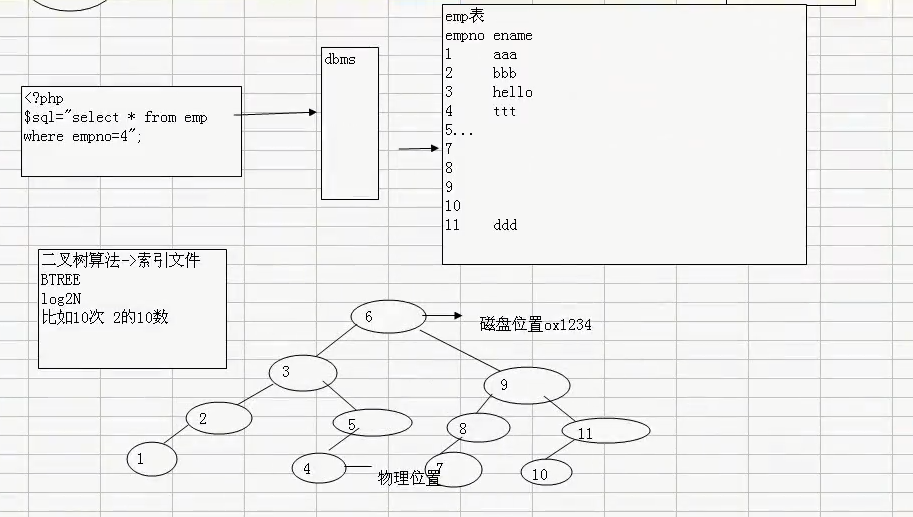
数据库的三层结构
程序----->数据库管理系统----->数据库(文件)
MySQL优化是一个综合性的技术,主要包括
1、表的设计合理化(符合三范式)
2、添加适当的索引(index)[普通索引、主键索引、唯一索引,全文索引]
3、分表技术(水平分割、垂直分割)
4、读写分离
5、存储过程(模块化编程,可以提高速度)
6、对MySQL配置优化(配置最大并发数,调整缓存大小)
7、MySQL服务器硬件升级
8、定时的去清除不需要的数据,定时进行碎片整理(MyISAM)
表达的设计
表的范式,是首先符合1NF,才能满足2NF,进一步满足3NF
1NF:即表的列具有原子性,不可再分解,只要数据库是关系型数据库,就自动满足1NF
2NF:表中的记录是唯一的,就满足2NF,通常我们设计一个主键来实现(一般主键不含业务逻辑,不需要修改,因此数据会比较稳定)
3NF:即表中不要用冗余数据,就是说,表的信息,如果能够被推导出来,就不应该单独设计一个字段来存放
反3F:在表的1对多的情况下,为了提高效率,可能会在1这张表中设计一个字段处理
SQL语句优化一般步骤
1、通过show status命令了解各种SQL的执行频率
show [session|global] status like ...
//如果我们不写[session|global]默认是session会话,指取出当前窗口的执行
//如果想看所有(从MySQL启动到现在,则应该用global)
常用的:
show status like 'uptime'; //当前MySQL运行了多少秒
show status like 'connections'; //mysql当前的连接数
show status like 'slow_queries'; //显示慢查询的次数
show status like 'com_select';
show status like 'com_insert';
show status like 'com_update';
show status like 'com_delete';
2、定位执行效率较低的SQL语句(重点select)
3、通过explain分析低效率的SQL语句的执行情况
4、确定问题并采取响应的措施
定位慢查询
1、构建用来测试的大表
#创建数据库temp
mysql> create database temp;
mysql> use temp;
mysql> set names gbk;
#创建第一张表:部门表
CREATE TABLE dept( /*部门表*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/
dname VARCHAR(20) NOT NULL DEFAULT "", /*名称*/
loc VARCHAR(13) NOT NULL DEFAULT "" /*地点*/
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
#创建第二张表:雇员表
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/
job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*上级编号*/
hiredate DATE NOT NULL,/*入职时间*/
sal DECIMAL(7,2) NOT NULL,/*薪水*/
comm DECIMAL(7,2) NOT NULL,/*红利*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部门编号*/
)ENGINE=MyISAM DEFAULT CHARSET=utf8;
#创建第三张表:工资级别表
CREATE TABLE salgrade
(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
losal DECIMAL(17,2) NOT NULL,
hisal DECIMAL(17,2) NOT NULL
)ENGINE=MyISAM DEFAULT CHARSET=utf8;
#往salgrade表写入测试数据,5个工资级别
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);
#为了存储过程能够正常执行,我们需要把命令执行结束符修改
delimiter $$
#创建一个函数rand_string,可以返回一个随机的字符串
create function rand_string(n INT)
returns varchar(255)
begin
declare chars_str varchar(100)default
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255)default '';
declare i int default 0;
while i < n do
set return_str=concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end $$
#看下自定义的函数功能,返回随机的6位字符串
mysql> select rand_string(6) from dual$$
+----------------+
| rand_string(6) |
+----------------+
| uELShg |
+----------------+
#这里我们又自定了一个函数,返回一个随机的部门号
create function rand_num( )
returns int(5)
begin
declare i int default 0;
set i = floor(10+rand()*500);
return i;
end $$
#定义存储过程,一旦调用就可以往emp雇员表添加数据
#start表示雇员的编号从哪里开始,max_num表示一共增加多少雇员
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i + 1;
insert into emp values ((start+i),rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());
until i = max_num
end repeat;
commit;
end $$
#调用存储过程,往emp雇员表添加1000W条数据,编号从100001开始
call insert_emp(100001,10000000)$$
#命令结束符设置回;
delimiter ;
2、修改my.cnf,开启慢查询
[mysqld]
...
slow_query_log=1 #开启慢查询
long_query_time=1 #默认慢查询时间为10秒,这里修改为1秒
#默认慢日志存放在数据目录,文件名为hostname-slow.log
slow_query_log_file=/var/lib/mysql/slow_query.log
#重启MySQL服务
3、显示慢查询次数,目前为0次
mysql> show status like 'slow_queries';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Slow_queries | 0 |
+---------------+-------+
4、现在执行一条查询语句,可以看到花费了5.33秒,已经超出我们这是的1秒时间
mysql> use temp;
mysql> select * from emp where empno=3092305;
+---------+--------+----------+-----+------------+---------+--------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+---------+--------+----------+-----+------------+---------+--------+--------+
| 3092305 | gbMIey | SALESMAN | 1 | 2018-02-26 | 2000.00 | 400.00 | 29 |
+---------+--------+----------+-----+------------+---------+--------+--------+
1 row in set (5.33 sec)
5、再次显示慢查询次数,已经增加1次了,然后慢查询就会记录到slow_query.log中
索引
看看个例子,有索引和没有索引的查询速度对比
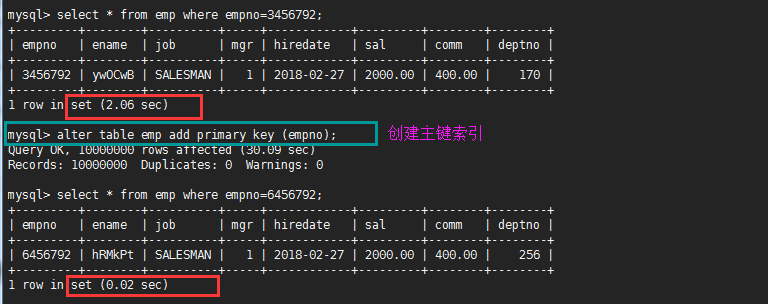
索引为什么会变快?
MySQL有四种索引:主键索引、唯一索引、普通索引、全文索引
主键索引
当一张表中把某个列设为主键,则该列就是主键索引
如果创建表时,没有指定主键,也可以在创建表后再添加,如下指令
alter table 表名 add primary key (列名);
唯一索引
当表的某列被指定为unqiue约束时,这列就是一个唯一索引,如下:name列就是一个唯一索引
create table aaa(id int primary key auto_increment, name varchar(32) unique);
也可以创建表后,再去创建唯一索引
create unique index 索引名 on 表名 (列名);
注意:
unique字段可以为null,并可以有多个null,但是如果是具体的内容,则不能重复
主键字段不能为空,也不能重复
普通索引
一般来说,普通索引的创建,是先创建表,然后创建普通索引,比如:
create table bbb(
id int unsigned,
name varchar(32)
)
create index 索引名 on 表
全文索引
全文索引,主要针对文本的检索,比如文章,在MySQL中fulltext索引只针对myisam生效
索引的代价
1、磁盘占用
2、对dml(update, delete, insert)语句的效率有影响
查询索引
show index from 表名
删除索引
drop index 索引名 on 表名
修改索引
先删除,再重新创建
哪些列上适合添加索引?
1、where条件经常使用的字段,不会出现的where子句中字段不该创建索引
2、该字段的内容不是唯一的几个值,比如性别就只有男女
3、字段内容不是经常变化的,比如文件点击次数
索引注意事项:
1、对于创建的多列索引,只要查询条件使用最左边的列,索引一般会被使用
2、对于like的查询,查询如果是‘%aaa’不会使用到索引,‘aaa%’会使用
3、如果条件中有or,要求条件中的字段都带索引,否则不使用索引
4、如果列类型是字符串,那一定要在条件中将数据使用引号引起来,否则不使用索引
5、如果MySQL估计使用全表扫描要比使用索引快,则不使用索引
查看索引的使用情况
show status like 'handler_read%';
handler_read_key 这个值越高越好,越高表示使用索引查询到次数
handler_read_rnd_next: 这个值越高,说明查询低效
选择合适的存储引擎
myisam : 如果表对事务要求不高,同时是以查询和添加为主的,我们考虑使用myisam
innodb: 对事务要求高,保存的数据都是重要数据,建议使用innodb
碎片整理
对于你存储引擎是myisam的数据库,如果经常做删除和修改的操作,一定要定时执行optimize table table_name;功能对表进行碎片整理
SQL语句的小技巧
1、优化group by语句
默认情况下,MySQL对所有的group by col1,col2进行排序。这与在查询中指定order by col1,col2类似。
如果查询中包括group by,但用想要避免排序结果的小号,则可以使用order by null禁止排序
select * from dept group by dname order by null
2、有些情况下,可以使用连接来代替子查询
因为使用join, MySQL不需要再内存中创建临时表
select * from dept, emp where dept.deptno =emp.deptno; [简单处理方式]
select * from dept left join emp on dept.deptno=emp.deptno; 【左外连接,更OK】