1.观察数据
NUM_WORDS = 10000
(train_data, train_labels), (test_data, test_labels) = keras.datasets.imdb.load_data(num_words=NUM_WORDS)
def multi_hot_sequences(sequences, dimension):
results = np.zeros((len(sequences), dimension))
for i, word_indices in enumerate(sequences):
results[i, word_indices] = 1.0
return results
train_data = multi_hot_sequences(train_data, dimension=NUM_WORDS)
test_data = multi_hot_sequences(test_data, dimension=NUM_WORDS)
plt.plot(train_data[0])
[<matplotlib.lines.Line2D at 0x7f92faa7c978>]
防止过度拟合的最简单方法是减小模型的大小,即模型中可学习参数的数量。
深度学习模型往往善于适应训练数据,但真正的挑战是概括,而不是适合。
另一方面,如果网络具有有限的记忆资源,则将不能容易地学习映射。为了最大限度地减少损失,它必须学习具有更强预测能力的压缩表示。同时,如果您使模型太小,则难以适应训练数据。 “太多容量”和“容量不足”之间存在平衡。
要找到合适的模型大小,最好从相对较少的图层和参数开始,然后开始增加图层的大小或添加新图层,直到看到验证损失的收益递减为止。
我们将在电影评论分类网络上使用Dense图层作为基线创建一个简单模型,然后创建更小和更大的版本,并进行比较。
2.创建一个baseline模型
import tensorflow.keras.layers as layers
baseline_model = keras.Sequential(
[
layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)),
layers.Dense(16, activation='relu'),
layers.Dense(1, activation='sigmoid')
]
)
baseline_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
baseline_model.summary()
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_15 (Dense) (None, 16) 160016
_________________________________________________________________
dense_16 (Dense) (None, 16) 272
_________________________________________________________________
dense_17 (Dense) (None, 1) 17
=================================================================
Total params: 160,305
Trainable params: 160,305
Non-trainable params: 0
_________________________________________________________________
baseline_history = baseline_model.fit(train_data, train_labels,
epochs=20, batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
...
Epoch 20/20
25000/25000 - 3s - loss: 0.0044 - accuracy: 0.9999 - binary_crossentropy: 0.0044 - val_loss: 0.9217 - val_accuracy: 0.8488 - val_binary_crossentropy: 0.92173.创建一个小模型
small_model = keras.Sequential(
[
layers.Dense(4, activation='relu', input_shape=(NUM_WORDS,)),
layers.Dense(4, activation='relu'),
layers.Dense(1, activation='sigmoid')
]
)
small_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
small_model.summary()
Model: "sequential_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_18 (Dense) (None, 4) 40004
_________________________________________________________________
dense_19 (Dense) (None, 4) 20
_________________________________________________________________
dense_20 (Dense) (None, 1) 5
=================================================================
Total params: 40,029
Trainable params: 40,029
Non-trainable params: 0
_________________________________________________________________
small_history = small_model.fit(train_data, train_labels,
epochs=20, batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
25000/25000 - 3s - loss: 0.6170 - accuracy: 0.6609 - binary_crossentropy: 0.6170 - val_loss: 0.5217 - val_accuracy: 0.8034 - val_binary_crossentropy: 0.5217
...
Epoch 20/20
25000/25000 - 2s - loss: 0.0426 - accuracy: 0.9936 - binary_crossentropy: 0.0426 - val_loss: 0.4976 - val_accuracy: 0.8608 - val_binary_crossentropy: 0.49764.创建一个大模型
big_model = keras.Sequential(
[
layers.Dense(512, activation='relu', input_shape=(NUM_WORDS,)),
layers.Dense(512, activation='relu'),
layers.Dense(1, activation='sigmoid')
]
)
big_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
big_model.summary()
Model: "sequential_7"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_21 (Dense) (None, 512) 5120512
_________________________________________________________________
dense_22 (Dense) (None, 512) 262656
_________________________________________________________________
dense_23 (Dense) (None, 1) 513
=================================================================
Total params: 5,383,681
Trainable params: 5,383,681
Non-trainable params: 0
_________________________________________________________________
big_history = big_model.fit(train_data, train_labels,
epochs=20, batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
25000/25000 - 7s - loss: 0.3523 - accuracy: 0.8466 - binary_crossentropy: 0.3523 - val_loss: 0.2936 - val_accuracy: 0.8808 - val_binary_crossentropy: 0.2936
Epoch 20/20
25000/25000 - 6s - loss: 1.2638e-05 - accuracy: 1.0000 - binary_crossentropy: 1.2638e-05 - val_loss: 0.9282 - val_accuracy: 0.8704 - val_binary_crossentropy: 0.9282
def plot_history(histories, key='binary_crossentropy'):
plt.figure(figsize=(16,10))
for name, history in histories:
val = plt.plot(history.epoch, history.history['val_'+key],
'--', label=name.title()+' Val')
plt.plot(history.epoch, history.history[key], color=val[0].get_color(),
label=name.title()+' Train')
plt.xlabel('Epochs')
plt.ylabel(key.replace('_',' ').title())
plt.legend()
plt.xlim([0,max(history.epoch)])
plot_history([('baseline', baseline_history),
('small', small_history),
('big', big_history)])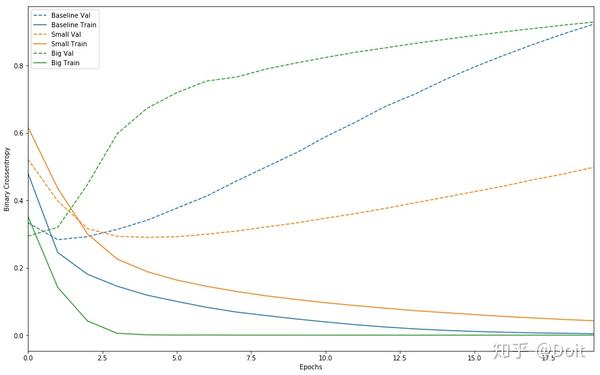
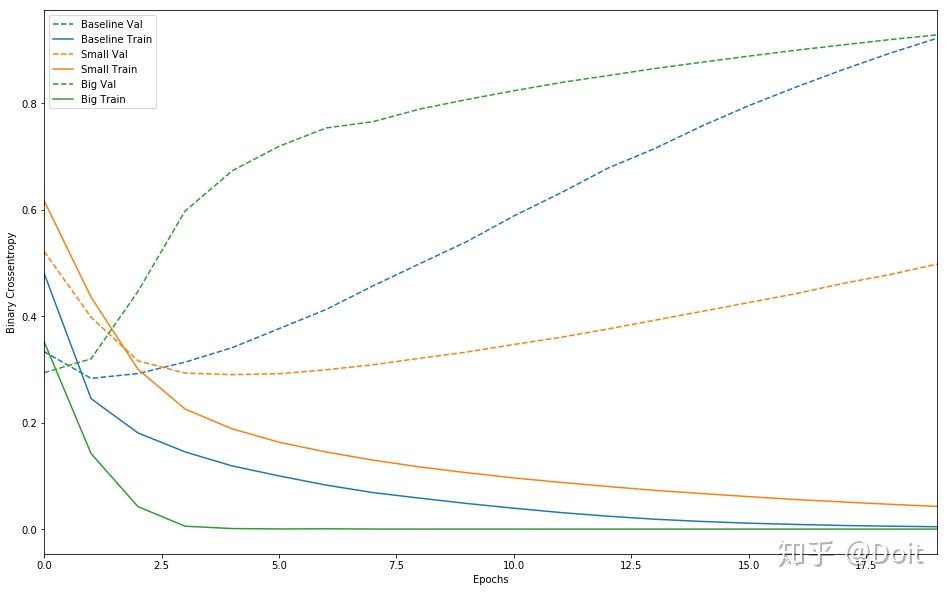
请注意,较大的网络在仅仅一个时期之后几乎立即开始过度拟合,并且更过拟合更严重。 网络容量越大,能够越快地对训练数据进行建模(导致训练损失低),但过度拟合的可能性越大(导致训练和验证损失之间的差异很大)。
5.添加l2正则
l2_model = keras.Sequential(
[
layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),
activation='relu', input_shape=(NUM_WORDS,)),
layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),
activation='relu'),
layers.Dense(1, activation='sigmoid')
]
)
l2_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
l2_model.summary()
l2_history = l2_model.fit(train_data, train_labels,
epochs=20, batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
Model: "sequential_9"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_27 (Dense) (None, 16) 160016
_________________________________________________________________
dense_28 (Dense) (None, 16) 272
_________________________________________________________________
dense_29 (Dense) (None, 1) 17
=================================================================
Total params: 160,305
Trainable params: 160,305
Non-trainable params: 0
_________________________________________________________________
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
25000/25000 - 3s - loss: 0.5264 - accuracy: 0.8019 - binary_crossentropy: 0.4874 - val_loss: 0.3828 - val_accuracy: 0.8769 - val_binary_crossentropy: 0.3415
...
Epoch 20/20
25000/25000 - 3s - loss: 0.1278 - accuracy: 0.9856 - binary_crossentropy: 0.0530 - val_loss: 0.5750 - val_accuracy: 0.8580 - val_binary_crossentropy: 0.5001
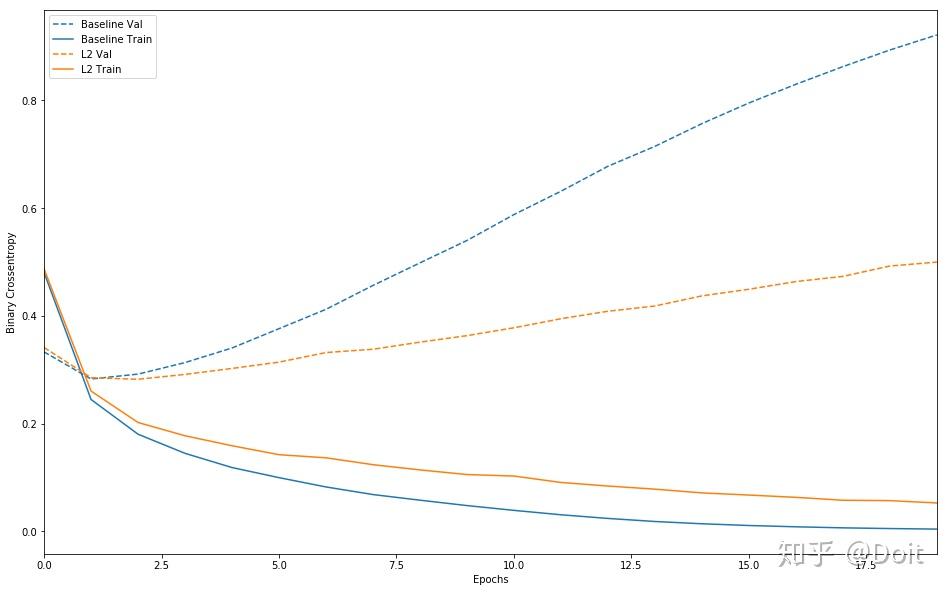
plot_history([('baseline', baseline_history),
('l2', l2_history)])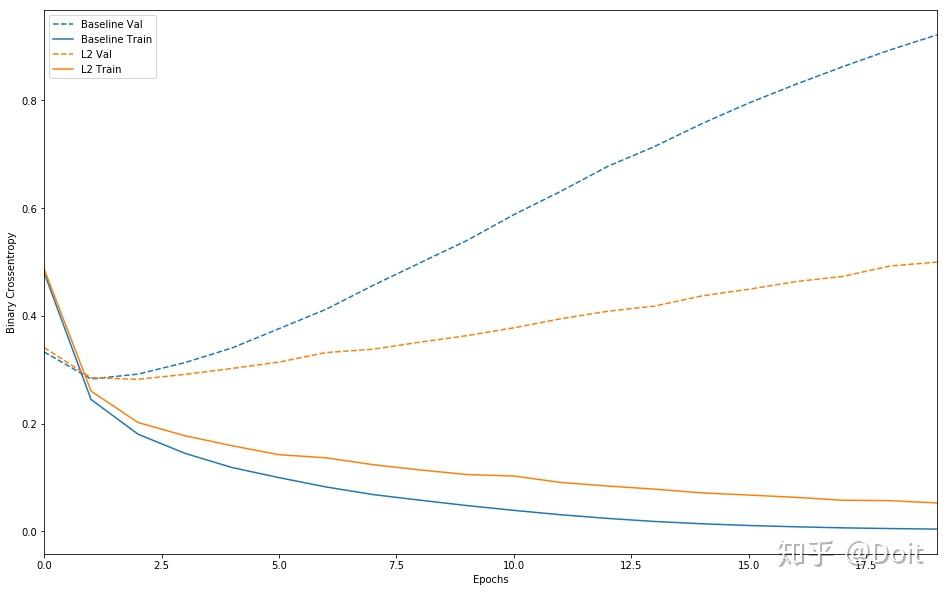
5.添加dropout
dpt_model = keras.Sequential(
[
layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)),
layers.Dropout(0.5),
layers.Dense(16, activation='relu'),
layers.Dropout(0.5),
layers.Dense(1, activation='sigmoid')
]
)
dpt_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
dpt_model.summary()
dpt_history = dpt_model.fit(train_data, train_labels,
epochs=20, batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
Model: "sequential_10"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_30 (Dense) (None, 16) 160016
_________________________________________________________________
dropout (Dropout) (None, 16) 0
_________________________________________________________________
dense_31 (Dense) (None, 16) 272
_________________________________________________________________
dropout_1 (Dropout) (None, 16) 0
_________________________________________________________________
dense_32 (Dense) (None, 1) 17
=================================================================
Total params: 160,305
Trainable params: 160,305
Non-trainable params: 0
_________________________________________________________________
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
25000/25000 - 4s - loss: 0.6364 - accuracy: 0.6512 - binary_crossentropy: 0.6364 - val_loss: 0.5510 - val_accuracy: 0.8113 - val_binary_crossentropy: 0.5510
...
Epoch 20/20
25000/25000 - 3s - loss: 0.1068 - accuracy: 0.9720 - binary_crossentropy: 0.1068 - val_loss: 0.5721 - val_accuracy: 0.8732 - val_binary_crossentropy: 0.5721
plot_history([('baseline', baseline_history),
('dropout', dpt_history)])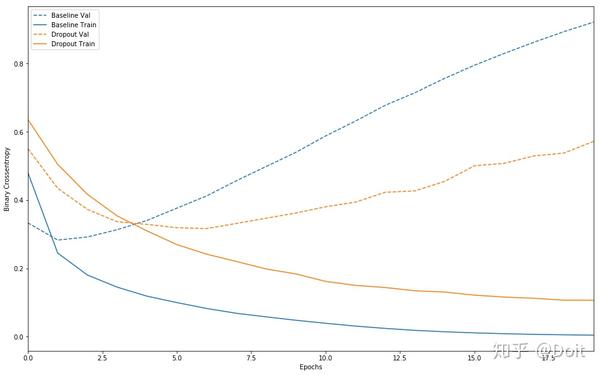
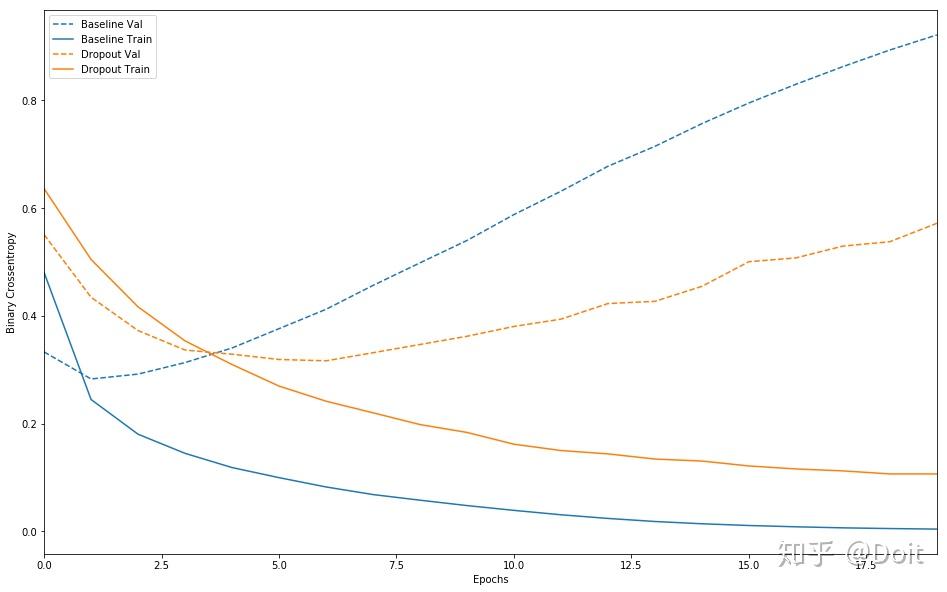
防止神经网络中过度拟合的最常用方法:
- 获取更多训练数据。
- 减少网络容量。
- 添加权重正规化。
- 添加dropout。