Memcached是高性能的分布式内存缓存服务器。它的主要目的不是基于本地缓存的,而主要用在分布式系统中。Memcached中保存的数据都存储在Memcached内置的内存存储空间中。由于数据仅存在于内存中,因此重启Memcached、重启操作系统会导致全部数据消失。Memcached是记录级的缓存,之前调研报告里提到过与MySQL、Server等页级缓存会缓存无效数据的,记录级的缓存则使内存利用率更高。

一、Memcached的内存管理方式
memcached默认情况下采用了Slab Allocator的机制分配、管理内存。在该机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free来进行的。但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,Slab Allocator就是为解决该问题而诞生的。
SlabAllocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块,以完全解决内存碎片问题。下面我会介绍内存分配过程。

Memcached将内存分成多个slab,每个slab是一次申请内存的最小单位(大小为1M不过好像可以设置),slab内部又分为若干个chunk。chunk的大小分为很多种,以80字节为初始大小(称为id-0的slab),第二类大小为第一类的f倍(f为参数可调,称这类为id-1的slab),随id递增每一类比上一类的chunk大小大f倍。所以一个chunk最大只可能为1M。每个chunk里包含了一个item结构体(key和value),用来存放缓存数据。chunk大小相同的已分配空间的slab组成一个链表,所有的slab链表都保存在一个slabclass的数组上(相当于二维链表),每一种slab在初始化时默认都会创建一个。
二、Memcached缓存记录的原理
memcached接收到一条记录时,首先会知道item的大小,然后就会在slabclass数组上去找能包含这个item的最小的chunk的slab链表(由于memcached的各链表之间chunk大小的倍数关系,可以快速定位到链表的起始位置),找到空闲的chunk缓存这条记录。当一个slab的chunk都用完,则新申请新的slab用来存item,申请的slab的大小是倍数变化的(和std::vector一样),链表大小由1变2,由2变4、8、16……如果空间已满,不能申请更多slab,则按照LRU原则,将空间分配给新的记录。

三、Memcached的内存浪费
memcached的内存主要表现有以下三处:
1、一个slab分配1M空间,而slab中所有chunks大小加起来可能到不了1M;
2、每类slab在初始化时默认都会创建一个,但是如果这类slab从未被使用过,则这1M就浪费了;
3、一个item的大小总是不大于chunk大小的,当小于时则发生内存冗余。
第一类可以通过参数调优尽量减少这种内存冗余,第二类应该也可以减少,第三类看起来就不太少避免。
四、Memcached的分布式算法

Memcached的服务器端主要是用来记录缓存和读取,而分布式算法即选择哪台服务器来寻找数据/写入内存则由客户端程序库实现。方法是用Consistent Hash。
ConsistentHashing如下所示:首先求出memcached服务器(节点)的哈希值(memcached用CRC计算哈希值),并将其配置到0-232的圆上。然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。

从上图的状态中添加一台memcached服务器。传统的取模算法会使大量的键不能哈希到之前缓存的服务器上,但Consistent Hashing中,只有在增加服务器的地点逆时针方向的第一台服务器上的键会受到影响(如下图)。
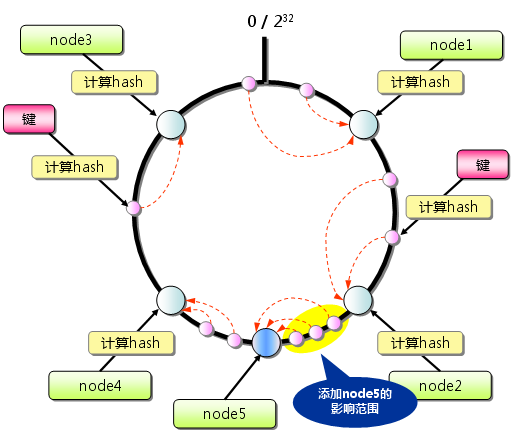
因此,Consistent Hashing最大限度地抑制了键的重新分布。有的ConsistentHashing的实现方法还采用了虚拟节点的思想。使用一般的hash函数的话,服务器的映射地点的分布非常不均匀。因此,使用虚拟节点的思想,为每个物理节点(服务器)在continuum上分配100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。
(转载本文请注明出处: http://blog.csdn.net/jiang1st2010/article/details/8121361)