网络爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。网络蜘蛛是通过网页的链接地址来寻找网页,从网站某一个页面(通常是首页)开始,读取
网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整
个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。所以要想抓取网络上的数据,不仅需要爬虫程序还需要一个可以接
受”爬虫“发回的数据并进行处理过滤的服务器,爬虫抓取的数据量越大,对服务器的性能要求则越高。
1 聚焦爬虫工作原理以及关键技术概述
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上
的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析
算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上
述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚
焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。

相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:
(1) 对抓取目标的描述或定义;
(2) 对网页或数据的分析与过滤;
(3) 对URL的搜索策略。
分类
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web Crawler)、
增量式网络爬虫(Incremental Web Crawler)、深层网络爬虫(Deep Web Crawler)。 实际的网络爬虫系统通常是几种爬虫技术相结合实现的。
网络爬虫的实现原理根据这种原理,写一个简单的网络爬虫程序 ,该程序实现的功能是获取网站发回的数据,并提取之中的网址,获取的网址我们存放在一个文件夹中,关于如何就从网
站获取的网址进一步循环下去获取数据并提取其中其他数据这里就不在写了,只是模拟最简单的一个原理则可以,实际的网站爬虫远比这里复杂多,深入讨论就太多
了。除了提取网址,我们还可以提取其他各种我们想要的信息,只要修改过滤数据的表达式则可以。以下是利用Java模拟的一个程序,提取新浪页面上的链接,存放
在一个文件里
源代码如下
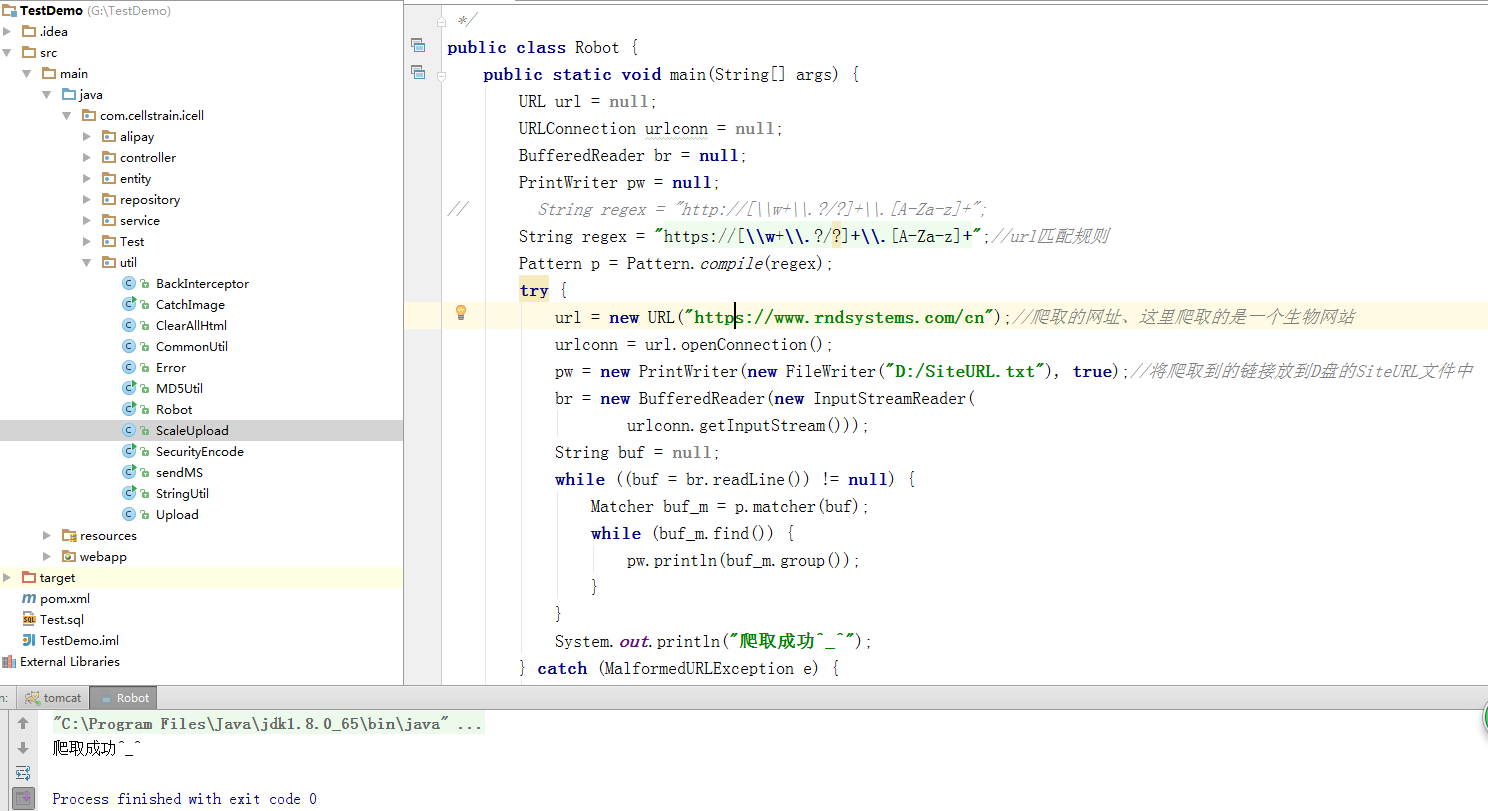
package com.cellstrain.icell.util;在idea的运行结果如下:
import java.io.*;
import java.net.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* java实现爬虫
*/
public class Robot {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
// String regex = "http://[\w+\.?/?]+\.[A-Za-z]+";
String regex = "https://[\w+\.?/?]+\.[A-Za-z]+";//url匹配规则
Pattern p = Pattern.compile(regex);
try {
url = new URL("https://www.rndsystems.com/cn");//爬取的网址、这里爬取的是一个生物网站
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
看一下D盘有没有SiteURL.txt文件

已经成功生成SiteURL文件,打开可以看到里面都是抓取到的url

以上就是一个简单的java爬取网站的url实例,希望能够帮到你哦