Python3编码结论:
Python3的字符串在内存中是用Unicode(占空间和带宽)保存的,所以不能直接用于存储,传输。要通过其它编码转换成相对应的字节码
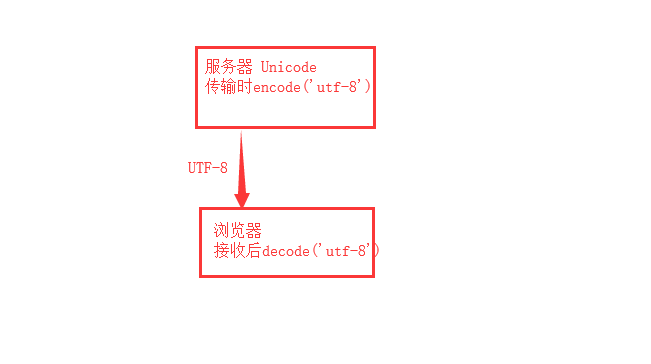
str ----encode--->byte
byte----decode--->str
常见的编码
编码是美国最先发明的,最先出来的是ASCII编码,最早计算机在设计时采用8个比特(bit)作为一个字节(byte),所以一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节;
陆续大多国家都有自己的编码;
Unicode把所有语言统一在一套编码里,但Unicode是不可变长的编码,如果是纯英文的文章保存,占用的存储空间、传输带宽比ascii大一倍;
最终衍生出UTF-8可变长编码
1. ASCII编码:给英文字母,数字,标点,字符转换成计算机能识别的二进制数规定一个大家都认可的标准2
2. GBK编码:是汉字编码(含英文字母,数字,标点,字符部分)标准之一,是在 GB2312-80 标准 基础上的内码扩展规范,使用了双字节编码
3. Unicode编码:覆盖世界上所有字符的编码,最常用的是用 两个字节表示一个字符(如果要用到非常偏僻 的字符,就需要4个字节)
4. UTF-8编码:UTF-8兼容ascii,是可边长的字符串,节省空间和带宽
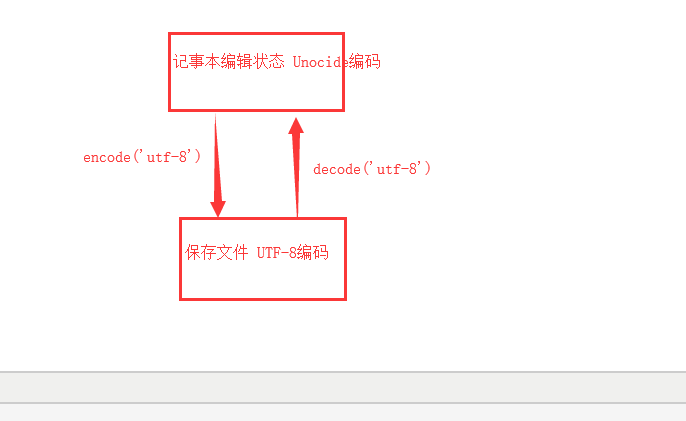
记事本存储-》读取
服务器 -》浏览器