# 717 1比特与2比特字符:判断末尾符号是哪一种
思路:线性从前向后遍历,维护一个映射list。


class Solution: def isOneBitCharacter(self, bits: List[int]) -> bool: if len(bits)==1: return True else: mapList=[] while len(bits)>0: if bits[0]==1: mapList.append('F') bits.pop(0) bits.pop(0) else: mapList.append('T') bits.pop(0) if mapList[-1]=='T': return True else: return False
# 67 二进制求和:二进制加法
思路:首先处理字符串长度不一致的问题,为较短的字符串前面添0,将两个字符串补齐。然后从后往前加即可,当前位置上的两个数+进位。
class Solution: def addZero(self,a,b): diff=abs(len(b)-len(a)) if len(a)<len(b): a='0'*diff+a elif len(a)>len(b): b = '0' * diff + b return a,b def addBinary(self, a: str, b: str) -> str: result='' a,b=self.addZero(a,b) flag=0 # 进位 for i in range(len(a)): tmp=int(a[len(a)-i-1])+int(b[len(b)-i-1])+flag if tmp==2: flag=1 result+='0' elif tmp==3: flag = 1 result += '1' else: flag=0 result += str(tmp) if flag==1: result += '1' back=''.join(list(reversed(result))) return back
# 415: 67的升级版, replace if-else with //(整除) and %(取余)
class Solution: def addZero(self,a,b): diff=abs(len(b)-len(a)) if len(a)<len(b): a='0'*diff+a elif len(a)>len(b): b = '0' * diff + b return a,b def addStrings(self, num1: str, num2: str) -> str: result='' a,b=self.addZero(num1,num2) flag=0 # 进位 for i in range(len(a)): tmp=int(a[len(a)-i-1])+int(b[len(b)-i-1])+flag result+=str(tmp%10) # 10进制数 flag=tmp//10 if flag!=0: #由于题目要求字符串前面不能有0,所以只有非0才添加 result += str(flag) back=''.join(list(reversed(result))) return back
### 从这道题开始,我就不按照LC官网类的方式记录了,直接贴函数代码>>_<<
# 107: DFS+维护一个以深度为key的字典, value是一个list, 在DFS时依次append, 最后按照key从大到小返回对应value(主要难点在于DFS的实现,DFS的实现方式主要有两种,一种是递归,一种是栈,这里采用递归的实现方式)
# Definition for a binary tree node. class TreeNode: def __init__(self, x): self.val = x self.left = None self.right = None def DFS(root,depth,depthDict): if root!=None: if depth not in depthDict.keys(): depthDict[depth]=[] depthDict[depth].append(root.val) else: depthDict[depth].append(root.val) DFS(root.left,depth+1,depthDict) DFS(root.right, depth+1, depthDict) else: return def levelOrderBottom(root): # root: TreeNode res=[] depthDict={} depth=0 DFS(root,depth,depthDict) keysSort=list(reversed(sorted(list(depthDict.keys())))) for i in keysSort: res.append(depthDict[i]) return res # Test sample rr=TreeNode(3) rr.left=TreeNode(9) rr.right=TreeNode(20) rr.right.left=TreeNode(15) rr.right.right=TreeNode(7) print(levelOrderBottom(rr))
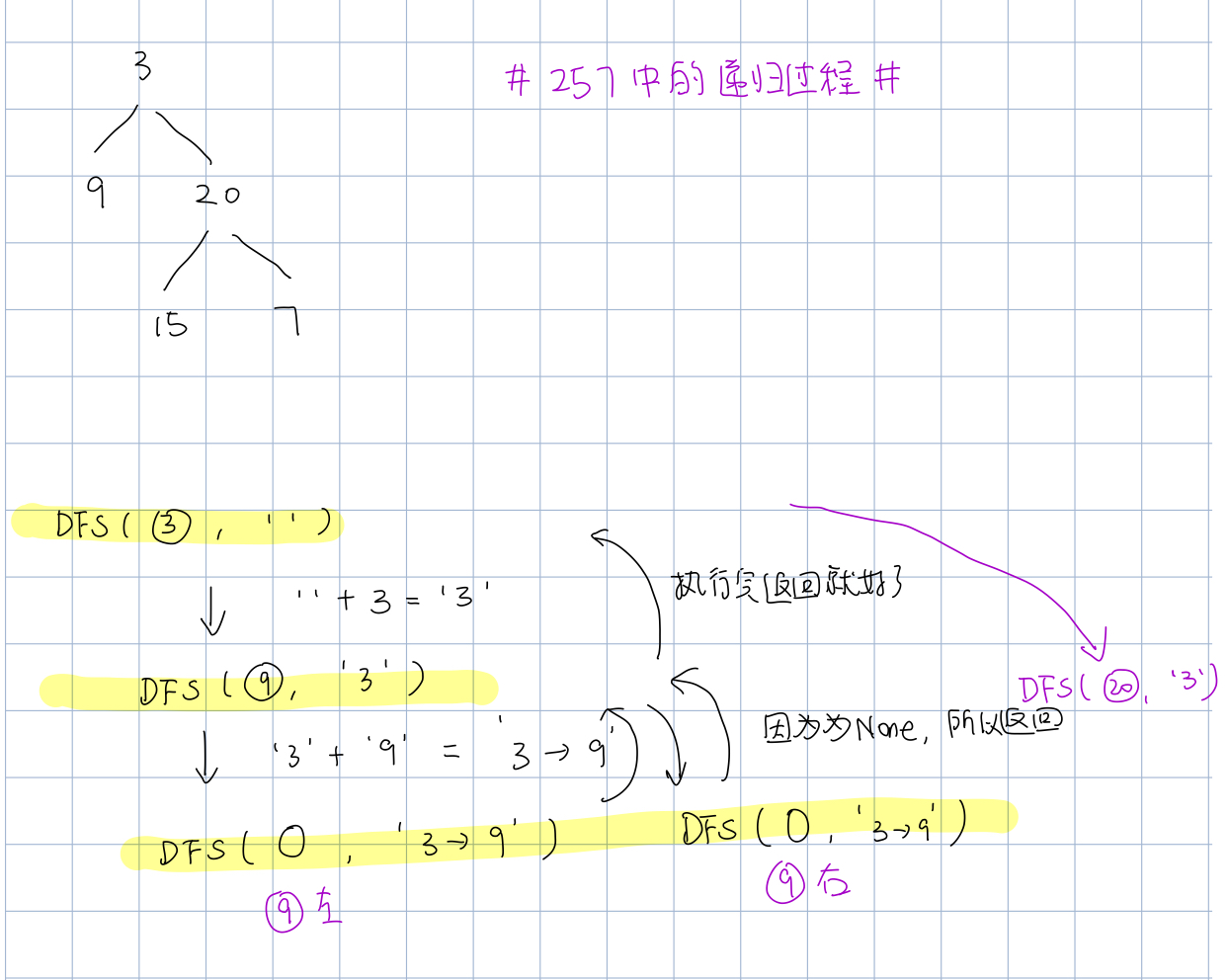
# 257: DFS (这两道二叉树的题目做起来都有点困难,可能因为对递归理解还不是非常透彻,这里关键在于递归的过程中path会被自动维护)
# Use the definition for a binary tree node in 107. def binaryTreePaths(root): # List[str] Paths=[] Path='' def DFS_257(root, path): if root != None: if path == '': path += str(root.val) else: path += ('->' + str(root.val)) if root.left==None and root.right==None: Paths.append(path) DFS_257(root.left, path) DFS_257(root.right, path) else: return DFS_257(root,Path) return Paths # Test sample # rr=TreeNode(3) # rr.left=TreeNode(9) # rr.right=TreeNode(20) # rr.right.left=TreeNode(15) # rr.right.right=TreeNode(7) # print(binaryTreePaths(rr))
这里补充一下递归分析:
# 70: DP (乍一看以为这道题就是求二叉树的路径条数,以为可以使用DFS,然递归DFS超时==), 用DP的话首先需要写出通项公式,这里假设f(x)是爬x阶楼梯的方案数,而最后一步可以走1步或者2步,我们可以得到f(x)=f(x-1)+f(x-2),这个比较难想,竟然是斐波那契数。
def climbStairs(n): # DP l=0 r=1 sum=0 for i in range(n): sum=l+r l=r r=sum return r
(有关通项的理解后续再补充)
# 30: 外观数列, 这道题的解法写的比较任意,就是线性扫描+集合判断,更加规范的应该用双指针。
线性扫描+集合
def count(num): str_num=str(num) descriptor='' filter_set=[] for i in str_num: filter_set.append(i) if len(set(filter_set))==2: descriptor+=(str(len(filter_set[:-1]))+filter_set[-2]) filter_set = [filter_set[-1]] else: continue descriptor+=(str(len(filter_set))+str(filter_set[-1])) return int(descriptor) def countAndSay(n): res=1 for i in range(n-1): res=count(res) return str(res) print(countAndSay(5))
# 204 数质数,该题用常规方法去判断会超时,尝试加了很多trick还是会超时,最后参考了其他人的题解,采用了埃氏筛的方法,主要是对该方法的理解(算法实现)。
def countPrimes(n): # 埃氏筛 isPrime=[1]*n # 初始化很重要 cnt=0 for i in range(2,n): if isPrime[i]: cnt+=1 for j in range(i*i,n,i): isPrime[j]=0 return cnt
# 706 自己实现一个hash表,也就是python中的字典。解决两个问题,第一,哈希函数,第二,哈希碰撞。1,采用取模长%len;2,用一个数组把映射在同一位置的元素装起来,所以是两个数组的嵌套。(这里将第一个数组的长度设置为2069,参考解答的设置,any质数都可以,减小碰撞概率而已)
class MyHashMap: def __init__(self): self.map=[[]]*2069 # 2069 as a prime def put(self, key: int, value: int) -> None: index=key%2069 for lst in self.map[index]: if lst[0]==key: lst[1]=value return None self.map[index].append([key,value]) def get(self, key: int) -> int: index=key%2069 for lst in self.map[index]: if lst[0]==key: return lst[1] return -1 def remove(self, key: int) -> None: index = key % 2069 for i in range(len(self.map[index])): if self.map[index][i][0] == key: del self.map[index][i] break # 要加break,不然会有错,因为这种for iterator删除当前元素继续访问会造成冲突
# 509 斐波那契数(70题的本质)
def fib(n): if n==0: return 0 else: l = 0 r = 1 sum = 0 for i in range(n - 1): sum = l + r l = r r = sum return r
# 724 找中心索引使得左右两边和相等, 题目也比较好理解,我直接用了sum函数判断,发现两个有意思的点: sum([])=0 ; list[:0]=[] list[len(list):]=[] 第二个点说明切片不会造成越界问题,比如这样:
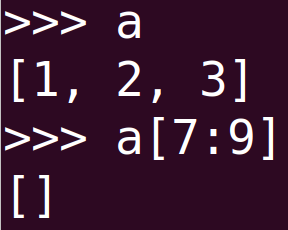
def pivotIndex(nums): for i in range(len(nums)): if sum(nums[:i])==sum(nums[(i+1):]): return i return -1
# 387 字符串中的唯一字符,该题目比较简单,不多分析,就用字典存储频数即可。
def firstUniqChar(s): uniqueCharList=[] times={} for i in s: if i not in uniqueCharList: uniqueCharList.append(i) times[i]=1 else: times[i]+=1 print(uniqueCharList) print(times) for key in times.keys(): if times[key]==1: return s.index(key) return -1
# 198: 数组中不相邻元素的最大和,使用动态规划,经典步骤,建立函数关系f(x),写出子结构表达式。本题目分析如下 (代码部分参考精选题解):

def rob(nums): if len(nums)==0: return 0 elif len(nums)==1: return nums[0] else: N=len(nums) dp=[0]*(N+1) dp[0]=0 dp[1]=nums[0] for i in range(2,N+1): dp[i]=max(dp[i-1],dp[i-2]+nums[i-1]) return dp[N]
# 232 用两个栈模拟队列,一个栈作为输入栈,一个栈作为输出栈,push的时候都加入输入栈,pop从输出栈弹出,此时如果为空就需要将输入栈的全部弹出到输出栈再输出。(相当于将一个队列拆成了两部分,入栈和出栈)
这个video很清晰==
class MyQueue: def __init__(self): """ Initialize your data structure here. """ self.inputStack=[] self.outputStack=[] def push(self, x: int) -> None: """ Push element x to the back of queue. """ self.inputStack.append(x) def pop(self) -> int: """ Removes the element from in front of queue and returns that element. """ if len(self.outputStack)!=0: value=self.outputStack.pop() return value else: for i in range(len(self.inputStack)): self.outputStack.append(self.inputStack.pop()) value = self.outputStack.pop() return value def peek(self) -> int: """ Get the front element. """ if len(self.outputStack)!=0: value=self.outputStack[-1] return value else: for i in range(len(self.inputStack)): self.outputStack.append(self.inputStack.pop()) value = self.outputStack[-1] return value def empty(self) -> bool: """ Returns whether the queue is empty. """ if len(self.inputStack)==0 and len(self.outputStack)==0: return True else: return False
# 225 用两个队列模拟栈:核心思想就是将一个队列辅以某些操作直接变成栈的存储结构(元素取反存储)。实现:一个队列+一个tmp队列
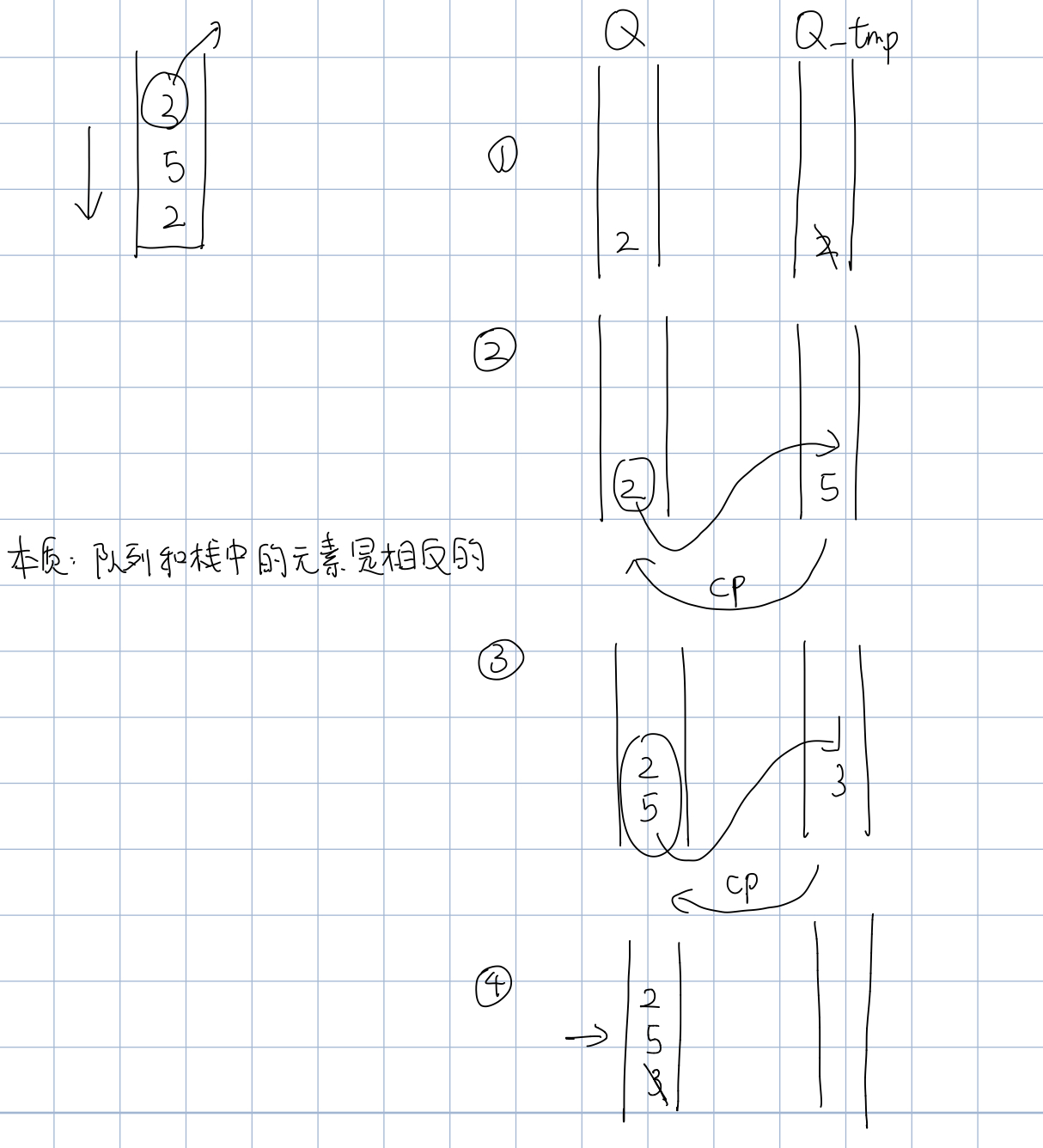
class MyStack: def __init__(self): """ Initialize your data structure here. """ self.Q=[] self.Q_tmp=[] def push(self, x: int) -> None: """ Push element x onto stack. """ self.Q_tmp=[] self.Q_tmp.append(x) if len(self.Q)!=0: for i in range(len(self.Q)): self.Q_tmp.append(self.Q[i]) self.Q=self.Q_tmp def pop(self) -> int: """ Removes the element on top of the stack and returns that element. """ res=self.Q[0] self.Q=self.Q[1:] return res def top(self) -> int: """ Get the top element. """ return self.Q[0] def empty(self) -> bool: """ Returns whether the stack is empty. """ if len(self.Q)==0: return True else: return False
# 28 查找子字符串出现的位置
def strStr(haystack, needle): if needle=='' or needle==haystack: return 0 elif len(needle)>len(haystack): return -1 else: # needle 长度小于hay for i in range(len(haystack)): if i+len(needle)<=len(haystack): if haystack[i:i+len(needle)]==needle: return i else: if i + len(needle) == len(haystack): # 考虑最后一次不匹配的情况 return -1 continue else: return -1
写的太复杂了==按照相同的思路可以用一行代码实现(for start in range(n - L + 1):)or 还可以采用基于hash的方法,将字符串映射到hash,如Rabin Karp
# 349 两个数组的交集(就遍历...)
def intersection(nums1, nums2): intersect=[] for i in nums1: if (i in nums2) and (i not in intersect): intersect.append(i) return intersect
# 784 字母大小写全排列。这个题目关键是抓住全排列和二进制数之间的关系。
def letterCasePermutation(S): L=[] letterIndex=[] idx=-1 str=S # store numbers in S and reserve space for character for i in S: # 数字 idx+=1 if i>='0' and i<='9': L.append(i) else: # 字母 letterIndex.append(idx) L.append([i.lower(),i.upper()]) if len(letterIndex)==0: # 没有字母 return [S] else: # 有字母 # 全排列等价于二进制数 sortArray = [] for i in range(2 ** len(letterIndex)): tmp = bin(i)[2:] while len(tmp) < len(letterIndex): tmp = '0' + tmp sortArray.append(tmp) res = [] for sort in sortArray: for ith in range(len(sort)): str = list(str) str[letterIndex[ith]] = L[letterIndex[ith]][int(sort[ith])] str = ''.join(str) res.append(str) return res
(代码写的太不算法了,完全是拿数学和规律来解==,标准做法应该是构建一棵树,用递归来做)
# 14 最长公共前缀:思路是先选取一个最短的字符串,然后与其他的进行比较,将模板字符串从长到短比较。
def longestCommonPrefix(strs): minl=201 mintemplate='' for i in strs: # 取最短的字符串作为模板来匹配其他的 if len(i)<minl: minl=len(i) mintemplate=i for i in reversed(range(minl)): TrueFalseSet=set() for j in range(len(strs)): TrueFalseSet.add(mintemplate[:i+1]==strs[j][:i+1]) if len(TrueFalseSet)==1 and list(TrueFalseSet)[0]==True: return mintemplate[:i+1] else: continue return ''
Follow this repo, update this blog continuously. 1.28 暂时停更,准备开始按类型刷。