原网址:https://blog.csdn.net/c406495762/article/details/58716886

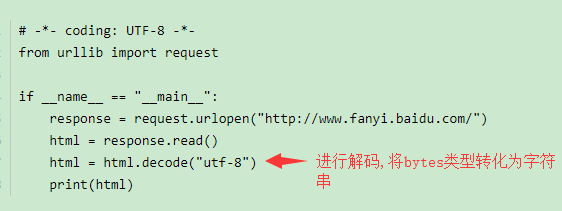


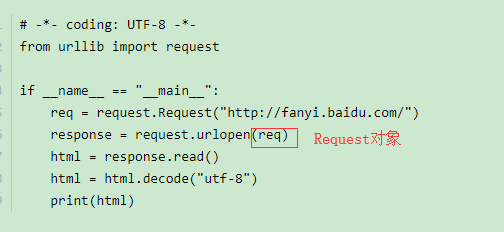

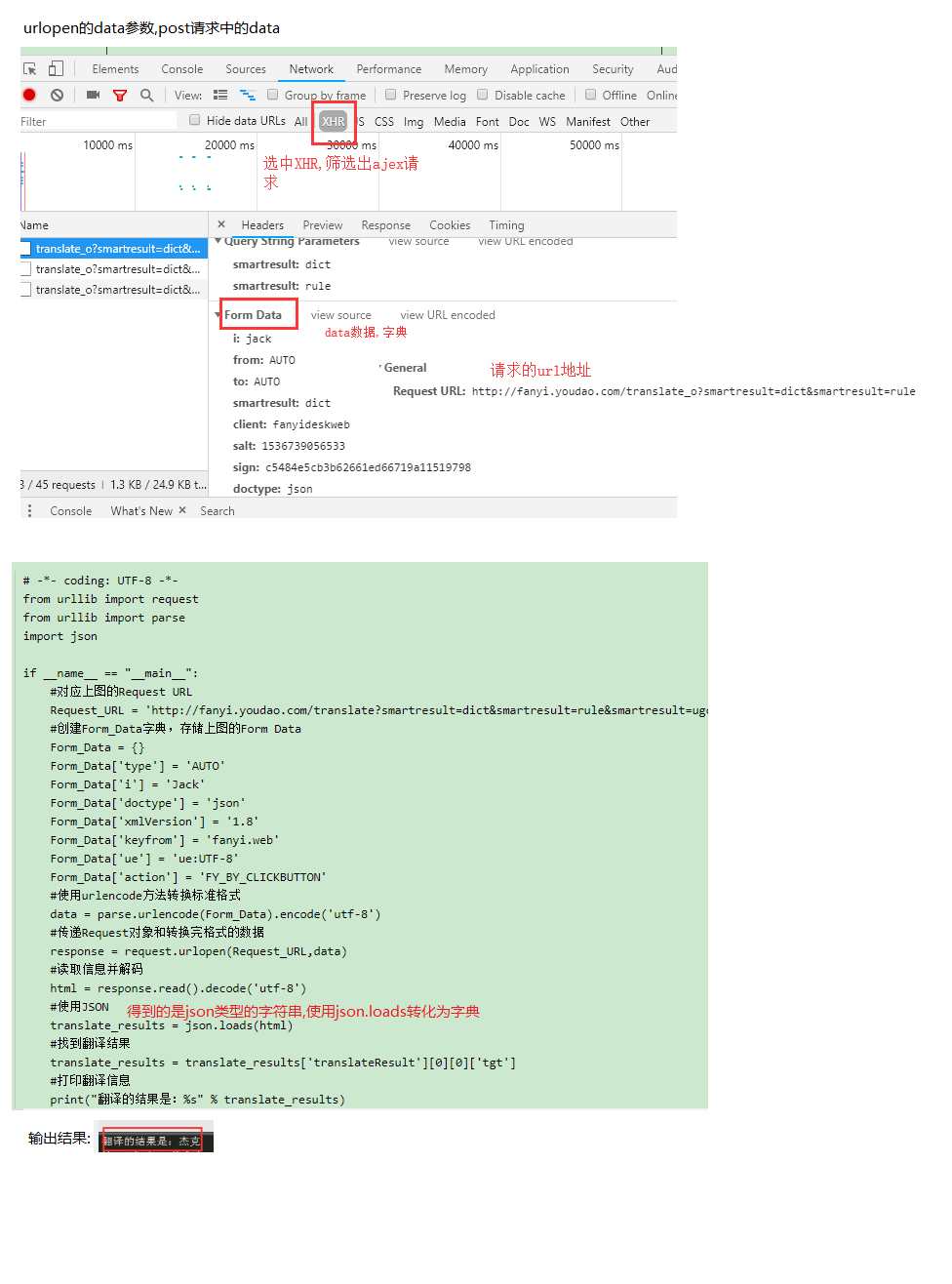

使用User Agent和代理IP隐藏身份
User Agent存放于Headers中,保存中访问设备的信息,服务器就是通过查看Headers中的User Agent来判断是谁在访问,通过修改User Agent模拟浏览器设备
常见的User Agent
1.Android
- Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19
- Mozilla/5.0 (Linux; U; Android 4.0.4; en-gb; GT-I9300 Build/IMM76D) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30
- Mozilla/5.0 (Linux; U; Android 2.2; en-gb; GT-P1000 Build/FROYO) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1
2.Firefox
- Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0
- Mozilla/5.0 (Android; Mobile; rv:14.0) Gecko/14.0 Firefox/14.0
3.Google Chrome
- Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36
- Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19
4.iOS
- Mozilla/5.0 (iPad; CPU OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A334 Safari/7534.48.3
- Mozilla/5.0 (iPod; U; CPU like Mac OS X; en) AppleWebKit/420.1 (KHTML, like Gecko) Version/3.0 Mobile/3A101a Safari/419.3
上面列举了Andriod、Firefox、Google Chrome、iOS的一些User Agent,直接copy就能用。
想要设置User Agent,有两种方法:
1.在创建Request对象的时候,填入headers参数(包含User Agent信息),这个Headers参数要求为字典;
2.在创建Request对象的时候不添加headers参数,在创建完成之后,使用add_header()的方法,添加headers。
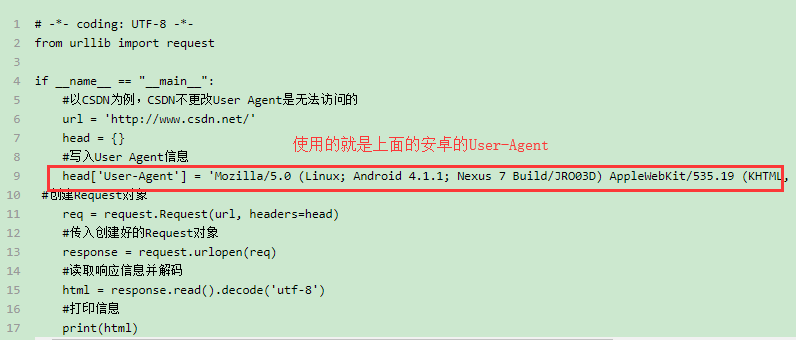

IP代理的使用
(1)调用urlib.request.ProxyHandler(),proxies参数为一个字典。
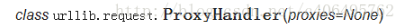
(2)创建Opener(类似于urlopen,这个代开方式是我们自己定制的)

(3)安装Opener

使用install_opener方法之后,会将程序默认的urlopen方法替换掉。也就是说,如果使用install_opener之后,在该文件中,再次调用urlopen会使用自己创建好的opener。如果不想替换掉,只是想临时使用一下,可以使用opener.open(url),这样就不会对程序默认的urlopen有影响。
3.代理IP选取
在写代码之前,先在代理IP网站选好一个IP地址,推荐西刺代理IP。

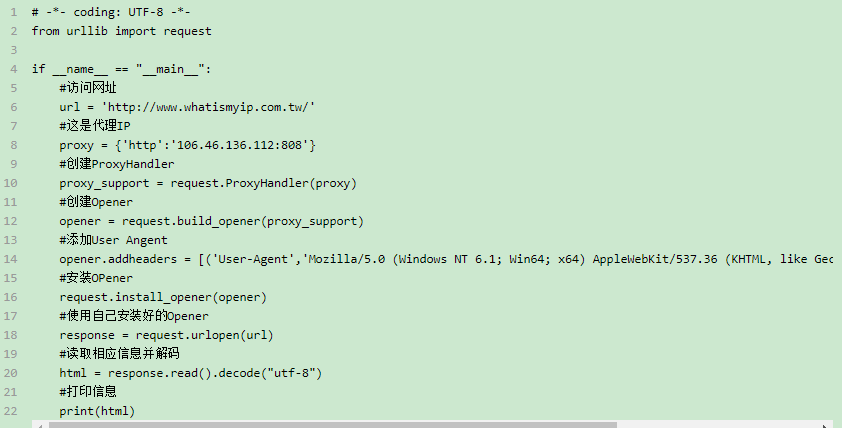
注意:上面代码中的网站已经不能访问了,换一个其他的网站https://www.ipip.net/ip.html,不知道为什么我运行后ip还是本机ip不知道哪出问题了


soup = BeautifulSoup(html)
爬取小说


# -*- coding:UTF-8 -*- from bs4 import BeautifulSoup import requests if __name__ == "__main__": target = 'http://www.biqukan.com/1_1094/5403177.html' req = requests.get(url = target) html = req.text bf = BeautifulSoup(html) texts = bf.find_all('div', class_ = 'showtxt') #将xa0无法解码的字符删除 print(texts[0].text.replace('xa0'*8,' '))
# -*- coding:UTF-8 -*- from bs4 import BeautifulSoup import requests if __name__ == "__main__": server = 'http://www.biqukan.com/' target = 'http://www.biqukan.com/1_1094/' req = requests.get(url = target) html = req.text div_bf = BeautifulSoup(html) div = div_bf.find_all('div', class_ = 'listmain') a_bf = BeautifulSoup(str(div[0])) a = a_bf.find_all('a') for each in a: print(each.string, server + each.get('href'))
# -*- coding:UTF-8 -*- from bs4 import BeautifulSoup import requests, sys """ 类说明:下载《笔趣看》网小说《一念永恒》 Parameters: 无 Returns: 无 Modify: 2017-09-13 """ class downloader(object): def __init__(self): self.server = 'http://www.biqukan.com/' self.target = 'http://www.biqukan.com/1_1094/' self.names = [] #存放章节名 self.urls = [] #存放章节链接 self.nums = 0 #章节数 """ 函数说明:获取下载链接 Parameters: 无 Returns: 无 Modify: 2017-09-13 """ def get_download_url(self): req = requests.get(url = self.target) html = req.text div_bf = BeautifulSoup(html) div = div_bf.find_all('div', class_ = 'listmain') a_bf = BeautifulSoup(str(div[0])) a = a_bf.find_all('a') self.nums = len(a[15:]) #剔除不必要的章节,并统计章节数 for each in a[15:]: self.names.append(each.string) self.urls.append(self.server + each.get('href')) """ 函数说明:获取章节内容 Parameters: target - 下载连接(string) Returns: texts - 章节内容(string) Modify: 2017-09-13 """ def get_contents(self, target): req = requests.get(url = target) html = req.text bf = BeautifulSoup(html) texts = bf.find_all('div', class_ = 'showtxt') texts = texts[0].text.replace('xa0'*8,' ') return texts """ 函数说明:将爬取的文章内容写入文件 Parameters: name - 章节名称(string) path - 当前路径下,小说保存名称(string) text - 章节内容(string) Returns: 无 Modify: 2017-09-13 """ def writer(self, name, path, text): write_flag = True with open(path, 'a', encoding='utf-8') as f: f.write(name + ' ') f.writelines(text) f.write(' ') if __name__ == "__main__": dl = downloader() dl.get_download_url() print('《一年永恒》开始下载:') for i in range(dl.nums): dl.writer(dl.names[i], '一念永恒.txt', dl.get_contents(dl.urls[i])) sys.stdout.write(" 已下载:%.3f%%" % float(i/dl.nums) + ' ') sys.stdout.flush() print('《一年永恒》下载完成')
