Python全栈开发/人工智能公开课_腾讯课堂
https://ke.qq.com/course/190378
https://github.com/haoran119/ke.qq.com.python/tree/master/src/python-fullstack
Python — 爬虫、数据分析
python — 数据分析之旅,Numpy
- 数据获取
- 公开数据集(Mnist),爬虫
- 数据存储
- 数据库SQL
- 数据预处理
- 噪声,重复,缺失,空值,异常值,分组,合并,随机取样(pandas)
- 数据建模、分析
- 找一个合适的模型,统计学,概率论,机器学习,聚类,回归(sklearn)
- 数据可视化
- matplotlib


1 # coding: utf-8 2 3 # In[1]: 4 5 6 import numpy as np 7 8 9 # In[2]: 10 11 12 # 创建数组 13 14 list1 = [ 1, 3, 5, -2, 0, -9 ] 15 list2 = [ 2, 4, -3, -7, 1, -7 ] 16 list3 = [ [2, 5, 0], [11, 3, 4] ] 17 list4 = [ [3, -1, 8], [9, -3, 9] ] 18 19 20 # In[3]: 21 22 23 arr1 = np.array( list1 ) 24 25 #[ 1 3 5 -2 0 -9] 26 print(arr1) 27 28 29 # In[4]: 30 31 32 arr4 = np.array( list3 ) 33 34 #[[ 2 5 0] 35 # [11 3 4]] 36 print(arr4) 37 38 39 # In[5]: 40 41 42 arr2 = np.arange( 1, 10, 2 ) 43 44 #[1 3 5 7 9] 45 print(arr2) 46 47 48 # In[6]: 49 50 51 arr3 = np.linspace( 1, 10, 4 ) 52 53 #[ 1. 4. 7. 10.] 54 print(arr3) 55 56 57 # In[7]: 58 59 60 arr_zero = np.zeros( (3, 4)) # zeros参数是元组() 61 62 #[[0. 0. 0. 0.] 63 # [0. 0. 0. 0.] 64 # [0. 0. 0. 0.]] 65 print(arr_zero) 66 67 68 # In[8]: 69 70 71 arr_one = np.ones( (3, 3) ) 72 73 #[[1. 1. 1.] 74 # [1. 1. 1.] 75 # [1. 1. 1.]] 76 #[[100. 100. 100.] 77 # [100. 100. 100.] 78 # [100. 100. 100.]] 79 print(arr_one) 80 print(arr_one * 100) 81 82 83 # In[9]: 84 85 86 arr_eye = np.eye( 4, 4 ) # 对角线上元素为1,其他为0 87 88 #[[1. 0. 0. 0.] 89 # [0. 1. 0. 0.] 90 # [0. 0. 1. 0.] 91 # [0. 0. 0. 1.]] 92 print(arr_eye) 93 94 95 # In[10]: 96 97 98 arr_eye2 = np.eye( 4, 5 ) 99 100 #[[1. 0. 0. 0. 0.] 101 # [0. 1. 0. 0. 0.] 102 # [0. 0. 1. 0. 0.] 103 # [0. 0. 0. 1. 0.]] 104 print(arr_eye2) 105 106 107 # In[11]: 108 109 110 # 数组的索引和切片 111 112 #[ 5 -2 0] 113 #[[3 4]] 114 print(arr1[2:5]) # 左闭右开 115 print(arr4[1:2, 1:3]) 116 117 118 # In[12]: 119 120 121 # 通用的函数 122 123 #sqrt : 124 # [[1.41421356 2.23606798 0. ] 125 # [3.31662479 1.73205081 2. ]] 126 #exp : 127 # [[7.38905610e+00 1.48413159e+02 1.00000000e+00] 128 # [5.98741417e+04 2.00855369e+01 5.45981500e+01]] 129 print("sqrt : ", np.sqrt(arr4)) 130 print("exp : ", np.exp(arr4)) 131 132 133 # In[13]: 134 135 136 arr2 = np.array( list2 ) 137 new_arr = np.maximum( arr1, arr2 ) 138 139 #[ 2 4 5 -2 1 -7] 140 print(new_arr) 141 142 143 # In[14]: 144 145 146 # ReLU >0 保留原值,<0 取0 147 new_arr = np.maximum(0, arr1) 148 149 #[1 3 5 0 0 0] 150 print(new_arr) 151 152 153 # In[15]: 154 155 #(array([[0.41421356, 0.23606798, 0. ], 156 # [0.31662479, 0.73205081, 0. ]]), array([[1., 2., 0.], 157 # [3., 1., 2.]])) 158 print( np.modf( np.sqrt( arr4 ) ) ) # 把整数部分和小数部分,生成两个独立的数组 159 160 161 # In[16]: 162 163 164 new_arr1 = np.where( arr2>0, 'True', 'False' ) # if condition: x, y 165 166 #['True' 'True' 'False' 'False' 'True' 'False'] 167 print(new_arr1) 168 169 170 # In[17]: 171 172 #[-7 -3 1 2 4] 173 #[ 0 2 3 4 5 11] 174 print( np.unique( arr2 ) ) 175 print( np.unique( arr4 ) ) 176 177 178 # In[18]: 179 180 181 # 数组作为文件来输入和输出 182 183 np.save( 'myarr', arr2 ) # 把数组保存为文件 .npy 184 185 186 # In[19]: 187 188 189 new_arr2 = np.load( 'myarr.npy' ) 190 191 #[ 2 4 -3 -7 1 -7] 192 print(new_arr2) 193 194 195 # In[20]: 196 197 198 np.savez( 'myarrzip', a1=arr1, a2=arr2, a3=arr3 ) 199 arr = np.load( 'myarrzip.npz' ) 200 201 #[ 1 3 5 -2 0 -9] 202 print(arr['a1']) 203 204 205 # In[21]: 206 207 208 # 线性代数 矩阵 209 # 矩阵的合并 210 211 arr5 = np.array( list3 ) 212 arr6 = np.array( list4 ) 213 214 #[[ 2 5 0 3 -1 8] 215 # [11 3 4 9 -3 9]] 216 #[[ 2 5 0] 217 # [11 3 4] 218 # [ 3 -1 8] 219 # [ 9 -3 9]] 220 print( np.hstack( [arr5, arr6] ) ) 221 print( np.vstack( [arr5, arr6] ) ) 222 223 224 # In[22]: 225 226 227 # 点乘 228 229 arr6 = np.array( list4 ).reshape( 3, 2 ) 230 231 #[[ 3 -1] 232 # [ 8 9] 233 # [-3 9]] 234 #[[ -5 12 -4] 235 # [115 67 36] 236 # [ 93 12 36]] 237 print( arr6 ) 238 print( arr6.dot( arr5 ) ) 239 240 241 # In[23]: 242 243 #[[ 3 8 -3] 244 # [-1 9 9]] 245 print( np.transpose(arr6) ) # 转置
python — 数据分析之旅,pandas
- 数据处理
- 不干净的数据
- 干净数据,随机采样
- 表格数据
- 时间序列数据
- 矩阵数据
- 观测数据
- 统计数据
- 数据清洗
- 空值(缺失值)
- pandas常用操作
- 大小可变
- 数据自动对齐
- Series(一维),Dataframe(二维)
- 分组的功能
- Numpy
- 切片,索引
- 列表和字符串
- 数据集的形状
1 # coding: utf-8 2 3 # In[1]: 4 5 6 import pandas as pd 7 import numpy as np 8 9 10 # In[2]: 11 12 13 data = pd.DataFrame(pd.read_excel('originalData.xlsx')) 14 15 # date hour pressure wind_direction temperature 16 #0 2016-07-01 0.0 1000.4 225.0 26.4 17 #1 2016-07-01 NaN NaN NaN NaN 18 #2 2016-07-01 6.0 998.9 212.0 31.7 19 #3 2016-07-01 235.0 998.7 244.0 NaN 20 #4 2016-07-01 12.0 999.7 222.0 NaN 21 #5 2016-07-01 15.0 1000.0 102.0 NaN 22 #6 2016-07-01 NaN 998.8 202.0 26.0 23 #7 2016-07-01 NaN 1000.2 334.0 25.5 24 #8 2016-07-01 NaN 1000.2 334.0 25.5 25 #9 2016-07-02 3.0 1002.4 46.0 30.0 26 #10 2016-07-02 6.0 1001.3 37.0 29.3 27 #11 2016-07-02 9.0 1001.9 345.0 25.9 28 #12 2016-07-02 12.0 1003.6 113.0 25.1 29 #13 2016-07-02 12.0 1003.6 113.0 25.1 30 #14 2016-07-02 15.0 1002.4 138.0 25.3 31 # hour pressure wind_direction temperature 32 #count 11.000000 14.000000 14.000000 11.000000 33 #mean 29.545455 1000.864286 190.500000 26.890909 34 #std 68.313049 1.685963 102.932951 2.311473 35 #min 0.000000 998.700000 37.000000 25.100000 36 #25% 6.000000 999.775000 113.000000 25.400000 37 #50% 12.000000 1000.300000 207.000000 25.900000 38 #75% 13.500000 1002.275000 239.250000 27.850000 39 #max 235.000000 1003.600000 345.000000 31.700000 40 print(data) 41 print(data.describe()) 42 43 44 # In[3]: 45 46 #RangeIndex(start=0, stop=15, step=1) 47 #Index(['date', 'hour', 'pressure', 'wind_direction', 'temperature'], dtype='object') 48 print(data.index) 49 print(data.columns) 50 51 52 # In[4]: 53 54 # date hour pressure wind_direction temperature 55 #0 2016-07-01 0.0 1000.4 225.0 26.4 56 #1 2016-07-01 NaN NaN NaN NaN 57 #2 2016-07-01 6.0 998.9 212.0 31.7 58 #3 2016-07-01 235.0 998.7 244.0 NaN 59 #4 2016-07-01 12.0 999.7 222.0 NaN 60 #5 2016-07-01 15.0 1000.0 102.0 NaN 61 # date hour pressure wind_direction temperature 62 #9 2016-07-02 3.0 1002.4 46.0 30.0 63 #10 2016-07-02 6.0 1001.3 37.0 29.3 64 #11 2016-07-02 9.0 1001.9 345.0 25.9 65 #12 2016-07-02 12.0 1003.6 113.0 25.1 66 #13 2016-07-02 12.0 1003.6 113.0 25.1 67 #14 2016-07-02 15.0 1002.4 138.0 25.3 68 print(data.head(6)) 69 print(data.tail(6)) 70 71 72 # In[5]: 73 74 75 # 1. 删掉空白值超过3的行 76 data.dropna(axis=0, thresh=3, inplace=True) 77 data.reset_index(drop=True, inplace=True) 78 79 # date hour pressure wind_direction temperature 80 #0 2016-07-01 0.0 1000.4 225.0 26.4 81 #1 2016-07-01 6.0 998.9 212.0 31.7 82 #2 2016-07-01 235.0 998.7 244.0 NaN 83 #3 2016-07-01 12.0 999.7 222.0 NaN 84 #4 2016-07-01 15.0 1000.0 102.0 NaN 85 #5 2016-07-01 NaN 998.8 202.0 26.0 86 #6 2016-07-01 NaN 1000.2 334.0 25.5 87 #7 2016-07-01 NaN 1000.2 334.0 25.5 88 #8 2016-07-02 3.0 1002.4 46.0 30.0 89 #9 2016-07-02 6.0 1001.3 37.0 29.3 90 #10 2016-07-02 9.0 1001.9 345.0 25.9 91 #11 2016-07-02 12.0 1003.6 113.0 25.1 92 #12 2016-07-02 12.0 1003.6 113.0 25.1 93 #13 2016-07-02 15.0 1002.4 138.0 25.3 94 print(data) 95 96 97 # In[6]: 98 99 100 # 2. 填充空白,hour填充10,temperature填充25.5 101 data.fillna({'hour':10, 'temperature':25.5}, inplace=True) 102 103 # date hour pressure wind_direction temperature 104 #0 2016-07-01 0.0 1000.4 225.0 26.4 105 #1 2016-07-01 6.0 998.9 212.0 31.7 106 #2 2016-07-01 235.0 998.7 244.0 25.5 107 #3 2016-07-01 12.0 999.7 222.0 25.5 108 #4 2016-07-01 15.0 1000.0 102.0 25.5 109 #5 2016-07-01 10.0 998.8 202.0 26.0 110 #6 2016-07-01 10.0 1000.2 334.0 25.5 111 #7 2016-07-01 10.0 1000.2 334.0 25.5 112 #8 2016-07-02 3.0 1002.4 46.0 30.0 113 #9 2016-07-02 6.0 1001.3 37.0 29.3 114 #10 2016-07-02 9.0 1001.9 345.0 25.9 115 #11 2016-07-02 12.0 1003.6 113.0 25.1 116 #12 2016-07-02 12.0 1003.6 113.0 25.1 117 #13 2016-07-02 15.0 1002.4 138.0 25.3 118 print(data) 119 120 121 # In[7]: 122 123 124 # 3. 删掉hour>24的行 125 num = data.index.max() 126 127 for i in range(num): 128 if data.loc[i, 'hour'] > 24: 129 data.drop([i], inplace=True) 130 print('hour > 24, deleted') 131 132 data.reset_index(drop=True, inplace=True) 133 134 #hour > 24, deleted 135 # date hour pressure wind_direction temperature 136 #0 2016-07-01 0.0 1000.4 225.0 26.4 137 #1 2016-07-01 6.0 998.9 212.0 31.7 138 #2 2016-07-01 12.0 999.7 222.0 25.5 139 #3 2016-07-01 15.0 1000.0 102.0 25.5 140 #4 2016-07-01 10.0 998.8 202.0 26.0 141 #5 2016-07-01 10.0 1000.2 334.0 25.5 142 #6 2016-07-01 10.0 1000.2 334.0 25.5 143 #7 2016-07-02 3.0 1002.4 46.0 30.0 144 #8 2016-07-02 6.0 1001.3 37.0 29.3 145 #9 2016-07-02 9.0 1001.9 345.0 25.9 146 #10 2016-07-02 12.0 1003.6 113.0 25.1 147 #11 2016-07-02 12.0 1003.6 113.0 25.1 148 #12 2016-07-02 15.0 1002.4 138.0 25.3 149 print(data) 150 151 152 # In[8]: 153 154 155 # 4. 删掉重复的数据行,保留出现的第一行(全部删掉?保留最后一行?) 156 data.drop_duplicates(keep='first', inplace=True) 157 data.reset_index(drop=True, inplace=True) 158 159 # date hour pressure wind_direction temperature 160 #0 2016-07-01 0.0 1000.4 225.0 26.4 161 #1 2016-07-01 6.0 998.9 212.0 31.7 162 #2 2016-07-01 12.0 999.7 222.0 25.5 163 #3 2016-07-01 15.0 1000.0 102.0 25.5 164 #4 2016-07-01 10.0 998.8 202.0 26.0 165 #5 2016-07-01 10.0 1000.2 334.0 25.5 166 #6 2016-07-02 3.0 1002.4 46.0 30.0 167 #7 2016-07-02 6.0 1001.3 37.0 29.3 168 #8 2016-07-02 9.0 1001.9 345.0 25.9 169 #9 2016-07-02 12.0 1003.6 113.0 25.1 170 #10 2016-07-02 15.0 1002.4 138.0 25.3 171 print(data) 172 173 174 # In[9]: 175 176 177 # 5. 数据重排 178 randnum = np.random.permutation(data.index.size) 179 180 #[ 4 0 10 3 1 5 8 9 7 2 6] 181 print(randnum) 182 183 184 # In[10]: 185 186 187 data2 = data.take(randnum) 188 189 # date hour pressure wind_direction temperature 190 #4 2016-07-01 10.0 998.8 202.0 26.0 191 #0 2016-07-01 0.0 1000.4 225.0 26.4 192 #10 2016-07-02 15.0 1002.4 138.0 25.3 193 #3 2016-07-01 15.0 1000.0 102.0 25.5 194 #1 2016-07-01 6.0 998.9 212.0 31.7 195 #5 2016-07-01 10.0 1000.2 334.0 25.5 196 #8 2016-07-02 9.0 1001.9 345.0 25.9 197 #9 2016-07-02 12.0 1003.6 113.0 25.1 198 #7 2016-07-02 6.0 1001.3 37.0 29.3 199 #2 2016-07-01 12.0 999.7 222.0 25.5 200 #6 2016-07-02 3.0 1002.4 46.0 30.0 201 print(data2) 202 203 204 # In[11]: 205 206 207 # 6. 随机采样 208 data3 = data.sample(8) 209 210 # date hour pressure wind_direction temperature 211 #4 2016-07-01 10.0 998.8 202.0 26.0 212 #0 2016-07-01 0.0 1000.4 225.0 26.4 213 #2 2016-07-01 12.0 999.7 222.0 25.5 214 #1 2016-07-01 6.0 998.9 212.0 31.7 215 #5 2016-07-01 10.0 1000.2 334.0 25.5 216 #9 2016-07-02 12.0 1003.6 113.0 25.1 217 #7 2016-07-02 6.0 1001.3 37.0 29.3 218 #8 2016-07-02 9.0 1001.9 345.0 25.9 219 print(data3) 220 data3.to_csv('data3.csv')
python — 数据分析之旅,matplotlib
- Numpy
- 科学计算
- pandas
- 数据清洗 / 去重 / 修改删除异常值 / 随机采样 / 重排
- 数据分析的流程
- 数据建模
- 学习规律,指导将来的决策 - 机器学习
- 数据 图
- 数据可视化
- Python开发
- 语法简洁
- 丰富的库
- 标准库
- 第三方库
- numpy / pandas / matplotlib
- PyPI.org
- 构建快速原型
- AI主流的编程语言
1 # coding: utf-8 2 3 # In[1]: 4 5 6 import matplotlib.pyplot as plt 7 import numpy as np 8 from mpl_toolkits.mplot3d import Axes3D 9 10 11 # In[2]: 12 13 14 # 1. 线形图 y = ax + b 15 x = np.linspace(1, 21, 20) 16 y = 2 * x + 3 17 y2 = np.sin(x) 18 19 plt.plot(x, y, 'm^:', x, y2) 20 21 plt.show() 22 23 24 # In[3]: 25 26 27 # 2. 散点图 28 n = 1024 29 x = np.random.normal(0, 1, n) #1024个符合高斯分布的值 30 y = np.random.normal(0, 1, n) 31 32 plt.scatter(x, y, s=np.random.rand(n)*50, c=np.random.rand(n), alpha=0.7) 33 34 plt.show() 35 36 37 # In[4]: 38 39 40 # 3. 柱状图 41 n = 10 42 x = np.arange(n) 43 y1 = (1 - x / float(n)) * np.random.uniform(0.5, 1.0, n) 44 y2 = (1 - x / float(n)) * np.random.uniform(0.5, 1.0, n) 45 46 plt.bar(x, y1, facecolor='red', edgecolor='white') 47 plt.bar(x, -y2, facecolor='blue', edgecolor='black') 48 49 for xx, y in zip(x, y1): 50 plt.text(xx, y + 0.1, '%0.2f'%y, ha='center', va='bottom') 51 52 for xx, y in zip(x, -y2): 53 plt.text(xx, y - 0.1, '%0.2f'%y, ha='center', va='bottom') 54 55 plt.ylim(-1.5, 1.5) 56 57 plt.show() 58 59 60 # In[5]: 61 62 63 # 4. 3D 64 fig = plt.figure(figsize=(12, 8)) 65 ax = Axes3D(fig) 66 x = np.arange(-4, 4, 0.25) 67 y = np.arange(-4, 4, 0.25) 68 69 x, y = np.meshgrid(x, y) 70 #[[-4. -3.75 -3.5 ... 3.25 3.5 3.75] 71 # [-4. -3.75 -3.5 ... 3.25 3.5 3.75] 72 # [-4. -3.75 -3.5 ... 3.25 3.5 3.75] 73 # ... 74 # [-4. -3.75 -3.5 ... 3.25 3.5 3.75] 75 # [-4. -3.75 -3.5 ... 3.25 3.5 3.75] 76 # [-4. -3.75 -3.5 ... 3.25 3.5 3.75]] 77 print(x) 78 #[[-4. -4. -4. ... -4. -4. -4. ] 79 # [-3.75 -3.75 -3.75 ... -3.75 -3.75 -3.75] 80 # [-3.5 -3.5 -3.5 ... -3.5 -3.5 -3.5 ] 81 # ... 82 # [ 3.25 3.25 3.25 ... 3.25 3.25 3.25] 83 # [ 3.5 3.5 3.5 ... 3.5 3.5 3.5 ] 84 # [ 3.75 3.75 3.75 ... 3.75 3.75 3.75]] 85 print(y) 86 87 z = np.sin(np.sqrt(x**2 + y**2)) 88 89 ax.plot_surface(x, y, z, cmap=plt.get_cmap('autumn')) 90 91 plt.show() 92 93 94 # In[6]: 95 96 97 # 5. 一图多画 98 x = np.linspace(0, 5, 5) 99 y1 = x**2 100 y2 = 2 * x 101 y3 = np.sin(x) 102 y4 = np.cos(x) 103 104 ax1 = plt.subplot(221) 105 plt.plot(x, y1) 106 ax2 = plt.subplot(2, 2, 2) 107 plt.plot(x, y2) 108 ax3 = plt.subplot(223) 109 plt.plot(x, y3) 110 ax4 = plt.subplot(2, 2, 4) 111 #plt.plot(x, y4) 112 113 plt.show()
Python - 人工智能
全方位认识python
- Python大器晚成原因
- 1990那个年代,计算机性能比现在差很多,程序执行速度和效率更重要,快速开发不是第一要务,压榨机器性能才是。
- Python非大企业出身
- Python语言特点
- 简单易学、明确优雅、开发速度快
- 跨平台、可移植、可扩展、交互式、解释型面向对象的动态语言
- 解释型:Python语言在执行过程中由解释器逐行分析,逐行运行并输出结果
- “自带电池”,大量的标准库和第三方库
- 社区活跃,贡献者多,互帮互助
- 开源语言,发展动力巨大
- Python的缺点
- 运行速度相对慢点。
- GIL(Global Interpreter Lock)全局解释器锁 。
- Python的应用方向
- 常规软件开发
- 科学计算
- WEB开发
- 网络爬虫
- 数据分析
- 人工智能
全面解读人工智能
- 人工智能 / 机器学习 / 深度学习
- 人工智能(Artificial Intelligence)
- 人工智能类型
- 弱人工智能
- 包含基础的、特定场景下角色型的任务,如Siri,ALphaGo等
- 通用人工智能
- 包含人类水平的任务,涉及机器的持续学习
- 强人工智能
- 比人类更聪明的机器
- 弱人工智能
- 手机中的AI
- 智能美图
- 智能搜索排序
- 自动驾驶
- 智能会话
- 机器翻译
- 智能物流
- 新一代AI应用
- 理论与基础技术
- 大数据智能
- 技术研究
- 语言识别
- 自然语言理解
- 图像识别
- 应用研发
- 聊天界面(小冰)
- 语音助手(Siri)
- 语音记录(讯飞)
- 翻译(谷歌)
- 智能音箱(亚马逊Echo)
- 延展性和渗透性:智能音箱
- 理论与基础技术
- 人工智能的技术架构
- 应用层
- 智能产品
- 应用平台
- 技术层
- 通用技术
- 算法模型
- 基础框架
- 基础层
- 数据资源
- 软件设施
- 硬件设施
- 应用层
- 机器学习
- 计算机从数据中学习出规律和模式,以应用在新数据上做预测的任务
- 互联网大数据中挖掘出有用的价值
- 机器学习算法分类、解决什么问题
- 监督学习
- 需要用已知结果的数据做训练
- 输入的数据有相对应的标签
- 分类问题
- 根据数据样本上抽取的特征,判定其属于有限个类别中的哪一个
- 回归问题
- 根据数据样本上抽取的特征,预测一个连续值的结果
- 非监督学习
- 不需要已知标签
- 输入的信息不知道是什么分类,不知道规则,没有输出,结果就是寻找数据中的规则
- 聚类问题
- 根据数据样本上抽取的特征,让样本抱团(相近/相关的样本在一团内)
- 半监督学习
- 近几年新起的介于监督学习与非监督学习之间。先少量标注一部分数据,然后寻找这部分数据的特征,自动给剩下的数据标注标签。
- 强化学习
- 强调如何基于环境而行动,以取得最大化的预期收益。有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。常被应用在机器人、无人机等领域。
- 监督学习
- 机器学习的应用
- 数据挖掘
- 计算机视觉
- 自然语言处理
- 生物特征识别
- 搜索引擎
- 医学诊断
- 检测信用卡欺诈
- 证券市场分析
- 语音和手写识别
- 机器人
- 机器学习的学习路径
- 数学基础
- 微积分
- 机器学习中大多数算法的求解过程的核心
- 线性代数
- 矩阵的各种运算
- 概率与统计
- 朴素贝叶斯
- 隐式马尔可夫
- 微积分
- 机器学习典型方法
- 分类问题
- 决策树、支持向量机(SVM)、随机森林、朴素贝叶斯、深度神经网络
- 回归问题
- 线性回归、普通最小二乘回归、逐步回归
- 聚类问题
- K均值(K-means)、基于密度聚类
- 降维
- 主成分分析(PCA)、奇异值分解(SVD)
- 其他算法
- Adaboost、EM等
- 分类问题
- 编程基础
- Python有全品类的数据科学工具
- Scrapy:网页爬虫
- Pandas:数据浏览与预处理
- numpy:数组运算
- scipy:高效的科学计算
- matplotlib:非常方便的数据可视化工具
- scikit-learn:远近闻名的机器学习package,接口封装好,几乎所有的机器学习算法输入输出格式都一致。支持文档可以直接当教程来学习。
- libsvm:高效的svm模型实现
- keras/TensorFlow:深度学习,方便搭建自己的神经网络
- nltk:自然语言处理相关功能做的非常全面,有典型语料库,上手容易
- R - 开源,有许多可用的包
- C++ - mlpack,Shark
- Java - WEKA Machine Learning Workbench
- Python有全品类的数据科学工具
- 数学基础
- 机器学习实施过程
- 原始样本集
- 特征提取
- 特征样本集
- 预处理
- 训练集 - 训练 / 验证集 - 预测
- 机器学习算法
- 输出
- 验证集 / 预测目标
- 评价 / 改进
- 深度学习
- 一类算法集合,机器学习的一个分支,尝试为数据的高层次摘要进行建模
- 人工神经网络
- 深度神经网络
- CNN、RNN、FCN
- 人工智能、机器学习、深度学习三者的关系
- 人工智能
- 让机器像人一样思考
- 国际跳棋程序
- 机器学习
- 人工智能的分支,研究机器模拟或实现人类的学习行为,以获取新的知识技能,并改善自身性能
- 垃圾邮件过滤
- 深度学习
- 一种机器学习方法,模拟人脑机制解释数据,通过组合低层特征形成更抽象的高层属性类别或特征
- 谷歌视频寻猫
- 人工智能
- 深度学习必备基础
- Python
- 公开论文 / 代码都是python为主流
- 开源框架基本都是python接口
- 线性代数、微积分
- 矩阵计算和梯度求导运算
- Python
- 主流深度学习框架
- TensorFlow
- Caffe
- Keras
- CNTK
- MXNet
- Torch7
- Theano
- Deeplearning4J
- Leaf
- Lasagne
- Neon
- 深度学习的应用
- 人脸识别
- 通用物体检测
- 图像分割
- 光学字符识别 - OCR
- 语音识别
- 机器翻译
- 情感识别
机器学习实例
-
KNN分类算法的分类预测过程
-
对于一个需要预测的输入向量x,只需要在训练数据集中寻找k个与向量x最近的向量的集合,然后把x的类标预测为这k个样本中类标数最多的那一类。
-
- 机器学习的主要步骤
- 准备数据集(量要大,模型才够精确。数据要全面,模型才全面)
- 数据清洗,数据预处理(噪声,缺失值,乱码,特征的提取,分为训练集和测试集)
- 选择一个模型(算法)
- 训练(训练集训练模型)
- 模型(分类,预测)- 测试集(验证集)
- 评估
- 模型的优化
- 调参,e.g. KNN(k)
- 换模型
- 迭代4-6
- 基于KNN的手写体数字识别
1 # coding: utf-8 2 3 # In[1]: 4 5 6 from sklearn.model_selection import train_test_split 7 from sklearn.neighbors import KNeighborsClassifier 8 from sklearn.metrics import accuracy_score 9 from sklearn import datasets 10 11 12 # In[2]: 13 14 15 """ 16 手写体数字,监督学习 17 1、样本集:一批手写体数字的图片,带标签(0-9),10类 18 样本数据量为1797,存在sklearn的datasets里。 19 每一个数据样本都是由image, target两部分组成。 20 image是一个尺寸为8*8的图像(手写的数字0-9), 21 target是图像的类别(数字0-9)。 22 2、划分训练集和测试集 23 3、选一个算法,构建模型,KNN 24 4、训练模型 25 5、预测、验证 26 6、模型优化(SVM, 决策树) 27 7、保存模型(.model, load, predict) 28 8、新建多张手写体图片,让模型来识别新的图片 29 """ 30 sample_data = datasets.load_digits() 31 images = sample_data.data 32 labels = sample_data.target 33 34 35 # In[3]: 36 37 38 #划分训练集和测试集 39 train_data, test_data, train_labels, test_labels = train_test_split(images, labels, test_size=0.1) 40 41 42 # In[4]: 43 44 45 #选择模型 46 model_knn = KNeighborsClassifier(n_neighbors=4, algorithm='auto', weights='distance') 47 48 49 # In[5]: 50 51 52 #训练模型 53 model_knn.fit(train_data, train_labels) 54 #KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', 55 # metric_params=None, n_jobs=1, n_neighbors=4, p=2, 56 # weights='distance') 57 58 # In[6]: 59 60 61 #预测、验证 62 pred = model_knn.predict(test_data) 63 print("pred : ", pred) 64 print("test_labels : ", test_labels) 65 #pred : 66 # [3 4 1 4 4 0 0 8 2 9 8 9 6 1 3 3 7 8 5 1 3 2 1 2 7 4 8 5 7 1 0 2 4 0 7 3 1 67 # 5 3 4 6 2 5 1 6 3 4 5 4 9 3 6 5 0 0 4 5 2 0 7 7 6 5 1 2 9 9 2 7 6 3 2 3 8 68 # 6 7 6 4 0 2 2 8 8 8 5 0 2 0 4 2 2 0 6 6 6 0 9 8 9 5 3 8 5 7 9 6 3 0 3 9 5 69 # 1 0 9 6 7 0 1 5 3 0 3 4 9 2 3 8 2 2 5 7 2 6 2 7 3 1 4 5 9 9 6 6 9 7 1 3 7 70 # 1 9 8 6 9 9 6 5 0 5 6 9 7 7 5 0 3 8 5 9 2 0 9 3 1 2 9 3 7 6 9 6] 71 #test_labels : 72 # [3 4 1 4 4 0 0 8 2 9 8 9 6 1 3 3 7 8 5 1 3 2 1 2 7 4 8 5 7 1 0 2 4 0 7 3 1 73 # 5 3 4 6 2 5 1 6 3 4 5 4 9 3 6 5 0 0 4 5 2 0 7 7 6 5 1 2 9 9 2 7 6 3 2 3 8 74 # 6 7 6 4 0 2 2 8 8 8 5 0 2 0 4 2 2 0 6 6 6 0 9 8 7 5 3 8 5 7 9 6 3 0 3 9 5 75 # 1 0 9 6 7 0 1 5 3 0 3 4 9 2 3 8 2 2 5 7 2 6 2 7 3 1 4 5 9 9 6 6 9 7 1 3 7 76 # 1 9 8 6 9 9 6 5 0 5 6 9 7 7 5 0 3 8 5 9 2 0 9 3 1 2 9 3 7 6 9 6] 77 78 # In[7]: 79 80 81 #查看准确率 82 acc = accuracy_score(pred, test_labels) 83 print("Accuracy rate : %.3f" % acc) 84 #Accuracy rate : 0.994
基于CNN的手写体数字识别
- 手写体数字识别 - 机器学习的HelloWorld
- MNIST数据集
- MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
- http://yann.lecun.com/exdb/mnist/
- MNIST数据集
- Keras
- 纯python编写的基于theano/tensorflow的深度学习框架。一个高度模块化的神经网络库,支持GPU和CPU。
- 一致而简洁的API,极大减少一般应用下用户的工作量
- Keras搭建神经网络的过程
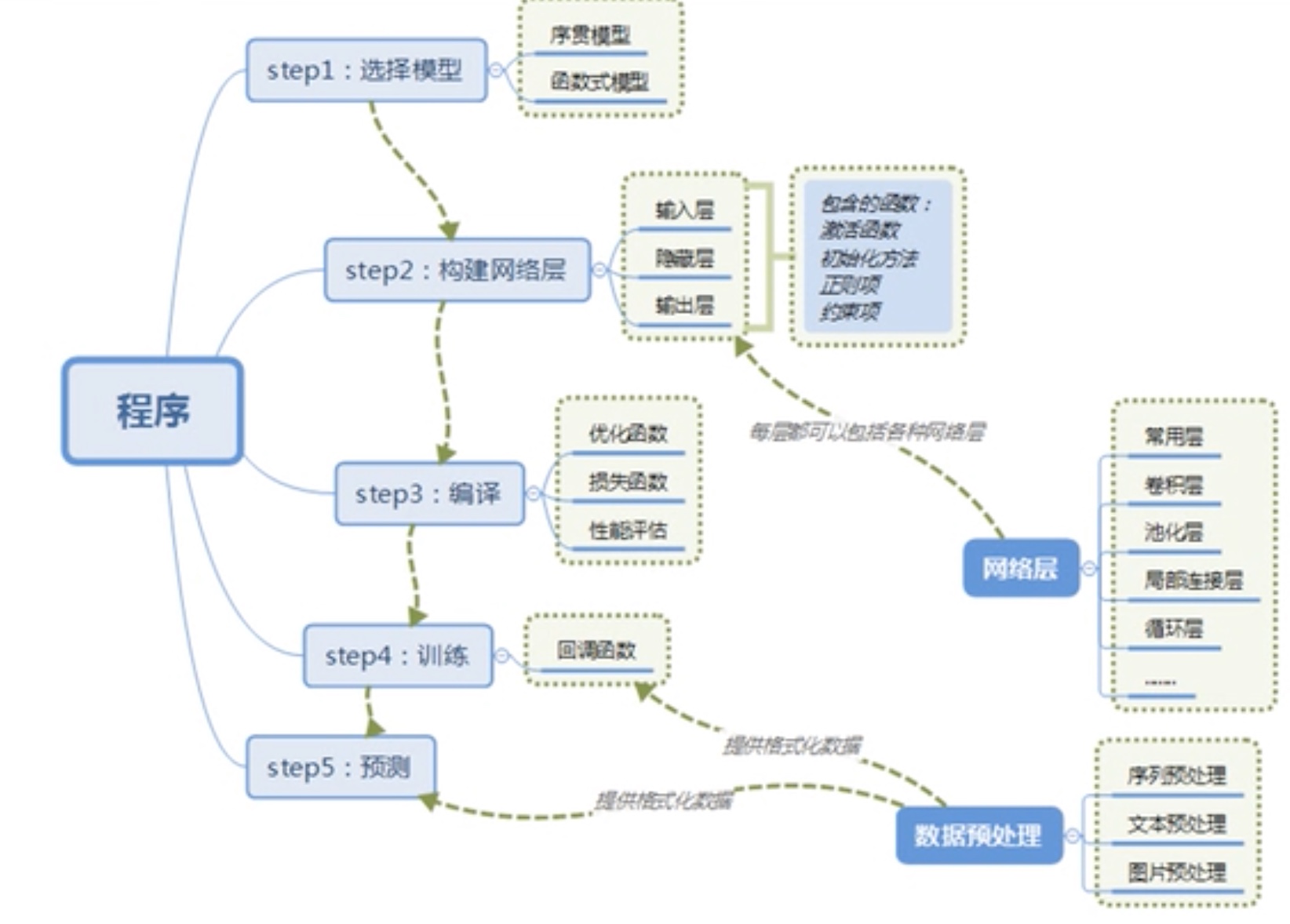
- CNN - 卷积神经网络
- CNN的建造灵感来自于人类对视觉信息的识别过程:点 -> 线 -> 面。
- 卷积层
- 卷是席卷,积为乘积。卷积实质上是用一个叫kernel的矩阵,从图像的小块上一一贴过去,每次和图像块的每一个像素乘积得到一个output值,扫过之后就得到一个新图像。
- 池化层
- 下采样(subsampling),分为最大值池化和平均值池化。
- 为什么池化
- 图像经过下采样尺寸缩小
- 增强了旋转不定性,池化操作可以看作是一种强制性的模糊策略
- 核的大小 / 步长
- CNN的过程

-
- 我们将输入图像传递到第一个卷积层,卷积后以激活图形式输出。图片在卷积层中过滤后的特征会被输出,并传递下去。
- 每个过滤器都会给出不同的特征,以帮助进行正确的类预测。
- 随后加入池化层进一步减少参数的数量。
- 在预测最终提出前,数据会经过多个卷积层和池化层的处理。卷积层会帮助提取特征,越深的卷积神经网络会提取越具体的特征,越浅的神经网络提取越浅显的特征。
- CNN中的输出层是全连接层,其中来自其他层的输入在这里被平化和发送,以便将输出转换为网络所需的参数。
- 随后输出层会产生输出,这些信息会互相比较排除错误。损失函数是全连接输出层计算的均方根损失。随后我们会计算梯度错误。
- 错误会进行反向传播,以不断改进过滤器(权重)和偏差值。
- 一个训练周期由单次正向和反向传递完成。
1 # coding: utf-8 2 3 # In[1]: 4 5 6 """ 7 基于CNN的手写体数字识别 8 9 迭代一轮 80s 10 """ 11 import keras 12 from keras.datasets import mnist 13 from keras.models import Sequential 14 from keras.layers import Dense, Dropout, Flatten 15 from keras.layers import Conv2D, MaxPooling2D 16 from keras import backend as K 17 18 19 # In[2]: 20 21 22 # 设置初始参数 23 batch_size = 128 # 一批喂给模型多少张图片 60000 24 num_classes = 10 # 分类 0 - 9 25 epochs = 12 # 迭代次数 26 27 img_rows, img_cols = 28, 28 # 28 * 28 28 29 30 # In[3]: 31 32 33 # 加载数据 34 (x_train, y_train), (x_test, y_test) = mnist.load_data() # 加载数据集,第一次运行慢 35 36 # 判断backend theano, tensorflow 37 # 彩色图片 RGB 3 通道,灰度图 1 通道 38 if K.image_data_format() == 'channels_first': 39 x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols) # (60000, 1, 28, 28) 40 x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols) 41 intput_shape = (1, img_rows, img_cols) 42 else: 43 x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1) 44 x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1) 45 input_shape = (img_rows, img_cols, 1) 46 47 48 # In[4]: 49 50 51 # 数据处理 52 53 # image处理 54 x_train = x_train.astype('float32') 55 x_test = x_test.astype('float32') 56 x_train /= 255 57 x_test /= 255 58 59 #x_train shape: (60000, 28, 28, 1) 60 #60000 train samples 61 #10000 test samples 62 print('x_train shape: ', x_train.shape) 63 print(x_train.shape[0], 'train samples') 64 print(x_test.shape[0], 'test samples') 65 66 # labels处理 67 # 5 -> [0000010000] 2 -> [0010000000] 68 y_train = keras.utils.to_categorical(y_train, num_classes) 69 y_test = keras.utils.to_categorical(y_test, num_classes) 70 71 72 # In[5]: 73 74 75 # 1. 选择模型 76 model = Sequential() # 序贯模型 77 78 79 # In[6]: 80 81 82 # 2. 构建网络层 83 # CNN的参数 权重(卷积核的构成),卷积核大小,数量,池化大小,步长,dropout rate 84 model.add(Conv2D(32, 85 kernel_size=(3, 3), 86 activation='relu', 87 input_shape=input_shape)) # 卷积层1 88 89 model.add(Conv2D(64, 90 (3, 3), 91 activation='relu')) # 卷积层2 92 93 model.add(MaxPooling2D(pool_size=(2, 2))) # 池化, 默认步长1 94 95 model.add(Dropout(0.25)) # 防止过拟合:训练集特征提取太细致,不适用于测试集 96 97 model.add(Flatten()) # 压平 98 99 model.add(Dense(128, 100 activation='relu')) # 全连接:所有神经元之间都是互相连接的 101 102 model.add(Dropout(0.5)) # 扔掉50% 103 104 model.add(Dense(num_classes, 105 activation='softmax')) # 全连接,多分类 106 107 108 # In[7]: 109 110 111 # 3. 编译 112 model.compile(loss=keras.losses.categorical_crossentropy, 113 optimizer=keras.optimizers.Adadelta(), 114 metrics=['accuracy']) 115 116 117 # In[8]: 118 119 120 # 4. 训练 121 model.fit(x_train, 122 y_train, 123 batch_size=batch_size, 124 epochs=epochs, 125 verbose=1, 126 validation_data=(x_test, y_test)) # 开始训练 127 128 #Train on 60000 samples, validate on 10000 samples 129 #Epoch 1/12 130 #60000/60000 [==============================] - 79s 1ms/step - loss: 0.2630 - acc: 0.9195 - val_loss: 0.0574 - val_acc: 0.9825 131 #Epoch 2/12 132 #60000/60000 [==============================] - 77s 1ms/step - loss: 0.0900 - acc: 0.9730 - val_loss: 0.0437 - val_acc: 0.9855 133 #Epoch 3/12 134 #60000/60000 [==============================] - 78s 1ms/step - loss: 0.0663 - acc: 0.9810 - val_loss: 0.0387 - val_acc: 0.9874 135 #Epoch 4/12 136 #60000/60000 [==============================] - 76s 1ms/step - loss: 0.0555 - acc: 0.9836 - val_loss: 0.0321 - val_acc: 0.9881 137 #Epoch 5/12 138 #60000/60000 [==============================] - 76s 1ms/step - loss: 0.0462 - acc: 0.9862 - val_loss: 0.0287 - val_acc: 0.9907 139 #Epoch 6/12 140 #60000/60000 [==============================] - 81s 1ms/step - loss: 0.0418 - acc: 0.9873 - val_loss: 0.0318 - val_acc: 0.9893 141 #Epoch 7/12 142 #60000/60000 [==============================] - 81s 1ms/step - loss: 0.0364 - acc: 0.9885 - val_loss: 0.0291 - val_acc: 0.9907 143 #Epoch 8/12 144 #60000/60000 [==============================] - 80s 1ms/step - loss: 0.0338 - acc: 0.9898 - val_loss: 0.0260 - val_acc: 0.9922 145 #Epoch 9/12 146 #60000/60000 [==============================] - 80s 1ms/step - loss: 0.0319 - acc: 0.9903 - val_loss: 0.0266 - val_acc: 0.9918 147 #Epoch 10/12 148 #60000/60000 [==============================] - 79s 1ms/step - loss: 0.0290 - acc: 0.9908 - val_loss: 0.0271 - val_acc: 0.9919 149 #Epoch 11/12 150 #60000/60000 [==============================] - 79s 1ms/step - loss: 0.0281 - acc: 0.9911 - val_loss: 0.0247 - val_acc: 0.9928 151 #Epoch 12/12 152 #60000/60000 [==============================] - 82s 1ms/step - loss: 0.0256 - acc: 0.9920 - val_loss: 0.0251 - val_acc: 0.9926 153 #<keras.callbacks.History at 0x182f48b128> 154 155 156 # In[9]: 157 158 159 # 5. 预测 160 score = model.evaluate(x_test, y_test, verbose=0) # 在测试集上测试 161 162 #Test loss: 0.025120523367086936 163 #Test accuracy: 0.9926 164 print('Test loss: ', score[0]) 165 print('Test accuracy: ', score[1]) 166 167 168 # In[10]: 169 170 171 model.save('.modelHandwritingRecUsingCNN.model') # 保存模型