一、面向对象编程
在Python中,所有数据类型都可以视为对象,当然也可以自定义对象。自定义的对象数据类型就是面向对象中的类(Class)的概念。
面向对象的设计思想是抽象出Class,根据Class创建Instance。
面向对象的抽象程度又比函数要高,因为一个Class既包含数据,又包含操作数据的方法。
类和实例
定义如下:
class Student(object): def __init__(self, name, score): self.name = name self.score = score
class后面紧接着是类名,即Student,类名通常是大写开头的单词,紧接着是(object),表示该类是从哪个类继承下来的,继承的概念我们后面再讲,通常,如果没有合适的继承类,就使用object类,这是所有类最终都会继承的类。
创建实例是通过类名+()实现的:bart=Student()
可以自由地给一个实例变量绑定属性。
和静态语言不同,Python允许对实例变量绑定任何数据,也就是说,对于两个实例变量,虽然它们都是同一个类的不同实例,但拥有的变量名称都可能不同。
比如,给实例bart绑定一个name属性:
>>> bart.name = 'Bart Simpson' >>> bart.name 'Bart Simpson'
在创建实例的时候,可以将属性绑定,是通过特殊方法 __init__ (前后分别有两个下划线)。
注意到__init__方法的第一个参数永远是self,表示创建的实例本身,因此,在__init__方法内部,就可以把各种属性绑定到self,因为self就指向创建的实例本身。
有了__init__方法,在创建实例的时候,就不能传入空的参数了,必须传入与__init__方法匹配的参数,但self不需要传,Python解释器自己会把实例变量传进去:
>>> bart = Student('Bart Simpson', 59) >>> bart.name 'Bart Simpson' >>> bart.score 59
数据封装
外部不直接访问类中的属性,而是通过类中的方法来间接访问。
class Student(object): def __init__(self, name, score): self.name = name self.score = score def print_score(self): print('%s: %s' % (self.name, self.score))
要定义一个方法,除了第一个参数是self外,其他和普通函数一样。要调用一个方法,只需要在实例变量上直接调用,除了self不用传递,其他参数正常传入。
这样一来,我们从外部看Student类,就只需要知道,创建实例需要给出name和score,而如何打印,都是在Student类的内部定义的,这些数据和逻辑被“封装”起来了,调用很容易,但却不用知道内部实现的细节。
访问限制
在Class内部,可以有属性和方法,而外部代码可以通过直接调用实例变量的方法来操作数据,这样,就隐藏了内部的复杂逻辑。
如果要让内部属性不被外部访问,可以把属性的名称前加上两个下划线__,在Python中,实例的变量名如果以__开头,就变成了一个私有变量(private),只有内部可以访问,外部不能访问,
需要注意的是,在Python中,变量名类似__xxx__的,也就是以双下划线开头,并且以双下划线结尾的,是特殊变量,特殊变量是可以直接访问的,不是private变量,所以,不能用__name__、__score__这样的变量名。
继承和多态
继承有什么好处?
最大的好处是子类获得了父类的全部功能。
当子类和父类都存在相同的run()方法时,我们说,子类的run()覆盖了父类的run(),在代码运行的时候,总是会调用子类的run()。这样,我们就获得了继承的另一个好处:多态。
多态:
在继承关系中,如果一个实例的数据类型是某个子类,那它的数据类型也可以被看做是父类。但是,反过来就不行。eg:狗 是动物,但动物不能说是狗
多态真正的威力:【将父类作为参数传入一个方法后】调用方只管调用,不管细节,而当我们新增一种Animal的子类时,只要确保run()方法编写正确,不用管原来的代码是如何调用的。这就是著名的“开闭”原则:对新增子类开放,对修改父类的函数关闭。
获取对象信息
一、判断对象的类型:
1、用Type()函数,判断是否基本类型(int、str): type(123)==int
2、用Types模块中定义的常量(types.FunctionType、types.BuiltinFunctionType),判断一个对象是否是函数: type(abs)==types.BuiltinFunctionType
3、使用isinstance():判断的是一个对象是否是该类型本身,或者位于该类型的父继承链上。
总是优先使用isinstance()判断类型,可以将指定类型及其子类“一网打尽”。
二、获得一个对象的所有属性和方法:
使用dir()函数,它返回一个包含字符串的list,比如,获得一个str对象的所有属性和方法:
>>> dir('ABC')
['__add__', '__class__',..., '__subclasshook__', 'capitalize', 'casefold',..., 'zfill']仅仅把属性和方法列出来是不够的,配合getattr()、setattr()以及hasattr(),我们可以直接操作一个对象的状态。
实例属性与类属性
- 实例属性属于各个实例所有,互不干扰;
- 类属性属于类所有,所有实例共享一个属性;
在编写程序的时候,千万不要对实例属性和类属性使用相同的名字,因为相同名称的实例属性将屏蔽掉类属性,但是当你删除实例属性后,再使用相同的名称,访问到的将是类属性。
二、网络编程
用Python进行网络编程,就是在Python程序本身这个进程内,连接别的服务器进程的通信端口进行通信。
TCP/IP协议
互联网协议包含了上百种协议标准,但是最重要的两个协议是TCP和IP协议,所以,大家把互联网的协议简称TCP/IP协议。
通信的时候,双方必须知道对方的标识,好比发邮件必须知道对方的邮件地址。互联网上每个计算机的唯一标识就是IP地址,类似123.123.123.123。如果一台计算机同时接入到两个或更多的网络,比如路由器,它就会有两个或多个IP地址,所以,IP地址对应的实际上是计算机的网络接口,通常是网卡。
IP协议负责把数据从一台计算机通过网络发送到另一台计算机。数据被分割成一小块一小块,然后通过IP包发送出去。由于互联网链路复杂,两台计算机之间经常有多条线路,因此,路由器就负责决定如何把一个IP包转发出去。IP包的特点是按块发送,途径多个路由,但不保证能到达,也不保证顺序到达。
TCP协议则是建立在IP协议之上的。TCP协议负责在两台计算机之间建立可靠连接,保证数据包按顺序到达。TCP协议会通过握手建立连接,然后,对每个IP包编号,确保对方按顺序收到,如果包丢掉了,就自动重发。
许多常用的更高级的协议都是建立在TCP协议基础上的,比如用于浏览器的HTTP协议、发送邮件的SMTP协议等。
一个TCP报文除了包含要传输的数据外,还包含源IP地址和目标IP地址,源端口和目标端口。
端口有什么作用?在两台计算机通信时,只发IP地址是不够的,因为同一台计算机上跑着多个网络程序。一个TCP报文来了之后,到底是交给浏览器还是QQ,就需要端口号来区分。每个网络程序都向操作系统申请唯一的端口号,这样,两个进程在两台计算机之间建立网络连接就需要各自的IP地址和各自的端口号。
一个进程也可能同时与多个计算机建立链接,因此它会申请很多端口。
TCP编程
客户端
大多数连接都是可靠的TCP连接。创建TCP连接时,主动发起连接的叫客户端,被动响应连接的叫服务器。
举个例子,通过Socket向百度发请求


import socket s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.connect(('www.baidu.com',80)) # 发送数据: s.send(b'GET / HTTP/1.1 Host: www.baidu.com Connection: close ') # 接收数据: buffer = [] while True: # 每次最多接收1k字节: d = s.recv(1024) if d: buffer.append(d) else: break data = b''.join(buffer) # 关闭连接: s.close() header, html = data.split(b' ', 1) print(header.decode('utf-8')) # 把接收的数据写入文件: with open('baidu.html', 'wb') as f: f.write(html)
解释:
创建Socket时,AF_INET指定使用IPv4协议,如果要用更先进的IPv6,就指定为AF_INET6。SOCK_STREAM指定使用面向流的TCP协议
客户端要主动发起TCP连接,必须知道服务器的IP地址和端口号,参数是一个tuple
TCP连接创建的是双向通道,双方都可以同时给对方发数据。但是谁先发谁后发,怎么协调,要根据具体的协议来决定。例如,HTTP协议规定客户端必须先发请求给服务器,服务器收到后才发数据给客户端。
发送的文本格式必须符合HTTP标准,如果格式没问题,接下来就可以接收服务器返回的数据了。
接收数据时,调用recv(max)方法,一次最多接收指定的字节数,因此,在一个while循环中反复接收,直到recv()返回空数据,表示接收完毕,退出循环。
接收完数据后,调用close()方法关闭Socket,这样,一次完整的网络通信就结束了。接收到的数据包括HTTP头和网页本身,我们只需要把HTTP头和网页分离一下,把HTTP头打印出来,网页内容保存到文件。
服务器
服务器进程首先要绑定一个端口并监听来自其他客户端的连接。如果某个客户端连接过来了,服务器就与该客户端建立Socket连接,随后的通信就靠这个Socket连接了。
所以,服务器会打开固定端口(比如80)监听,每来一个客户端连接,就创建该Socket连接。由于服务器会有大量来自客户端的连接,所以,服务器要能够区分一个Socket连接是和哪个客户端绑定的。一个Socket依赖4项:服务器地址、服务器端口、客户端地址、客户端端口来唯一确定一个Socket。
但是服务器还需要同时响应多个客户端的请求,所以,每个连接都需要一个新的进程或者新的线程来处理,否则,服务器一次就只能服务一个客户端了。
我们来编写一个简单的服务器程序,它接收客户端连接,把客户端发过来的字符串加上Hello再发回去。
服务端
import socket import threading import time # 连接建立后,服务器首先发一条欢迎消息,然后等待客户端数据,并加上Hello再发送给客户端。如果客户端发送了exit字符串,就直接关闭连接。 def tcplink(sock, addr): print('Accept new connection from %s:%s...' % addr) sock.send(b'Welcome!') while True: data = sock.recv(1024) time.sleep(1) if not data or data.decode('utf-8') == 'exit': break sock.send(('Hello, %s!' % data.decode('utf-8')).encode('utf-8')) sock.close() print('Connection from %s:%s closed.' % addr) s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) # 请注意,小于1024的端口号必须要有管理员权限才能绑定 s.bind(('127.0.0.1',9999)) # 指定等待连接的最大数量 s.listen(5) print('Waiting for connection...') while True: # 接受一个新连接: sock, addr = s.accept() # 创建新线程来处理TCP连接: t = threading.Thread(target=tcplink, args=(sock, addr)) t.start()
客户端
import socket s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 建立连接: s.connect(('127.0.0.1', 9999)) # 接收欢迎消息: print(s.recv(1024).decode('utf-8')) for data in [b'Michael', b'Tracy', b'Sarah']: # 发送数据: s.send(data) print(s.recv(1024).decode('utf-8')) s.send(b'exit') s.close()
需要打开两个命令行窗口,一个运行服务器程序,另一个运行客户端程序,就可以看到效果了 。
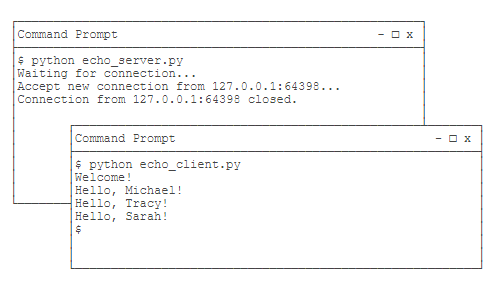
需要注意的是,客户端程序运行完毕就退出了,而服务器程序会永远运行下去,必须按Ctrl+C退出程序。
三、Web开发
Python的诞生历史比Web还要早,由于Python是一种解释型的脚本语言,开发效率高,所以非常适合用来做Web开发。
Python有上百种Web开发框架,有很多成熟的模板技术,选择Python开发Web应用,不但开发效率高,而且运行速度快。
一个Web应用的本质就是:
-
浏览器发送一个HTTP请求;
-
服务器收到请求,生成一个HTML文档;
-
服务器把HTML文档作为HTTP响应的Body发送给浏览器;
-
浏览器收到HTTP响应,从HTTP Body取出HTML文档并显示。
最简单的Web应用就是先把HTML用文件保存好,用一个现成的HTTP服务器软件,接收用户请求,从文件中读取HTML,返回。Apache、Nginx、Lighttpd等这些常见的静态服务器就是干这件事情的。
做法是底层代码由专门的服务器软件实现,我们用Python专注于生成HTML文档。因为我们不希望接触到TCP连接、HTTP原始请求和响应格式,所以,需要一个统一的接口,让我们专心用Python编写Web业务。
这个接口就是WSGI:Web Server Gateway Interface。
WSGI
WSGI接口定义非常简单,它只要求Web开发者实现一个函数,就可以响应HTTP请求。我们来看一个最简单的Web版本的“Hello, web!”:
def application(environ, start_response): start_response('200 OK', [('Content-Type', 'text/html')]) return [b'<h1>Hello, web!</h1>']
上面的application()函数就是符合WSGI标准的一个HTTP处理函数,它接收两个参数:
-
environ:一个包含所有HTTP请求信息的
dict对象; -
start_response:一个发送HTTP响应的函数,只能调一次。
函数的返回值b'<h1>Hello, web!</h1>'将作为HTTP响应的Body发送给浏览器。
有了WSGI,我们关心的就是如何从environ这个dict对象拿到HTTP请求信息,然后构造HTML,通过start_response()发送Header,最后返回Body。
整个application()函数本身没有涉及到任何解析HTTP的部分,也就是说,底层代码不需要我们自己编写,我们只负责在更高层次上考虑如何响应请求就可以了。
不过,等等,这个application()函数怎么调用?如果我们自己调用,两个参数environ和start_response我们没法提供,返回的bytes也没法发给浏览器。
所以application()函数必须由WSGI服务器来调用。有很多符合WSGI规范的服务器,我们可以挑选一个来用。但是现在,我们只想尽快测试一下我们编写的application()函数真的可以把HTML输出到浏览器,所以,要赶紧找一个最简单的WSGI服务器,把我们的Web应用程序跑起来。
好消息是Python内置了一个WSGI服务器,这个模块叫wsgiref,它是用纯Python编写的WSGI服务器的参考实现。所谓“参考实现”是指该实现完全符合WSGI标准,但是不考虑任何运行效率,仅供开发和测试使用。
hello.py
def application(environ,start_response): start_response('200 OK', [('Content-Type', 'text/html')]) #return [b'<h1>Hello, web!</h1>'] #改造一下 body = '<h1>Hello, %s!</h1>' % (environ['PATH_INFO'][1:] or 'web') return [body.encode('utf-8')]
server.py
# 从WSgiref模板导入 from wsgiref.simple_server import make_server # 导入我们编写的application函数 from hello import application # 创建一个服务器,IP地址为空,端口是8000,处理函数是application: httpd = make_server('', 8000, application) print('Serving HTTP on port 8000...') # 开始监听HTTP请求: httpd.serve_forever()
执行server.py,然后打开浏览器:http://localhost:8000/ 或者 http://localhost:8000/huy
无论多么复杂的Web应用程序,入口都是一个WSGI处理函数。HTTP请求的所有输入信息都可以通过environ获得,HTTP响应的输出都可以通过start_response()加上函数返回值作为Body。
复杂的Web应用程序,光靠一个WSGI函数来处理还是太底层了,我们需要在WSGI之上再抽象出Web框架,进一步简化Web开发。
使用Web框架
用Python开发一个Web框架十分容易,所以Python有上百个开源的Web框架。这里我们先不讨论各种Web框架的优缺点,直接选择一个比较流行的Web框架——Flask来使用。
先用pip安装Flask: pip install flask
然后写一个xxx.py,处理3个URL,分别是:
-
GET /:首页,返回Home; -
GET /signin:登录页,显示登录表单; -
POST /signin:处理登录表单,显示登录结果。
注意噢,同一个URL/signin分别有GET和POST两种请求,映射到两个处理函数中。
Flask通过Python的装饰器在内部自动地把URL和函数给关联起来,
from flask import Flask from flask import request app = Flask(__name__) @app.route('/',methods=['GET','POST']) def home(): return '<h1>home page</h1>' @app.route('/signin',methods=['GET']) def signin_form(): return '''<form action="/signin" method="post"> <p><input name="username"></p> <p><input name="password" type="password"></p> <p><button type="submit">Sign In</button></p> </form>''' @app.route('/signin', methods=['POST']) def signin(): # 需要从request对象读取表单内容: if request.form['username']=='admin' and request.form['password']=='password': return '<h3>Hello, admin!</h3>' return '<h3>Bad username or password.</h3>' if __name__ == '__main__': app.run()
Flask自带的Server在端口5000上监听,输入首页地址http://localhost:5000/:
再输入 http://localhost:5000/signin
输入预设的用户名admin和口令password,登录成功。。输个错误密码试试。。
实际的Web App应该拿到用户名和口令后,去数据库查询再比对,来判断用户是否能登录成功。
除了Flask,常见的Python Web框架还有:
当然了,因为开发Python的Web框架也不是什么难事,我们后面也会讲到开发Web框架的内容。
有了Web框架,我们在编写Web应用时,注意力就从WSGI处理函数转移到URL+对应的处理函数,这样,编写Web App就更加简单了。
在编写URL处理函数时,除了配置URL外,从HTTP请求拿到用户数据也是非常重要的。Web框架都提供了自己的API来实现这些功能。Flask通过request.form['name']来获取表单的内容。
使用模板
使用模板,我们需要预先准备一个HTML文档,这个HTML文档不是普通的HTML,而是嵌入了一些变量和指令,然后,根据我们传入的数据,替换后,得到最终的HTML,发送给用户:
这就是传说中的MVC:Model-View-Controller,中文名“模型-视图-控制器”。
Python处理URL的函数就是C:Controller,Controller负责业务逻辑,比如检查用户名是否存在,取出用户信息等等;
包含变量{{ name }}的模板就是V:View,View负责显示逻辑,通过简单地替换一些变量,View最终输出的就是用户看到的HTML。
MVC中的Model在哪?Model是用来传给View的,这样View在替换变量的时候,就可以从Model中取出相应的数据。
上面的例子中,Model就是一个dict:{ 'name': 'Michael' }
只是因为Python支持关键字参数,很多Web框架允许传入关键字参数,然后,在框架内部组装出一个dict作为Model。
现在,我们把上次直接输出字符串作为HTML的例子用高端大气上档次的MVC模式改写一下:
from flask import Flask, request, render_template app = Flask(__name__) @app.route('/', methods=['GET', 'POST']) def home(): return render_template('home.html') @app.route('/signin', methods=['GET']) def signin_form(): return render_template('form.html') @app.route('/signin', methods=['POST']) def signin(): username = request.form['username'] password = request.form['password'] if username=='admin' and password=='password': return render_template('signin-ok.html', username=username) return render_template('form.html', message='Bad username or password', username=username) if __name__ == '__main__': app.run()
Flask通过render_template()函数来实现模板的渲染。和Web框架类似,Python的模板也有很多种。Flask默认支持的模板是jinja2,所以我们先直接安装jinja2:
$ pip install jinja2
然后,开始编写jinja2模板:
home.html 用来显示首页的模板: <html> <head> <title>Home</title> </head> <body> <h1 style="font-style:italic">Home</h1> </body> </html> form.html 用来显示登录表单的模板: <html> <head> <title>Please Sign In</title> </head> <body> {% if message %} <p style="color:red">{{ message }}</p> {% endif %} <form action="/signin" method="post"> <legend>Please sign in:</legend> <p><input name="username" placeholder="Username" value="{{ username }}"></p> <p><input name="password" placeholder="Password" type="password"></p> <p><button type="submit">Sign In</button></p> </form> </body> </html> signin-ok.html 登录成功的模板: <html> <head> <title>Welcome, {{ username }}</title> </head> <body> <p>Welcome, {{ username }}!</p> </body> </html>
登录失败的模板呢?我们在form.html中加了一点条件判断,把form.html重用为登录失败的模板。
最后,一定要把模板放到正确的templates目录下,templates和app.py在同级目录下:
启动:http://localhost:5000/ 再输入 http://localhost:5000/signin
在Jinja2模板中,我们用{{ name }}表示一个需要替换的变量。很多时候,还需要循环、条件判断等指令语句,在Jinja2中,用{% ... %}表示指令。
比如循环输出页码:
{% for i in page_list %}
<a href="/page/{{ i }}">{{ i }}</a>
{% endfor %}
如果page_list是一个list:[1, 2, 3, 4, 5],上面的模板将输出5个超链接。
除了Jinja2,常见的模板还有:
-
Mako:用
<% ... %>和${xxx}的一个模板; -
Cheetah:也是用
<% ... %>和${xxx}的一个模板; -
Django:Django是一站式框架,内置一个用
{% ... %}和{{ xxx }}的模板。
四、异步IO
CPU的速度远远快于磁盘、网络等IO。在一个线程中,CPU执行代码的速度极快,然而,一旦遇到IO操作,如读写文件、发送网络数据时,就需要等待IO操作完成,才能继续进行下一步操作。这种情况称为同步IO。
因为一个IO操作就阻塞了当前线程,导致其他代码无法执行,所以我们必须使用多线程或者多进程来并发执行代码,为多个用户服务。每个用户都会分配一个线程,如果遇到IO导致线程被挂起,其他用户的线程不受影响。
多线程和多进程的模型虽然解决了并发问题,但是系统不能无上限地增加线程。由于系统切换线程的开销也很大,所以,一旦线程数量过多,CPU的时间就花在线程切换上了,真正运行代码的时间就少了,结果导致性能严重下降。
由于我们要解决的问题是CPU高速执行能力和IO设备的龟速严重不匹配,多线程和多进程只是解决这一问题的一种方法。
另一种解决IO问题的方法是异步IO。当代码需要执行一个耗时的IO操作时,它只发出IO指令,并不等待IO结果,然后就去执行其他代码了。一段时间后,当IO返回结果时,再通知CPU进行处理。
异步IO模型需要一个消息循环,在消息循环中,主线程不断地重复“读取消息-处理消息”这一过程
协程
又称微线程,纤程。英文名Coroutine。
子程序,或者称为函数,在所有语言中都是层级调用,比如A调用B,B在执行过程中又调用了C,C执行完毕返回,B执行完毕返回,最后是A执行完毕。所以子程序调用是通过栈实现的,一个线程就是执行一个子程序。
子程序调用总是一个入口,一次返回,调用顺序是明确的。而协程的调用和子程序不同。
协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行(不是函数调用,有点类似CPU的中断)。
特点
协程的特点在于是一个线程执行,那和多线程比,协程有何优势?
最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
Python对协程的支持是通过generator(生成器)实现的。
注:如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator。。遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
在generator中,我们不但可以通过for循环来迭代,还可以不断调用next()函数获取由yield语句返回的下一个值。
但是Python的yield不但可以返回一个值,它还可以接收调用者发出的参数。
asyncio异步io
asyncio的编程模型就是一个消息循环。我们从asyncio模块中直接获取一个EventLoop的引用,然后把需要执行的协程扔到EventLoop中执行,就实现了异步IO。
用asyncio实现Hello world代码如下:
import asyncio @asyncio.coroutine def hello(): print("Hello world!") # 异步调用asyncio.sleep(1): r = yield from asyncio.sleep(1) print("Hello again!") # 获取EventLoop: loop = asyncio.get_event_loop() # 执行coroutine loop.run_until_complete(hello()) loop.close()
@asyncio.coroutine把一个generator标记为coroutine类型(协程),然后,我们就把这个coroutine扔到EventLoop中执行。
hello()会首先打印出Hello world!,然后,yield from语法可以让我们方便地调用另一个generator。由于asyncio.sleep()也是一个coroutine,所以线程不会等待asyncio.sleep(),而是直接中断并执行下一个消息循环。当asyncio.sleep()返回时,线程就可以从yield from拿到返回值(此处是None),然后接着执行下一行语句。
把asyncio.sleep(1)看成是一个耗时1秒的IO操作,在此期间,主线程并未等待,而是去执行EventLoop中其他可以执行的coroutine了,因此可以实现并发执行。
用asyncio的异步网络连接来获取sina、sohu和163的网站首页:
import asyncio @asyncio.coroutine def wget(host): print('wget %s...' % host) connect = asyncio.open_connection(host, 80) reader, writer = yield from connect header = 'GET / HTTP/1.0 Host: %s ' % host writer.write(header.encode('utf-8')) yield from writer.drain() while True: line = yield from reader.readline() if line == b' ': break print('%s header > %s' % (host, line.decode('utf-8').rstrip())) # Ignore the body, close the socket writer.close() loop = asyncio.get_event_loop() tasks = [wget(host) for host in ['www.sina.com.cn', 'www.sohu.com', 'www.163.com']] loop.run_until_complete(asyncio.wait(tasks)) loop.close()
asyncio提供了完善的异步IO支持;
异步操作需要在coroutine中通过yield from完成;
多个coroutine可以封装成一组Task然后并发执行。
async/await
用asyncio提供的@asyncio.coroutine可以把一个generator标记为coroutine类型,然后在coroutine内部用yield from调用另一个coroutine实现异步操作。
为了简化并更好地标识异步IO,从Python 3.5开始引入了新的语法async和await,可以让coroutine的代码更简洁易读。
请注意,async和await是针对coroutine的新语法,要使用新的语法,只需要做两步简单的替换:
- 把
@asyncio.coroutine替换为async; - 把
yield from替换为await。
async def hello(): print("Hello world!") r = await asyncio.sleep(1) print("Hello again!")
aiohttp
asyncio可以实现单线程并发IO操作。如果仅用在客户端,发挥的威力不大。如果把asyncio用在服务器端,例如Web服务器,由于HTTP连接就是IO操作,因此可以用单线程+coroutine实现多用户的高并发支持。
asyncio实现了TCP、UDP、SSL等协议,aiohttp则是基于asyncio实现的HTTP框架。
我们先安装aiohttp:
pip install aiohttp
然后编写一个HTTP服务器,分别处理以下URL:
-
/ -
/about
代码如下:
import asyncio from aiohttp import web routes = web.RouteTableDef() @routes.get('/') async def index(request): await asyncio.sleep(2) return web.json_response({ 'name': 'index' }) @routes.get('/about') async def about(request): await asyncio.sleep(0.5) return web.Response(text="<h1>about us</h1>") def init(): app = web.Application() app.add_routes(routes) web.run_app(app) init()
运行后输入:http://localhost:8080/