1.构造数据
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
print(x_train.shape, ' ', y_train.shape)
print(x_test.shape, ' ', y_test.shape)
(60000, 28, 28) (60000,)
(10000, 28, 28) (10000,)
import matplotlib.pyplot as plt
plt.imshow(x_train[0])
plt.show()


2.构造网络
x_train = x_train.reshape((-1,28,28,1))
x_test = x_test.reshape((-1,28,28,1))
model = keras.Sequential()
卷积层
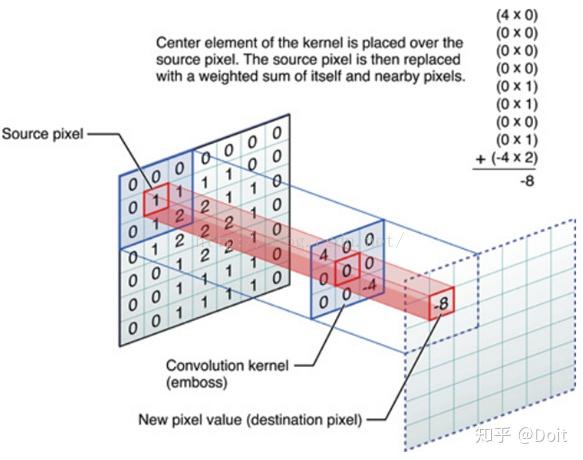

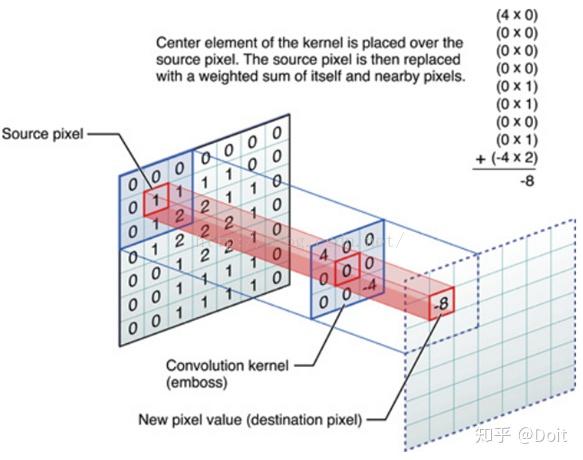
model.add(layers.Conv2D(input_shape=(x_train.shape[1], x_train.shape[2], x_train.shape[3]),
filters=32, kernel_size=(3,3), strides=(1,1), padding='valid',
activation='relu'))
池化层


model.add(layers.MaxPool2D(pool_size=(2,2)))
全连接层
model.add(layers.Flatten())
model.add(layers.Dense(32, activation='relu'))
# 分类层
model.add(layers.Dense(10, activation='softmax'))
3.模型配置
model.compile(optimizer=keras.optimizers.Adam(),
# loss=keras.losses.CategoricalCrossentropy(), # 需要使用to_categorical
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_2 (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 13, 13, 32) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 5408) 0
_________________________________________________________________
dense_2 (Dense) (None, 32) 173088
_________________________________________________________________
dense_3 (Dense) (None, 10) 330
=================================================================
Total params: 173,738
Trainable params: 173,738
Non-trainable params: 0
_________________________________________________________________
4.模型训练
history = model.fit(x_train, y_train, batch_size=64, epochs=5, validation_split=0.1)
Train on 54000 samples, validate on 6000 samples
Epoch 1/5
54000/54000 [==============================] - 11s 197us/sample - loss: 0.0589 - accuracy: 0.9825 - val_loss: 0.0963 - val_accuracy: 0.9785
Epoch 2/5
54000/54000 [==============================] - 11s 195us/sample - loss: 0.0500 - accuracy: 0.9849 - val_loss: 0.0957 - val_accuracy: 0.9777
Epoch 3/5
54000/54000 [==============================] - 11s 197us/sample - loss: 0.0429 - accuracy: 0.9867 - val_loss: 0.0881 - val_accuracy: 0.9798
Epoch 4/5
54000/54000 [==============================] - 11s 199us/sample - loss: 0.0381 - accuracy: 0.9877 - val_loss: 0.0811 - val_accuracy: 0.9817
Epoch 5/5
54000/54000 [==============================] - 11s 200us/sample - loss: 0.0340 - accuracy: 0.9890 - val_loss: 0.0910 - val_accuracy: 0.9795
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['training', 'valivation'], loc='upper left')
plt.show()


res = model.evaluate(x_test, y_test)
10000/10000 [==============================] - 1s 73us/sample - loss: 0.1255 - accuracy: 0.9733