认为两个物品具有较高的相似度,反之则认为两个物品的相似度较低。计算分布的相似度可以利用KL散度①:
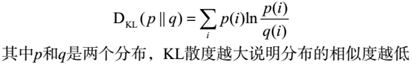
发挥专家的作用
利用专家进行标注
Ch4利用用户标签数据
GroupLens在一篇文章中表示目前流行的推荐系统基本上通过3种方式联系用户兴趣和物品。
第一种方式是利用用户喜欢过的物品,给用户推荐与他喜欢过的物品相似的物品,这就是前面提到的基于物品的算法(ItemCF)。
第二种方式是利用和用户兴趣相似的其他用户,给用户推荐那些和他们兴趣爱好相似的其他用户喜欢的物品,这是前面提到的基于用户的算法(UserCF)。
第三种重要的方式是通过一些特征(feature)联系用户和物品,给用户推荐那些具有用户喜欢的特征的物品。这里的特征有不同的表现方式,比如可以表现为物品的属性集合(比如对于图书,属性集合包括作者、出版社、主题和关键词等),也可以表现为隐语义向量(latent factor vector),这可以通过前面提出的隐语义模型习得到。
本章将讨论一种重要的特征表现方式——标签
UGC(User Generated Content):让普通用户给物品打标签。 UGC的标签系统是一种表示用户兴趣和物品语义的重要方式。当一个用户对一个物品打上一个标签,这个标签一方面描述了用户的兴趣,另一方面则表示了物品的语义,从而将用户和物品联系了起来。
4.1用户标签介绍 原书P117-119
(略)
4.2 基于标签的推荐系统
用(u,i,b)表示一个用户打标签的行为
4.2.1 评价指标 原书P121-122
Precision 准确率
Recall 召回率
Coverage 覆盖率
Diversity 多样性
Average Popularity 平均热门程度(新颖性)
4.2.2 推荐算法 原书P123-127
(1) 基本算法

(2)改进:Tag Based TFIDF
解决因为推荐了大量热门item,导致新颖性降低的问题
(3)改进:标签扩展
针对打过的tag还很少的新用户
(4)改进:标签清理
清理重复/无用的tag
(5)改进:Graph Based Model
(略)
4.3 给用户推荐标签 原书P132-133
给用户提供几个备选的tag,协助用户给物品打标签。
Ch5 利用上下文信息
上下文:用户所处的时间/地点/……
5.1 时间效应 原书P144
实时性:用户兴趣是不断变化的,其变化体现在用户不断增加的新行为中。一个实时的推荐系统需要能够实时响应用户新的行为,让推荐列表不断变化,从而满足用户不断变化的兴趣。
实现推荐系统的实时性除了对用户行为的存取有实时性要求,还要求推荐算法本身具有实时性,而推荐算法本身的实时性意味着:
实时推荐系统不能每天都给所有用户离线计算推荐结果,然后在线展示昨天计算出来的结果。所以,要求在每个用户访问推荐系统时,都根据用户这个时间点前的行为实时计算推荐列表。
推荐算法需要平衡考虑用户的近期行为和长期行为,即要让推荐列表反应出用户近期行为所体现的兴趣变化,又不能让推荐列表完全受用户近期行为的影响,要保证推荐列表对用户兴趣预测的延续性。
5.2 时间上下文推荐算法 原书P147-153
最近最热门

时间上下文相关的ItemCF算法
基于物品(item-based)的个性化推荐算法是商用推荐系统中应用最广泛的,该算法由两个核心部分构成:
利用用户行为离线计算物品之间的相似度;
根据用户的历史行为和物品相似度矩阵,给用户做在线个性化推荐。
时间信息在上面两个核心部分中都有重要的应用,这体现在两种时间效应上:
物品相似度:用户在相隔很短的时间内喜欢的物品具有更高相似度。以电影推荐为例,用户今天看的电影和用户昨天看的电影其相似度在统计意义上应该大于用户今天看的电
影和用户一年前看的电影的相似度。
在线推荐:用户近期行为相比用户很久之前的行为,更能体现用户现在的兴趣。因此在预测用户现在的兴趣时,应该加重用户近期行为的权重,优先给用户推荐那些和他近期
喜欢的物品相似的物品。
时间上下文相关的UserCF算法
和ItemCF算法一样, UserCF算法同样可以利用时间信息提高预测的准确率。首先,回顾一下前面关于UserCF算法的基本思想:给用户推荐和他兴趣相似的其他用户喜欢的物品。从这个基本思想出发,我们可以在以下两个方面利用时间信息改进UserCF算法。
1.用户兴趣相似度:在第3章的定义中我们知道,两个用户兴趣相似是因为他们喜欢相同的物品,或者对相同的物品产生过行为。但是,如果两个用户同时喜欢相同的物品,那么这两个用户应该有更大的兴趣相似度。比如用户A在2006年对C++感兴趣,在2007年对Java感兴趣,用户B在2006年对Java感兴趣, 2007年对C++感兴趣,而用户C和A一样,在2006年对C++感兴趣,在2007年对Java感兴趣。那么,根据第3章的定义,用户A和用户B的兴趣相似度等于用户A和用户C的兴趣相似度。但显然,在实际世界,我们会认为用户A和C的兴趣相似度要大于用户A和B。
2.相似兴趣用户的最近行为:在找到和当前用户u兴趣相似的一组用户后,这组用户最近的兴趣显然相比这组用户很久之前的兴趣更加接近用户u今天的兴趣。也就是说,我们应该给用户推荐和他兴趣相似的用户最近喜欢的物品。在新闻推荐系统中,时间信息在UserCF中的作用非常明显。假设我们今天要给一个NBA篮球迷推荐新闻。首先,我们需要找到一批和他一样的NBA迷,然后找到这批人在当前时刻最近阅读最多的新闻推荐给当前用户,而不是把这批人去年阅读的新闻推荐给当前用户,因为他们去年阅读最多的新闻在现在看显然过期了。
时间段图模型
(略)
Ch6 利用社交网络数据
原书P165
社交网络定义了用户之间的联系,因此可以用图定义社交网络。我们用图G(V,E,w)定义一个社交网络,其中V是顶点集合,每个顶点代表一个用户, E是边集合,如果用户va和vb有社交网络关系,那么就有一条边e(va ,vb)连接这两个用户,而w(va, vb)定义了边的权重。
对图G中的用户顶点u,定义out(u)为顶点u指向的顶点集合(如果套用微博中的术语,out(u)就是用户u关注的用户集合),定义in(u)为指向顶点u的顶点集合(也就是关注用户u的用户集合)。那么,在Facebook这种无向社交网络中显然有out(u)=in(u)。
6.1 推荐算法
基于邻域的社会化推荐算法 原书P168
给用户推荐自己好友喜欢的物品集合
基于图的社会化推荐算法 原书P170
(略)
实际系统中的社会化推荐算法 原书P171
Twitter的解决方案是给每个用户维护一个消息队列(message queue),当一个用户发表一条微博时,所有关注他的用户的消息队列中都会加入这条微博。这个实现的优点是用户获取信息墙时可以直接读消息队列,所以终端用户的读操作很快。不过这个实现也有缺点,当一个用户发表了一条微博,就会触发很多写操作,因为要更新所有关注他的用户的消息队列,特别是当一个人被很多人关注时,就会有大量的写操作。 Twitter通过大量的缓存解决了这一问题。具体的细节可以参考InfoQ对Twitter架构的介绍①。
如果将Twitter的架构搬到社会化推荐系统中,我们就可以按照如下方式设计系统:
首先,为每个用户维护一个消息队列,用于存储他的推荐列表;
当一个用户喜欢一个物品时,就将(物品ID、用户ID和时间)这条记录写入关注该用户的推荐列表消息队列中;
当用户访问推荐系统时,读出他的推荐列表消息队列,对于这个消息队列中的每个物品,重新计算该物品的权重。计算权重时需要考虑物品在队列中出现的次数,物品对应的用户和当前用户的熟悉程度、物品的时间戳。同时,计算出每个物品被哪些好友喜欢过,用这些好友作为物品的推荐解释。
社会化推荐系统和协同过滤推荐系统
(略)
信息流推荐 原书P174
(略)
6.2 给用户推荐好友 原书P178
基于内容的匹配
推荐用户属性相似的
基于共同兴趣的好友推荐
推荐兴趣相同的,用UserCF
基于社交网络图的好友推荐
(略)
Ch7实例
7.1 推荐系统架构
一般来说,每个网站都会有一个UI系统, UI系统负责给用户展示网页并和用户交互。网站会通过日志系统将用户在UI上的各种各样的行为记录到用户行为日志中。日志可能存储在内存缓存里,也可能存储在数据库中,也可能存储在文件系统中。而推荐系统通过分析用户的行为日志,给用户生成推荐列表,最终展示到网站的界面上。
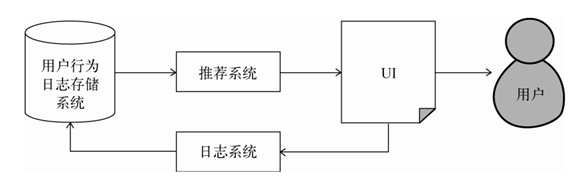
推荐系统需要由多个推荐引擎组成,每个推荐引擎负责一类特征和一种任务(每一个推荐引擎其实代表了一种推荐策略),而推荐系统的任务只是将推荐引擎的结果按照一定权重或者优先级合并、排序然后返回。
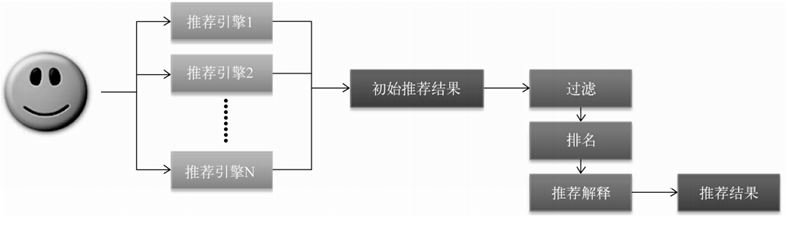
7.2 推荐引擎架构
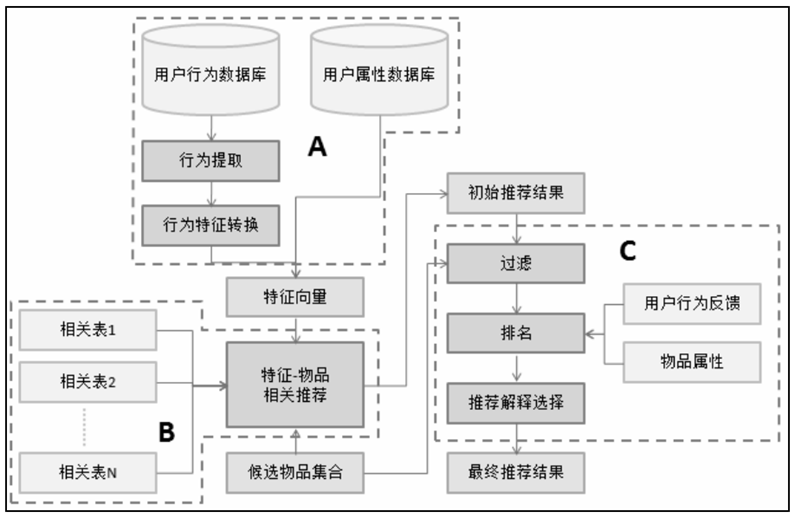
A. 该部分负责从数据库或者缓存中拿到用户行为数据,通过分析不同行为,生成当前用户的特征向量。不过如果是使用非行为特征,就不需要使用行为提取和分析模块了。该模块的输出是用户特征向量。
B. 该部分负责将用户的特征向量通过特征-物品相关矩阵转化为初始推荐物品列表。
在得到用户的特征向量后,我们可以根据离线的相关表得到初始的物品推荐列表。
离线相关表可以存储在MySQL中。对于每个特征,离线相关表中存储和它最相关的N个物品的ID。
C. 该部分负责对初始的推荐列表进行过滤、排名等处理,从而生成最终的推荐结果
在得到初步的推荐列表后,还不能把这个列表展现给用户,首先需要按照产品需求对结果进行过滤,过滤掉那些不符合要求的物品。
经过过滤后的推荐结果直接展示给用户一般也没有问题,但如果对它们进行一些排名(考虑新颖性、多样性等等),则可以更好地提升用户满意度.
Ch8评分预测问题
评分预测问题最基本的数据集就是用户评分数据集。该数据集由用户评分记录组成,每一条评分记录是一个三元组(u,i, r),表示用户u给物品i赋予了评分r,用 r[u][i] 表示用户u对物品i的评分。因为用户不可能对所有物品都评分,因此评分预测问题就是如何通过已知的用户历史评分记录预测未知的用户评分记录。