参考blog and 视频
高斯混合模型 EM 算法的 Python 实现
如何通俗理解EM算法
机器学习-白板推导系列(十一)-高斯混合模型GMM
EM算法的定义
最大期望算法(Expectation-maximization algorithm,又译为期望最大化算法),是在概率模型中寻找参数最大似然估计或者最大后验估计的算法,其中概率模型依赖于无法观测的隐性变量。
最大期望算法经过两个步骤交替进行计算,
第一步是计算期望(E),利用对隐藏变量的现有估计值,计算其最大似然估计值;
第二步是最大化(M),最大化在E步上求得的最大似然值来计算参数的值。M步上找到的参数估计值被用于下一个E步计算中,这个过程不断交替进行。
一、极大似然
1.1 似然函数
在数理统计学中,似然函数是一种关于统计模型中的参数的函数,表示模型参数中的似然性。“似然性”与“或然性”或“概率”意思相近,都是指某种事件发生的可能性。
而极大似然估计就相当于最大可能的意思
比如我的一位同学和一位猎人一起外出打猎,一只野兔从前方窜过,只听一声枪响,野兔应声倒下,如果要我推测,这一发命中的子弹是谁打的?我就会想,只发一枪便打中,由于猎人命中的概率一般大于我的同学命中的概率,从而推断出这一枪应该是猎人射中的。
这个例子所做出的推断就体现了最大似然法的基本思想。
多数情况下,我们根据已知条件来推算结果,而最大似然估计是已经知道了结果,然后通过这个已经发生的记过来寻求出现这个结果的可能性最大的条件,以此来作为估计值;即通过 现有结果 推出 条件的一个算法。(类似与后验概率)
概率是根据条件推测结果,而似然则是根据结果反推条件;在这种意义上,似然函数可以理解为条件概率的逆反。
假定已知某个参数B时,推测事件A发生的概率写作:
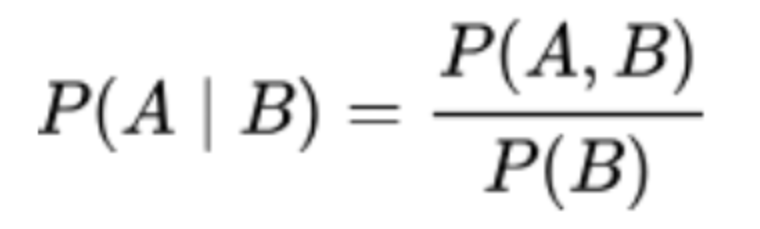
通过贝叶斯公式,可以推导出
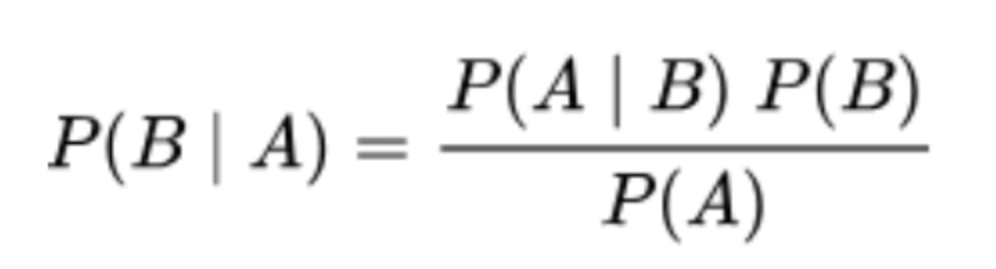
现在,我们反过来:事件A已经发生了,通过似然函数L(B|A),估计参数B的可能性。
1.2 似然函数举例:已知样本X,求参数θ
自从Google的围棋机器人AlphaGo通过4:1战胜人类世界冠军李世石之后,人工智能的大潮便一发不可收拾,在无人驾驶、人脸识别、安防监控、医疗影像等各领域大行其道。而专注AI教育的七月在线也已于2017年年底积累了10万AI学员。
假定我们需要统计7月在线10万学员中男生女生的身高分布,怎么统计呢?考虑到10万的数量巨大,所以不可能一个一个的取统计;所以,通过随机抽样,从10万学院中随机抽取100个男生,100个女生,然后依次统计他们各自的身高。
对于这个问题,我们可以通过数学建模抽象整理:
- 首先我们从10万学院中抽取到100个男生/女生的身高,组成样本集X,X={x1, x2, ..., xN},其中xi表示抽到的第i个人的身高,N=100,表示抽到的样本个数。
- 假设男生的身高服从正态分布N1,女生的身高则服从另一个正态分布:N2.
- 但是这两个分布的均值和方差都不知道,设为未知参数θ=[u, ∂]T
- 现在需要使用极大似然(MLE),通过着100个男生/女生的身高结果,即通过样本集X来估计两个正态分布的位置参数θ;简而言之,通过已知结果来推测θ,即求p(θ|x)中概率最大的θ是啥。
因为这些男生的升高服从同一个高斯分布,那么抽到男生A的概率是p(xA|θ),抽到男生B的概率是p(xB|θ),所以同时抽到男生A和男生B的概率是p(xA|θ)*p(xB|θ)。
同理,从分布是p(x|θ)的总体样本中同时抽到这100个男生样本的概率,也就是样本集X中100个样本的联合概率(即他们各自概率的乘积),可用下面的式进行表示:
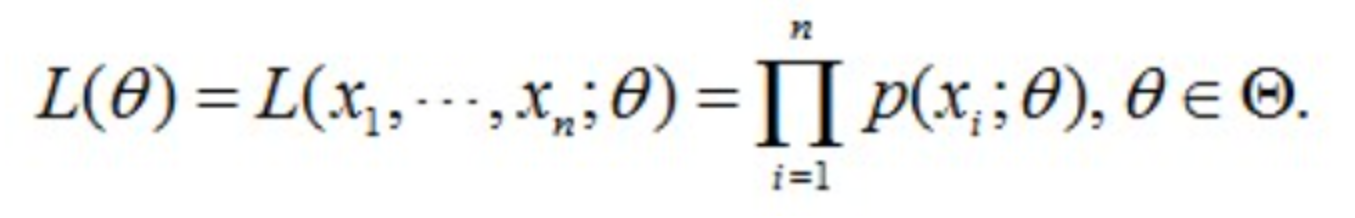
插一句,有的文章会用p(x|θ),有的文章则会用p(x;θ)。不过,不管使用哪种表示方法,本质都是一样的。如果涉及到Bayes公式的话,用前者表示p(x|θ)会好一些。
在七月在线的那么多男学员中,我一抽就抽到了着100个男生,而不是其他人,那么说明在整个学校中这100个人的身高出现的概率是最大的,这个概率就是上面这个似然函数L(θ)。那么现在我想要确定的θ,就是让L(θ)这个函数值最大的时候θ的取值。
1.3 极大似然即最大可能
假定我们找到一个参数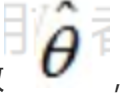
,能够让似然函数L(θ)最大(也就是说确定一个θ使得抽到这100个男生的身高概率最大),则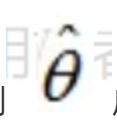
应该是"最可能"的参数值,相当于θ的极大似然估计量,记作:
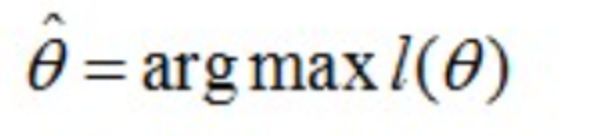
这里的L(θ)是连乘的,为了便于分析,我们可以定义对数似然函数,将其变成连加的:
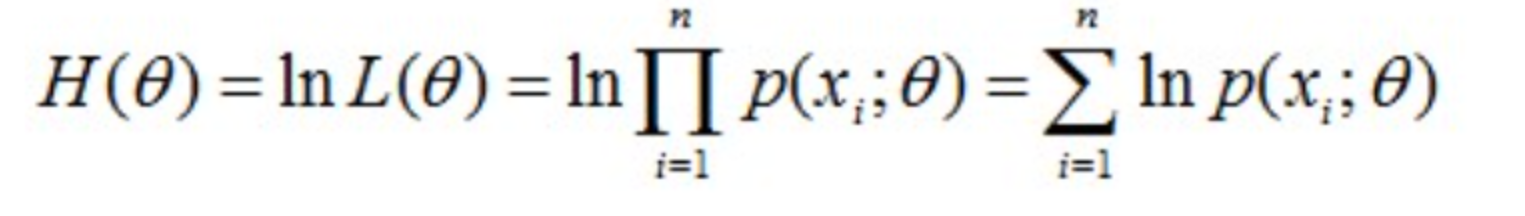
现在需要使似然函数L(θ)极大化,相当于极大化H(θ),最后极大值对应的θ就是我们估计的参数。
对于求一个函数的极值,通过我们在本科所学习的微积分知识,最直接的设想就是求导,然后让导数为0,最后求解出这个方程的0。但,如果0是包含多个参数的向量应该怎么处理呢?当然是求L(0)对所有参数的偏导数,也就是梯度了,从而n个未知的参数,就有n个方程,方程组的解就是似然函数的极值点了,最终得到这个n个参数的值。
求极大似然函数估计值的一般步骤
- 写出似然函数
- 似然函数取对数,并整理
- 求导数,令导数为0,得到似然函数
- 解似然方程,得到的参数即为所求
二、EM算法的理解
2.1 极大似然估计的复杂情况
我们已经知道,极大似然估计用一句话来概括就是:知道结果,反推条件0。
例如,在上文中,为了统计七月在线的10万学院中男生女生的身高分布
- 首先我们从10万学院中抽取到100个男生/女生的身高,组成样本集X,X={x1,x2,...,xN},其中xi表示抽到的第i个人的身高,N=100,表示抽到的样本个数。
- 假定男生的身高服从正态分布N1,女生的身高服从正态分布N2;但是这两个分布的均值和方差都不知道,设为未知参数θ=[u, ∂]T
- 现在需要使用极大似然估计法(MLE),通过这100个男生/女生的身高结果来估计这两个正态分布的位置参数θ,问题定义为已知X,求θ;换而言之就是求p(θ|x)最大的θ的数值。
极大似然估计的目标是求解实现结果的最佳θ,但极大似然估计需要面临的概率分布只有一个或者知道结果是通过哪个概率分布实现的,只不过我们不知道这个概率分布的参数。
但现在我们让情况复杂一些,比如这100个男生和100个女生混在一起了。我们拥有着200个人的身高数据,却不知道着200个人每一个是男生还是女生,此时的男女性别就像一个隐变量。
这时候情况就有点儿尴尬,因为通常来说,我们只有知道了精确的男女身高的正态分布参数,我们才能知道每一个人更有可能是男生还是女生。反过来,我们只有知道了每个人是男生还是女生才能尽可能准确的估计男女各自身高的正态分布的参数。
而EM算法就是为了解决"极大似然估计"这种更复杂而存在的。
2.2 EM算法中的隐变量
理解EM算法中的隐变量很关键,就如理解KMP算法中的理解Next数组的意义一样。
一般用Y表示观测的随机变量的数据,Z表示隐随机变量的数据(因为我们观测不到结果是从哪个概率分布中得出的,所以将这个叫做隐变量)。于是Y和Z连在一起被称为完全数据,仅Y一个称为不完全数据。
这时有没有发现EM算法面临的问题主要就是:有一个隐变量的数据Z;而如果Z已知的话,那问题就可用极大似然估计求解了。于是乎,怎么把Z变成已知的呢?
2.3 EM算法的例子:抛硬币
Nature Biotech在他的一篇EM tutorial文章《Do, C. B., & Batzoglou, S. (2008). What is the expectation maximization algorithm?. Nature biotechnology, 26(8), 897.》中,用了一个投硬币的例子来讲EM算法的思想。
比如抛两枚硬币A和B,如果知道每次抛的是A还是B,那可以直接估计。(如图a)
如果不知道抛的是A还是(这就是我们不知道的隐变量,label:A,B),只观测5轮循环,每轮循环10此,一共50次抛硬币的结果,这时候就没有办法直接估计A和B正面的概率;此时,就轮到EM算法出场了(如图b)
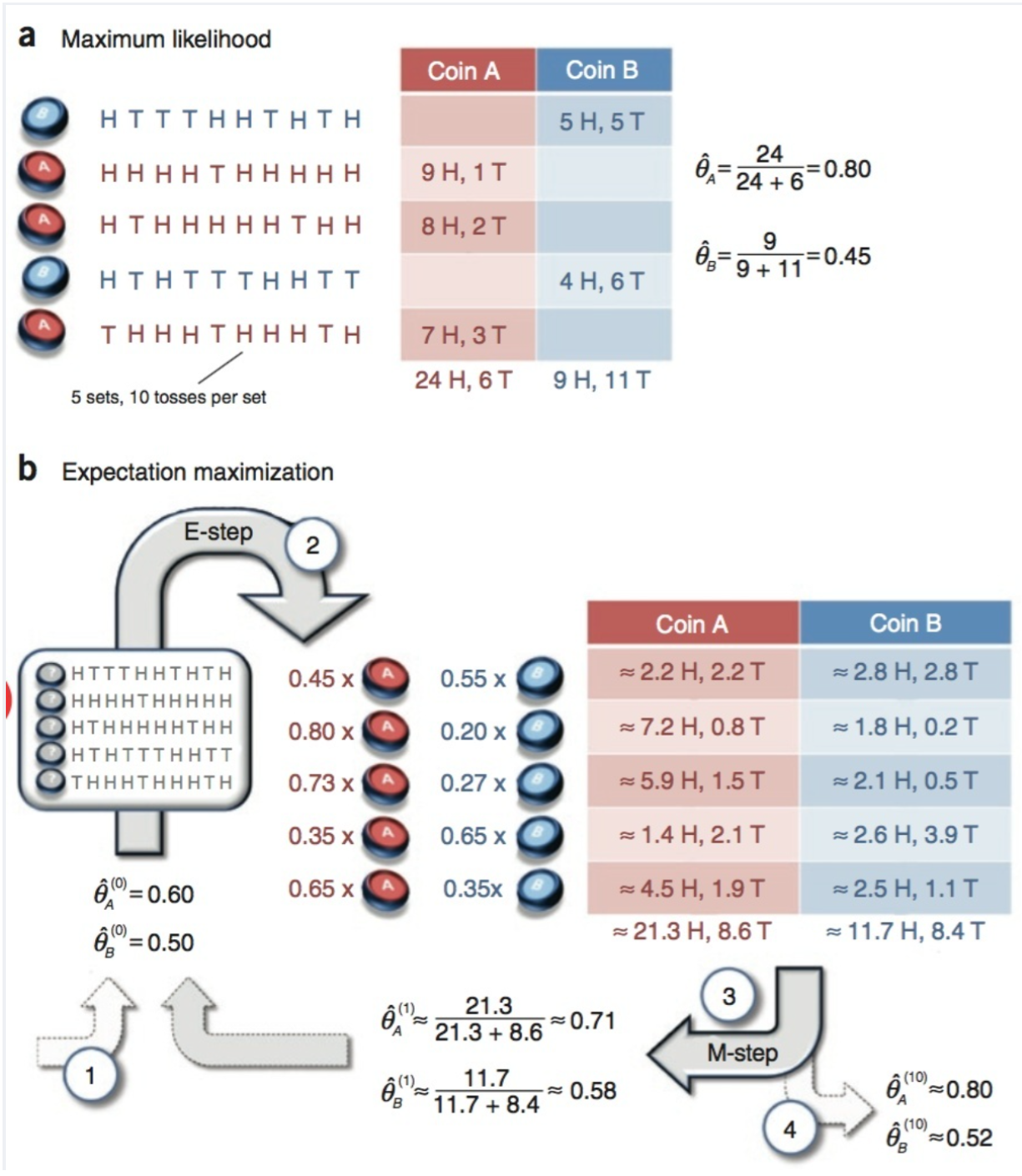

可能咋一看,没看懂;没关系,我们来通俗化这个例子。
还是两枚硬币A和B,假定随机抛掷后正面朝上分别为PA,PA.为了估计这2个硬币朝上的概率,咱们轮流抛硬币A和B,每一轮都连续抛5次,总共5轮:
| 硬币 | 结果 | 统计 |
|---|---|---|
| A | 正正反正反 | 3正-2反 |
| B | 反反正正反 | 2正-3反 |
| A | 正反反反反 | 1正-4反 |
| B | 正反反正正 | 3正-2反 |
| A | 反正正反反 | 2正-3反 |
| 硬币A被抛了15次,在第一轮、第三轮和第五轮分别出现了3次正、1次正、2次正,所以很容易估计出PA,类似的PB也很容易计算出来,如下: | ||
| PA = (3 + 1 + 2) / 15 = 0.4 | ||
| PB = (2 + 3) / 10 - 0.5 | ||
| 问题来了,如果我们不知道抛的硬币是A还是B(即硬币种类是隐变量),然后再轮流五轮,得到如下结果 | ||
| 硬币 | 结果 | 统计 |
| ---- | ---- | ---- |
| Unknown | 正正反正反 | 3正-2反 |
| Unknown | 反反正正反 | 2正-3反 |
| Unknown | 正反反反反 | 1正-4反 |
| Unknown | 正反反正正 | 3正-2反 |
| Unknown | 反正正反反 | 2正-3反 |
| OK,问题现在变得更加有意思了;现在我们的目标没有变化,依然是取估计PA和PB,需要如何取做呢? |
显然,此时我们多了一个硬币种类的隐变量,设为z,可以把它认为是一个5维的向量
(z1, z2, z3, z4, z5),代表,每次投掷时所使用的硬币,比如z1,就代表第一轮投掷时使用的硬币是A还是B。
- 但是这个变量z不知道,就无法取估计PA和PB,所以我们必须先去估计出z,然后才能够取进一步估计PA和PB。
- 可要估计z,我们又得知道PA和PB,这样我们才能够用极大似然法取估计z,这是一个鸡生蛋和蛋生鸡的问题,如何破?
答案:我们先随机初始化一个PA和PB,用它来估计z,然后基于z,还是按照最大似然概率法则取估计新的PA和PB,如果新的PA和PB和我们初始化的PA和PB一样,请问这说明了什么?
这说明了我们初始化的PA和PB是一个相当靠谱的估计!
就是说,我们初始化的PA和PB,按照最大似然概率就可以估计出z,然后基于z,按照最大似然估计反过来估计P1和P2,当与我们初始化的PA和PB一样时,就说明P1和P2很可能就是真实的值;这里面包含了两个交叉的最大似然估计。
如果新估计的PA和PB和我们初始化的数值差别很大,怎么办呢?就继续用新的P1和P2迭代,直至收敛。
我们不妨这样,先随便给PA和PB赋初值,比如:
硬币A正面朝上的概率PA = 0.2
硬币B正面朝上的概率PB = 0.7
然后,我们看看第一轮抛掷最可能是哪个硬币。
如果是硬币A,得出3正2反的概率为 0.20.20.20.80.8 = 0.00512
如果是硬币B,得出三正2反的概率为 0.70.70.70.30.3 = 0.03087
然后一次求出其他四轮中的相应概率。做成表格如下(标粗表示其概率更大):
| 轮数 | 若是硬币A | 若是硬币B |
|---|---|---|
| 1 | 0.00512 | 0.03087 |
| 2 | 0.02048 | 0.01323 |
| 3 | 0.08192 | 0.00567 |
| 4 | 0.00512 | 0.03087 |
| 5 | 0.02048 | 0.01323 |
| 按照最大似然法则: | ||
| 第1轮中最有可能的是硬币B | ||
| 第2轮中最有可能的是硬币A | ||
| 第3轮中最有可能的是硬币A | ||
| 第4轮中最有可能的是硬币B | ||
| 第5轮中最有可能的是硬币A | ||
| 我们就把概率更大,即更可能是A的,就第2,3,5轮出现正的次数2,1,2相加除以A被抛的总次数15次(A抛了三轮,每轮5次),B同理 。 | ||
| PA = (2 + 1 + 2) / 15 = 0.33 | ||
| PB = (3 + 3) / 10 = 0.6 |
不妨设真实的PA和PB分别是0.4和0.5。那么对比下面我们初始化的PA和PB以及新估计出来的PA和PB。
| 初始化的PA | 估计的PA | 真实的PA | 初始化的PB | 估计的PB | 真实的PB |
|---|---|---|---|---|---|
| 0.2 | 0.33 | 0.4 | 0.7 | 0.6 | 0.5 |
我们估计的PA和PB相比于它们的初是值,更接近它们的真实值了!就这样,不断迭代 不断接近真实值,这就是EM算法的奇妙支出。
可以期待,我们继续按照上面的思路,用估计出的PA和PB再来估计z,再用z来估计新的PA和PB,反复迭代下去,就可以最终得到PA = 0.4, PB = 0.5, 此时无论怎样迭代,PA和PB的数值都会保持0.4和0.5不变,于是乎,我们就找到了PA和PB的最大似然估计。
三、EM算法的公式推导
3.1 EM算法的目标函数
还记得1.2节开头说的把?
从分布是p(x|θ)的总体样本中抽取到着100个样本的概率,也就是样本集X中各个样本的联合概率,用下式表示:
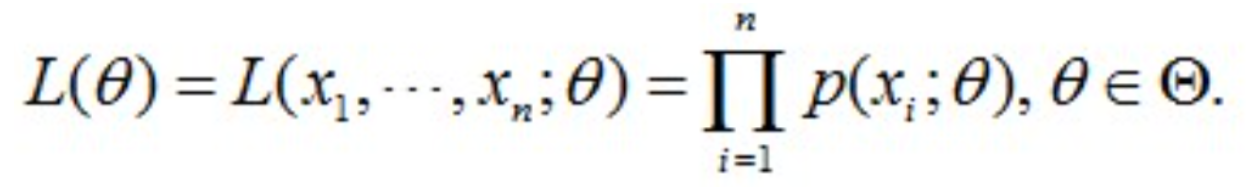
假设我们有一个样本集{x(1),...,x(m)},包含m个独立的样本,现在我们想找到每个样本隐含的类别z,能使得p(x,z)最大。p(x,z)的极大似然估计如下:

第一步是对极大似然取对数,第二步是对每个样例的每个可能类别z求联合分布概率和。但是直接求一般比较困难,因为有隐变量z存在,但是一般确定了z后,求解就容易了。
对于参数估计,我们本质上还是想获得一个使似然函数最大化的那个参数θ,现在与极大似然不同的知识似然函数式中多了一个位置的变量z,见下式(1)。也就是说我们的目标是寻找到合适的θ和z,从而容L(θ)最大。那我们也许会想,你就是多了一个未知变量而已,我们也可以分别对位置的θ和z分别求偏导,再令其等于0,求解出来不也是一样的吗?

本质上我们需要最大化(1)式,也就是似然函数,但是可以看到里面有"和的对数",求导后形式会非常复杂(可以想象一下log(f1(x)+f2(x)+...)复合函数的求导),所以很难求解得到未知参数z和θ。
我们把分子和分母同时乘上一个相等的函数(即隐变量Z的概率分布Qi(Z(i))),其概率之和等于1,即
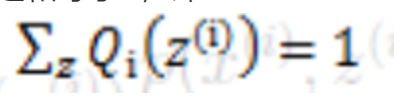
,即得到上图中的(2)式,但(2)式还是有"和的对数",还是求解不了,咋办呢?接下来,就是见证奇迹的时刻了,我们通过Jensen不等式可得到(3)式,此时(3)式变成了"对数的和",如此一来求导就容易了。
从(2)式到(3)式,神奇的地方有两点:
- 当我们在求(2)式的极大值时,(2)式不太好计算,我们便想(2)式大于某个方便计算的下界(3)式,而我们尽可能让下界(3)式最大化,直到(3)式的计算结果等于(2)式,便也就间接求得了(2)式的极大值;
- Jensen不等式,促进神奇发生的Jensen不等式到底是什么来历呢?
3.2 Jensen不等式
f是定义域为实数的函数
- 如果对于所有的实数x,f(x)的二次导数f''(x)>=0,那么f是凸函数
- 当x是向量时,如果其hessian矩阵H是半定的(H>=0),那么f是凸函数
- 如果f''(x)>0或者H>0,那么f是严格凸函数。
Jensen不等式表述如下:
如果f是凸函数,X是随机变量,那么:E[f(X)]>=f(E[X]),通俗的说法是函数的期望大于期望的函数。
特别地,如果f是严格凸函数,当且仅当P(X=EX)=1,即X是常量时,上式取等号,即E(f(X))=f(EX)。
如下图所示:
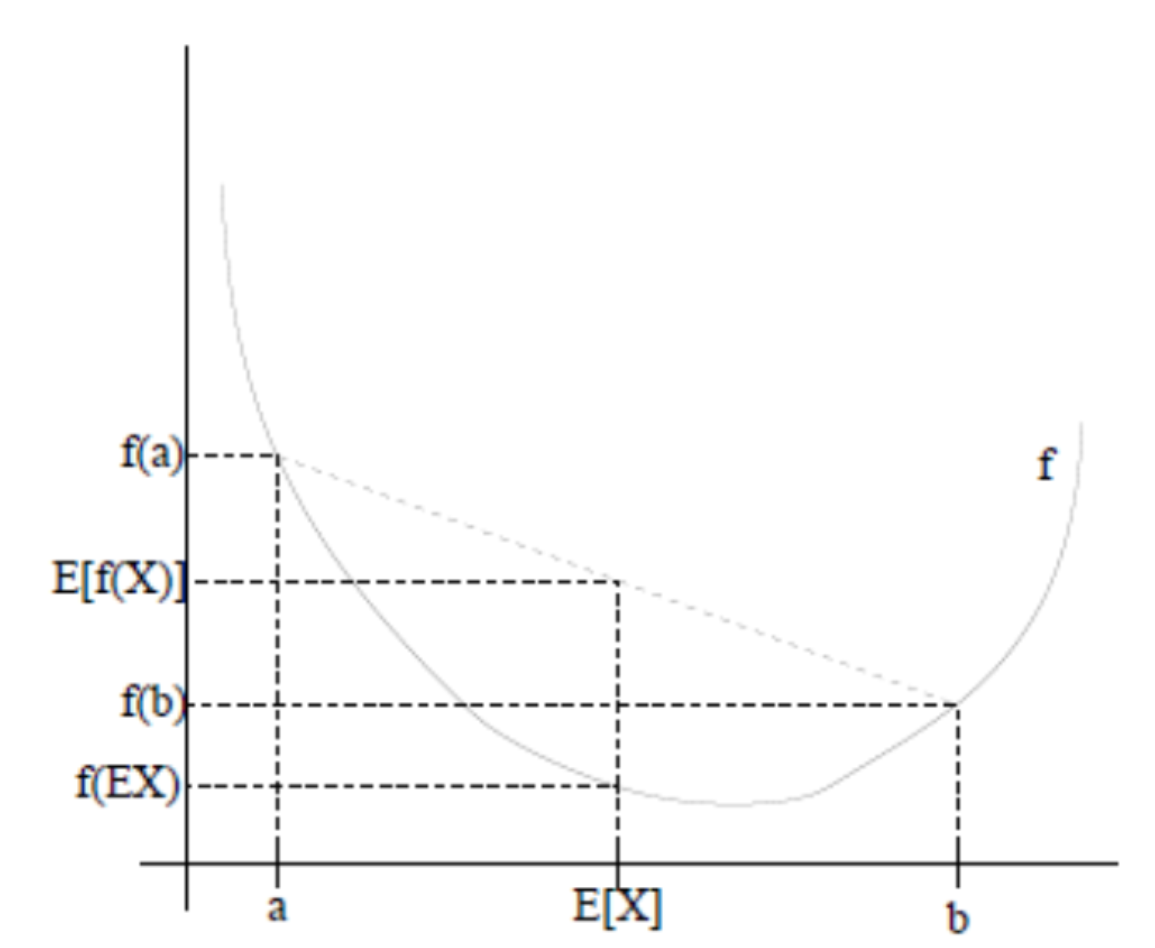
图中,实线f是凸函数(因为函数上方的区域是一个凸集),X是随机变量,有0.5的概率是a,有0.5的概率是b(就像抛硬币一样)。X的期望值就是a和b的中值,可以明显的看出,E[f(X)] >= f(E[X])。
当然,当f是(严格)凹函数时,不等式方向,也就是E[f(X)]<=f(E(X))
回到公式(2),因为f(x)=log(x)为凹函数(其二次导数为1/x2<0)
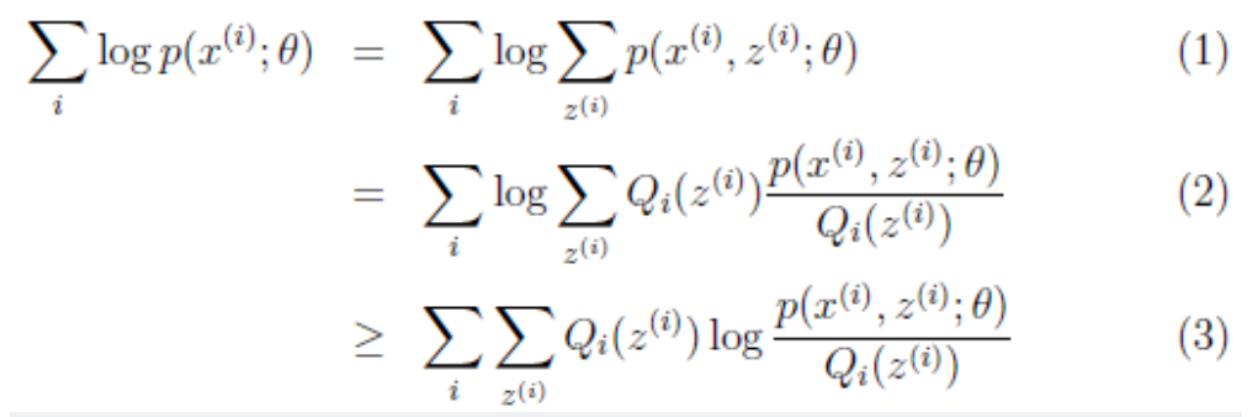
(2)式中的
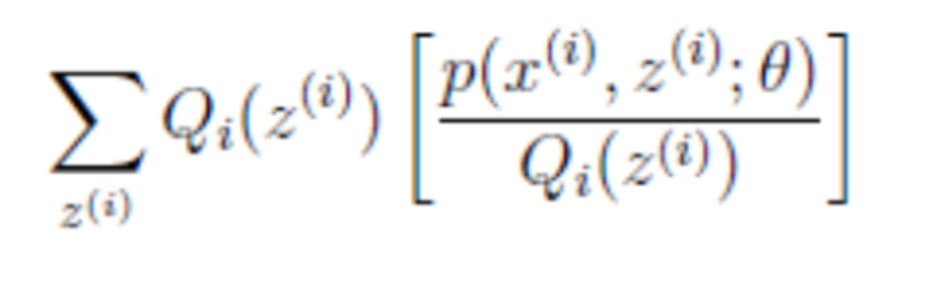
就是
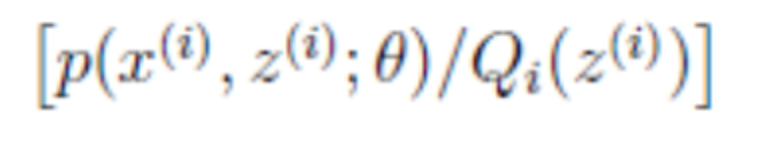
的期望,为什么,可以回想期望公式中的Lazy Statistician规则,如下:
设Y是随机变量X的函数,Y=g(X)(g是连续函数),那么
- X是离散型随机变量,它的分布律为P(X=xk)=pk,k=1,2,...。若
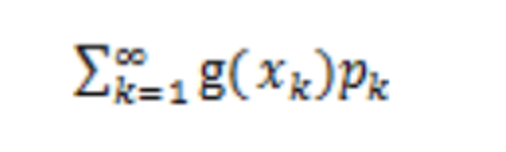
则有:
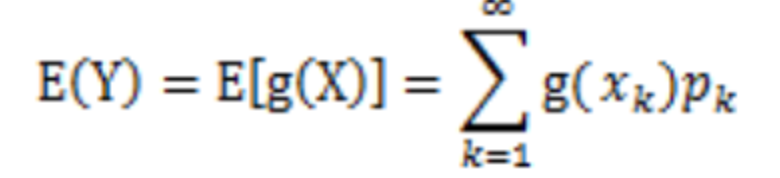
- X是连续型随机变量,它的概率密度为f(x),若
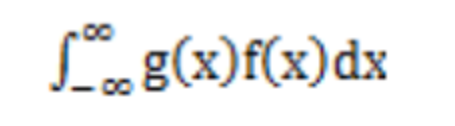
绝对收敛,则有:
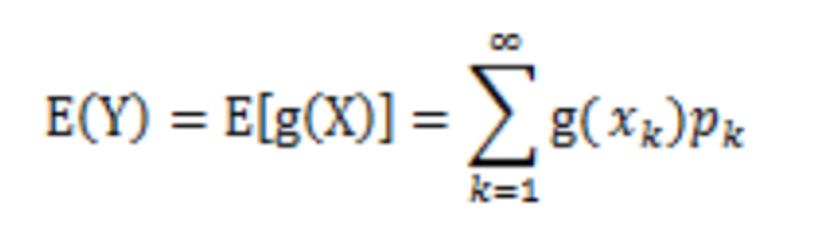
考虑到E(X)=∑xp(x),F(x)是X的函数,则E[f(X)] = ∑xp(x),又
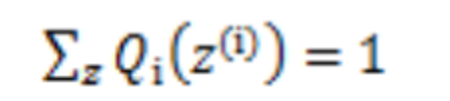
所以就可以得到公式(3)的不等式了:
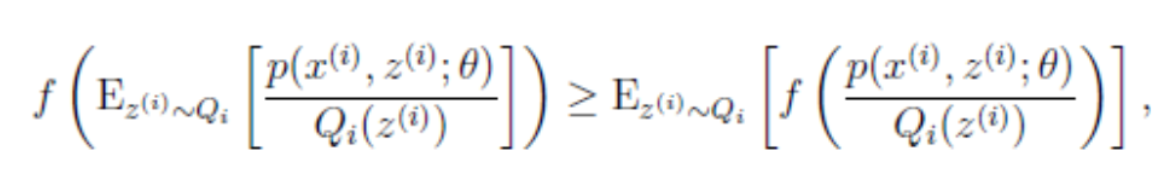
到这里,现在式(3)就比较容易求导了,但是式(2)和式(3)是不等号,而不是等号,导致式(2)的最大值不是式(3)的最大值,而我们想得到式(2)的最大值,应该怎么办呢?
上面的式(2)和式(3)不等式可以写成:似然函数L(θ)>=J(z,Q),如3.1节最后所说,我们可以通过不断地最大化这个下届J,来使地L(θ)不断提高,最后达到L(θ)的最大值。
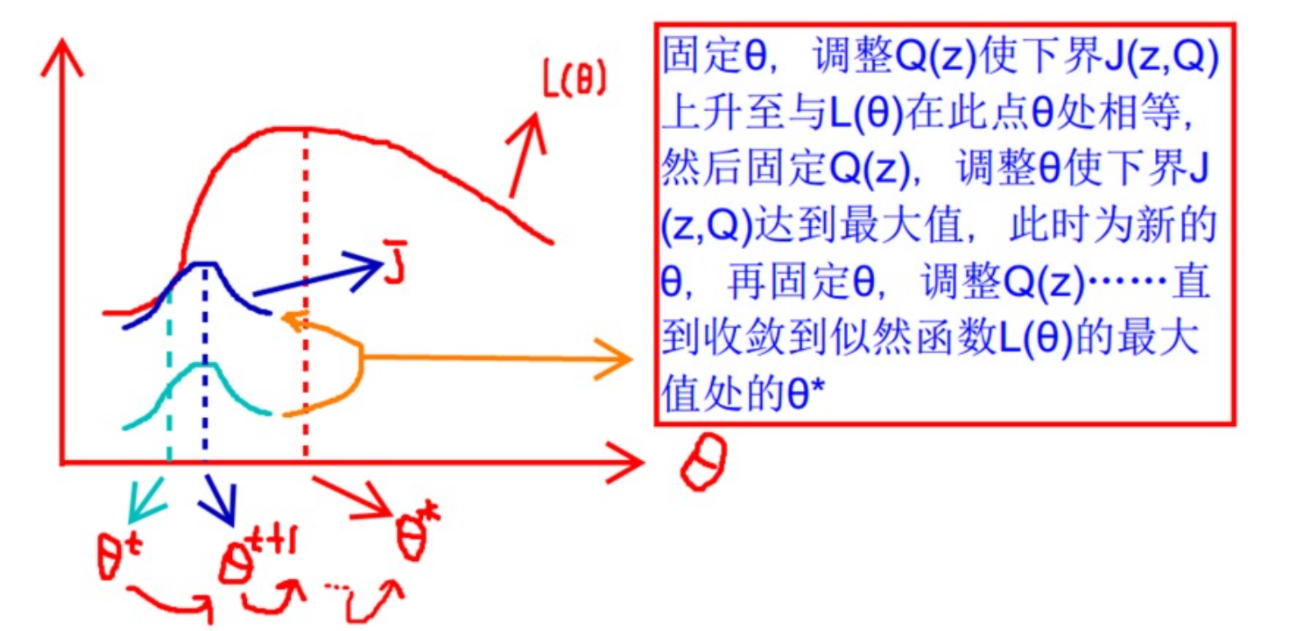
见上图,我们固定θ,调整Q(z)使下届J(z,Q)达到最大值(θt到θt+1),然后再固定θ,调整Q(z).....直到收敛到似然函数L(θ)的最大值处的θ*。
这里又两个问题:
- 什么时候下届J(z,Q)与L(θ)在此点θ处相等?
- 为什么一定会收敛?
首先第一个问题,在Jensen不等式中说到,当自变量X是常数的时候,等式成立。换言之,为了让(3)式取等号,我们需要:
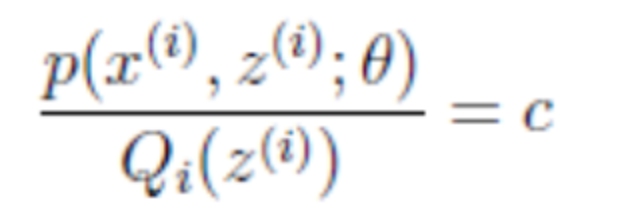
其中c为常熟,不依赖与z(i)。对该式做个变换,并对所有的z求和,得到
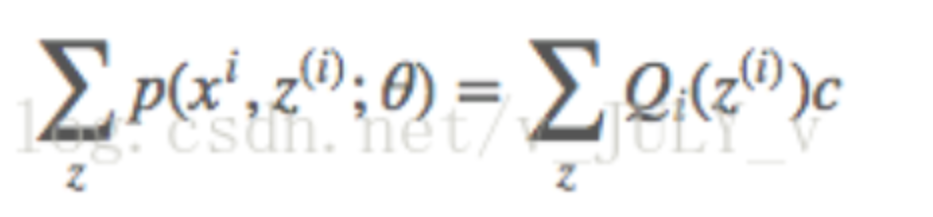
因为前面提到的,隐变量Z的概率分布,其概率之和等于1,所以可以推导出:
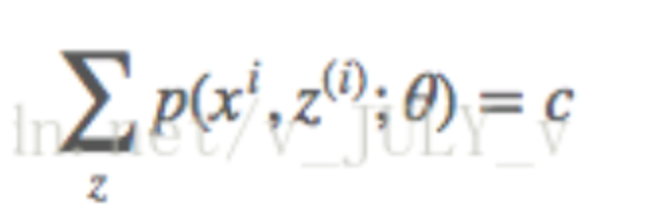
通过
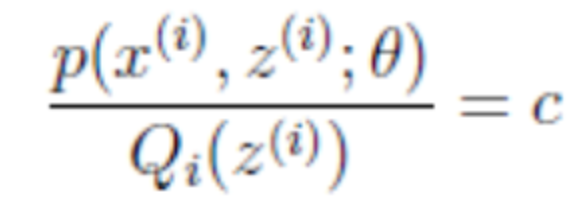
可以求出来Q(zi)的值,即:

又因为:
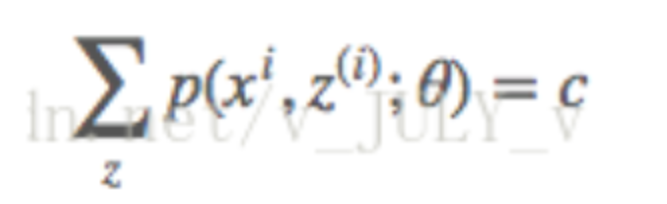
所以Q(Zi)为:

瞬间豁然开朗!至此,我们推出了在固定参数θ后,使用下界拉升的Q(z)的计算公式就是条件概率,解决了Q(z)如何选择的问题。这一步就是E步,建立L(θ)的下界。
接下来的M步,就是在给定Q(z)后,调整θ,去极大化L(θ)的下界J(z,Q),毕竟在固定Q(z)后,下届还可以调整的更大。
这就是EM算法的步骤。
3.3 EM算法的流程及证明
我们来总结一下,期望最大化EM算法是一种从不完全数据或又数据丢失的数据集(存在隐含变量)中求解概率模型参数的最大似然估计方法。
换言之,当我们不知道隐变量z的具体取值时(比如是硬币A还是硬币B),也就不好判断硬币A或硬币B正面朝上的概率θ,既然这样,那就:
- 随机初始化分布参数θ
- 然后循环重复直到收敛{
-
(E步,求Q函数)对于每一个i,计算根据上一次迭代的模型参数来计算隐性变量的后验概率(其实就是隐性变量的期望),来作为隐藏变量的现估计值:
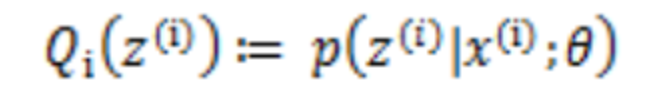
-
(M步,求使用Q函数获得极大时的参数取值)将似然函数最大化以获得新的参数值
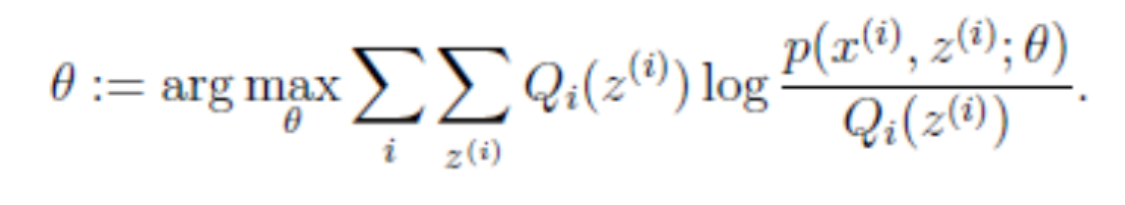
-
}
3.4 整体推导过程

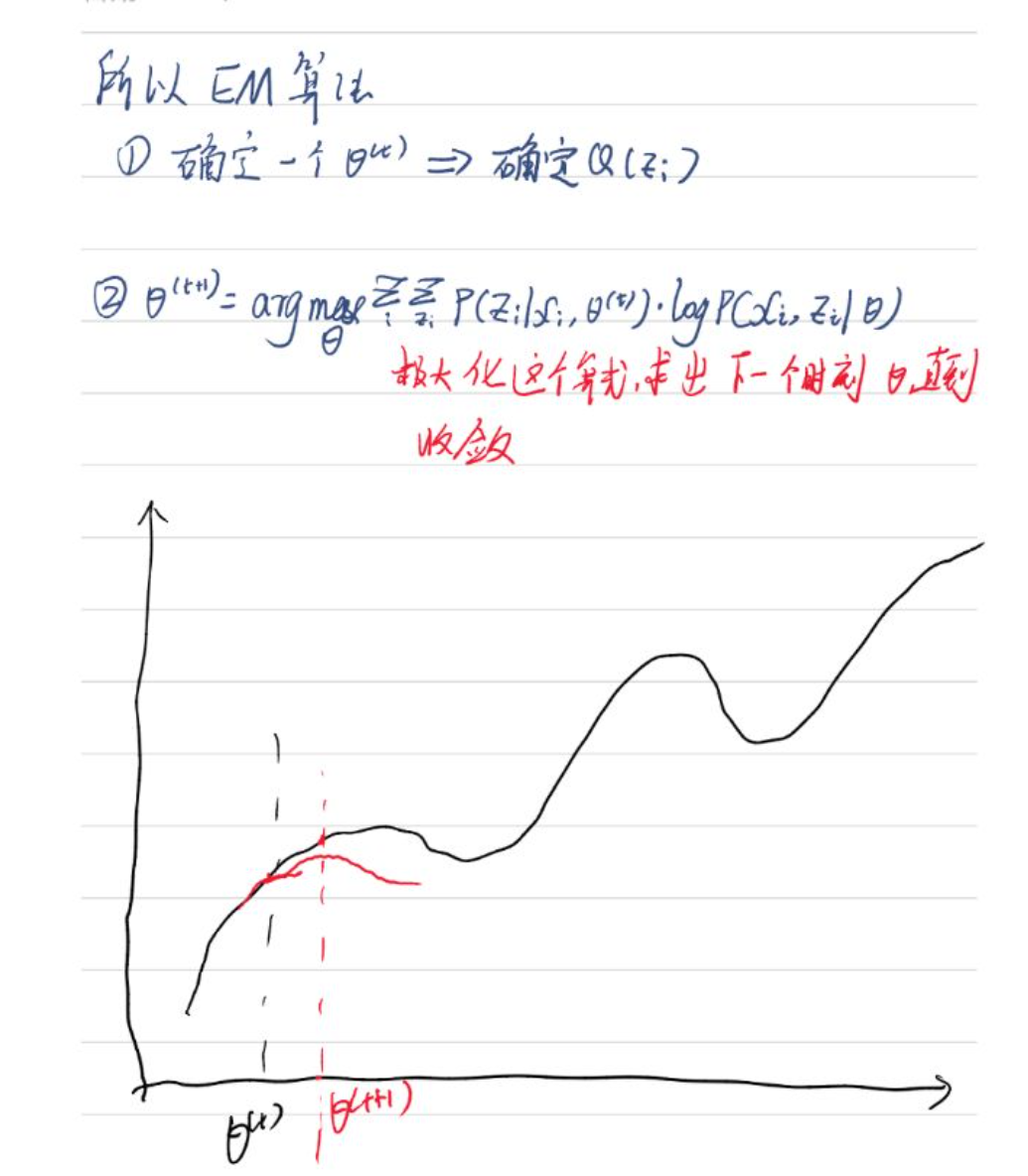
四、EM算法应用到高斯混合模型中
4.1 高斯混合模型简单介绍
首先简单介绍一些,高斯混合模型(GMM, Gaussian Mixture Model)是多个高斯模型的线性叠加,高斯混合模型的概率分布可以表示如下:
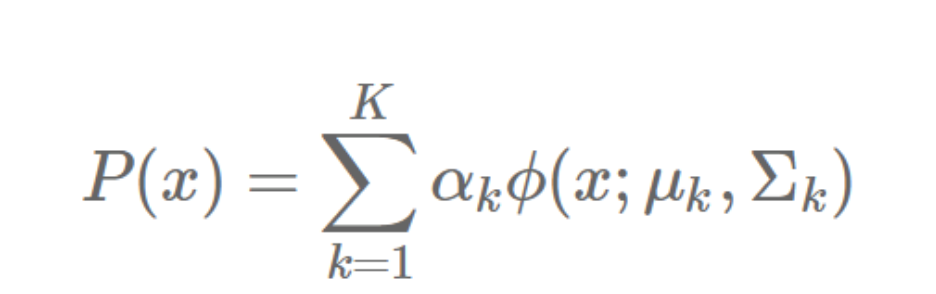
其中,K 表示模型的个数,αk 是第 k 个模型的系数,表示出现该模型的概率,ϕ(x;μk,Σk) 是第 k 个高斯模型的概率分布。
这里讨论的是多个随机变量的情况,即多元高斯分布,因此高斯分布中的参数不再是方差 σk,而是协方差矩阵 Σk 。
我们的目标是给定一堆没有标签的样本和模型个数K,以此求得混合模型的参数,然后就可以用这个模型来对样本进行聚类。
4.2 GMM的EM算法
我们直到,EM算法是通过不断迭代来求得最佳参数的。在执行该算法之前,需要先给出一个初始化的模型参数。
我们让每个模型的 μ 为随机值,Σ 为单位矩阵,α 为 1K,即每个模型初始时都是等概率出现的。
EM算法可以分为E步和M步。
E步
直观理解就是我们已经知道了样本xi,那么它是由哪个模型产生的呢?我们这里求的就是:样本xi来自于第k个模型的概率,我们把这个概率称为模型k对样本xi的"责任",也叫"响应度",记作γik,计算公式如下:

M步
根据样本和当前 γ 矩阵重新估计参数,注意这里 x 为列向量:
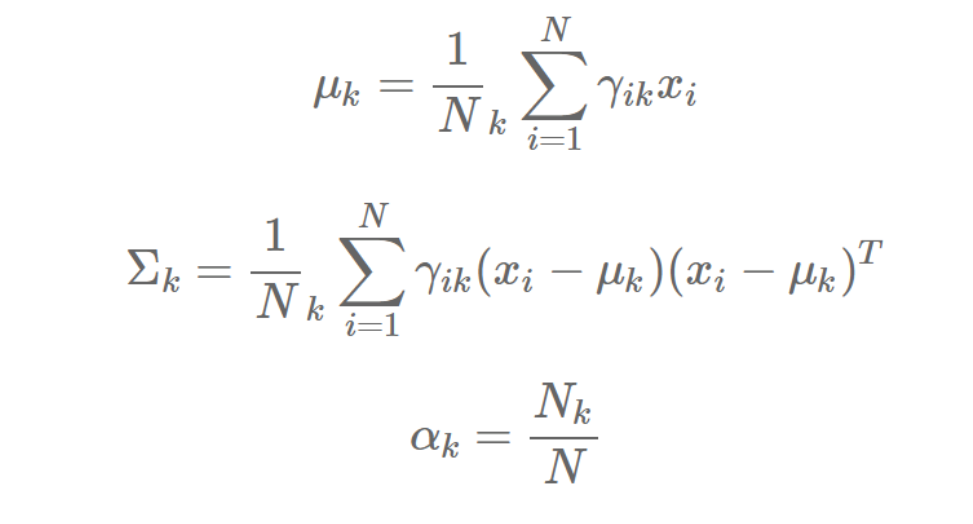
4.3 Python实现
在给出代码前,先作一些说明。
- 在对样本应用高斯混合模型的EM算法前,需要先进行数据预处理,即把所有样值都缩放到0和1之间。
- 初始化模型参数时,要确保任意两个模型之间参数没有完全相同,否则迭代到最后,两个模型的参数也将完全相同,相当于一个模型。
- 模型的个数必须大于1.当K等于1时相当于将样本聚成一类,没有任何意义。
generate_data.py
import numpy as np
import matplotlib.pyplot as plt
cov1 = np.mat("0.3 0;0 0.1")
cov2 = np.mat("0.2 0;0 0.3")
mu1 = np.array([0, 1])
mu2 = np.array([2, 1])
sample = np.zeros((100, 2))
sample[:30, :] = np.random.multivariate_normal(mean=mu1, cov=cov1, size=30)
sample[30:, :] = np.random.multivariate_normal(mean=mu2, cov=cov2, size=70)
np.savetxt("./data/sample.data", sample)
plt.plot(sample[:30, 0], sample[:30, 1], "bo")
plt.plot(sample[30:, 0], sample[30:, 1], "rs")
plt.show()
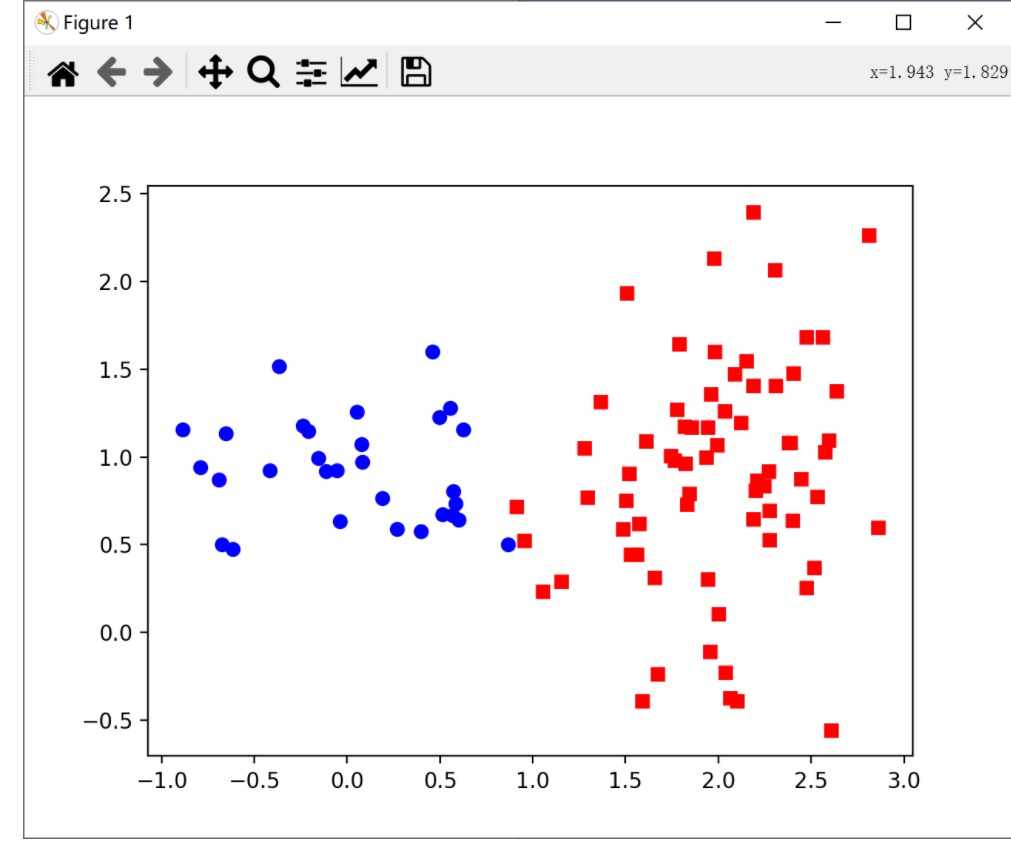
代码解析
-
np.mat():生成矩阵
np.array():创建数组
mat可以从字符串或列表中生成;array只能从列表中生成 -
返回来一个给定形状和类型的用0填充的数组;
-
np.random.multivariate_normal方法用于根据实际情况生成一个多元正态分布矩阵
其中mean和cov为必要的传参而size,check_valid以及tol为可选参数。
mean:mean是多维分布的均值维度为1;
cov:协方差矩阵(协方差基本概念戳这里),注意:协方差矩阵必须是对称的且需为半正定矩阵;
size:指定生成的正态分布矩阵的维度(例:若size=(1, 1, 2),则输出的矩阵的shape即形状为 1X1X2XN(N为mean的长度))。
check_valid:这个参数用于决定当cov即协方差矩阵不是半正定矩阵时程序的处理方式,它一共有三个值:warn,raise以及ignore。当使用warn作为传入的参数时,如果cov不是半正定的程序会输出警告但仍旧会得到结果;当使用raise作为传入的参数时,如果cov不是半正定的程序会报错且不会计算出结果;当使用ignore时忽略这个问题即无论cov是否为半正定的都会计算出结果。3种情况的console打印结果如下: -
generate_data.py:制定了2个维度为2的正态分布;前面30条数据是N1,后边70条数据是N2。
gmm.py
# -*- coding: utf-8 -*-
# ----------------------------------------------------
# Copyright (c) 2017, Wray Zheng. All Rights Reserved.
# Distributed under the BSD License.
# ----------------------------------------------------
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal
DEBUG = True
######################################################
# 调试输出函数
# 由全局变量 DEBUG 控制输出
######################################################
def debug(*args, **kwargs):
global DEBUG
if DEBUG:
print(*args, **kwargs)
'''
# 第 k 个模型的高斯分布密度函数
# 每 i 行表示第 i 个样本在各模型中的出现概率
# 返回一维列表;代表着当前这个高斯分布下,所有样本的概率是多少
'''
def phi(Y, mu_k, cov_k):
norm = multivariate_normal(mean=mu_k, cov=cov_k)
return norm.pdf(Y)
'''
# E 步:计算每个模型对样本的响应度
# Y 为样本矩阵,每个样本一行,只有一个特征时为列向量(100,2)
# mu 为均值多维数组,每行表示一个样本各个特征的均值;2个期望矩阵,维度为(2, 2)
# cov 为协方差矩阵的数组,alpha 为模型响应度数组;含有K个数值的数组,表示每个模型的概率,初始化为1/K (1, K)
'''
def getExpectation(Y, mu, cov, alpha):
# 样本数
N = Y.shape[0]
# 模型数
K = alpha.shape[0]
# 为避免使用单个高斯模型或样本,导致返回结果的类型不一致
# 因此要求样本数和模型个数必须大于1
assert N > 1, "There must be more than one sample!"
assert K > 1, "There must be more than one gaussian model!"
# 响应度矩阵,行对应样本,列对应响应度
gamma = np.mat(np.zeros((N, K)))
# 计算各模型中所有样本出现的概率,行对应样本,列对应模型
prob = np.zeros((N, K))
for k in range(K): #对同一列,的每一行进行操作;给同一个K的不同样本进行赋值,表示再当前这个高斯分布下,这些样本的概率值
prob[:, k] = phi(Y, mu[k], cov[k])
prob = np.mat(prob) #(100, 2)
# 计算每个模型对每个样本的响应度
for k in range(K):
gamma[:, k] = alpha[k] * prob[:, k] # 对于每个样本而言,每个模型出现的概率是alpha(k)
for i in range(N):
gamma[i, :] /= np.sum(gamma[i, :]) #归一化
return gamma
'''
# M 步:迭代模型参数
# Y 为样本矩阵(样本数,特征数)(100,2)
# gamma 为响应度矩阵(样本数,模型数)(100,2)
'''
def maximize(Y, gamma):
# 样本数和特征数
N, D = Y.shape
# 模型数
K = gamma.shape[1]
#初始化参数值
mu = np.zeros((K, D))
cov = []
alpha = np.zeros(K)
# 更新每个模型的参数
for k in range(K):
# 第 k 个模型对所有样本的响应度之和
Nk = np.sum(gamma[:, k])
# 更新 mu
# 对每个特征求均值
for d in range(D):
mu[k, d] = np.sum(np.multiply(gamma[:, k], Y[:, d])) / Nk
# 更新 cov
cov_k = np.mat(np.zeros((D, D)))
for i in range(N):
cov_k += gamma[i, k] * (Y[i] - mu[k]).T * (Y[i] - mu[k]) / Nk
cov.append(cov_k)
# 更新 alpha
alpha[k] = Nk / N
cov = np.array(cov)
return mu, cov, alpha
'''
# 传入一个矩阵
# 数据预处理
# 将所有数据都缩放到 0 和 1 之间
'''
def scale_data(Y):
# 对每一维特征分别进行缩放
for i in range(Y.shape[1]):
max_ = Y[:, i].max()
print(i)
min_ = Y[:, i].min()
Y[:, i] = (Y[:, i] - min_) / (max_ - min_)
debug("Data scaled.")
return Y
'''
# 初始化模型参数
# shape 是表示样本规模的二元组,(样本数, 特征数)
# K 表示模型个数
'''
def init_params(shape, K):
N, D = shape # N:样本数,D:特征数
mu = np.random.rand(K, D) # (模型数,特征数),生成K个期望矩阵,维度为(2, 2)
cov = np.array([np.eye(D)] * K) # 生成K个协方差矩阵,即2个单位矩阵
alpha = np.array([1.0 / K] * K) # 生成含有K个数值的数组,表示每个模型的概率,初始化为1/K
debug("Parameters initialized.")
debug("mu:", mu, "cov:", cov, "alpha:", alpha, sep="
")
return mu, cov, alpha
'''
# 高斯混合模型 EM 算法
# 给定样本矩阵 Y,计算模型参数(100,2)
# K 为模型个数(可能的模型数量,在这里表示高斯模型数量
# times 为迭代次数
'''
def GMM_EM(Y, K, times):
Y = scale_data(Y) # 将Y中的数据缩放到 0-1 之间
mu, cov, alpha = init_params(Y.shape, K) #Y.shape表示数据的维度,K表示模型的数量
for i in range(times):
gamma = getExpectation(Y, mu, cov, alpha) #得到一个(100,2),gamma(i,j):第i个样本是第j个模型的概率
mu, cov, alpha = maximize(Y, gamma)
debug("{sep} Result {sep}".format(sep="-" * 20))
debug("mu:", mu, "cov:", cov, "alpha:", alpha, sep="
")
return mu, cov, alpha
main.py
# -*- coding: utf-8 -*-
# ----------------------------------------------------
# Copyright (c) 2017, Wray Zheng. All Rights Reserved.
# Distributed under the BSD License.
# ----------------------------------------------------
import matplotlib.pyplot as plt
from gmm import *
# 设置调试模式
DEBUG = True
# 载入数据
Y = np.loadtxt("./data/sample.data")
matY = np.matrix(Y, copy=True)
# 模型个数,即聚类的类别个数
K = 2
# 计算 GMM 模型参数
'''
1. 这里传入的三个参数是:matY:所有观测的数据(x1,x2)组成的矩阵,维度为:(100,2)
2. K:聚类的数量,表示这里由两种可能的高斯模型
3. 100表示数据的数量,一共有100条数据
4. GMM_EM:这个函数需要返回三个参数:mu,cov,alpha
1) mu:表示期望
2) cov:表示协方差矩阵
3)alpha:表示每个样本属于哪个高斯分布的概率 alpha = (alpha1, ..., alphak)表示当前样本属于第i个高斯分布的概率值.
'''
mu, cov, alpha = GMM_EM(matY, K, 100)
# 根据 GMM 模型,对样本数据进行聚类,一个模型对应一个类别
N = Y.shape[0]
# 求当前模型参数下,各模型对样本的响应度矩阵
gamma = getExpectation(matY, mu, cov, alpha)
# 对每个样本,求响应度最大的模型下标,作为其类别标识
category = gamma.argmax(axis=1).flatten().tolist()[0]
# 将每个样本放入对应类别的列表中
class1 = np.array([Y[i] for i in range(N) if category[i] == 0])
class2 = np.array([Y[i] for i in range(N) if category[i] == 1])
# 绘制聚类结果
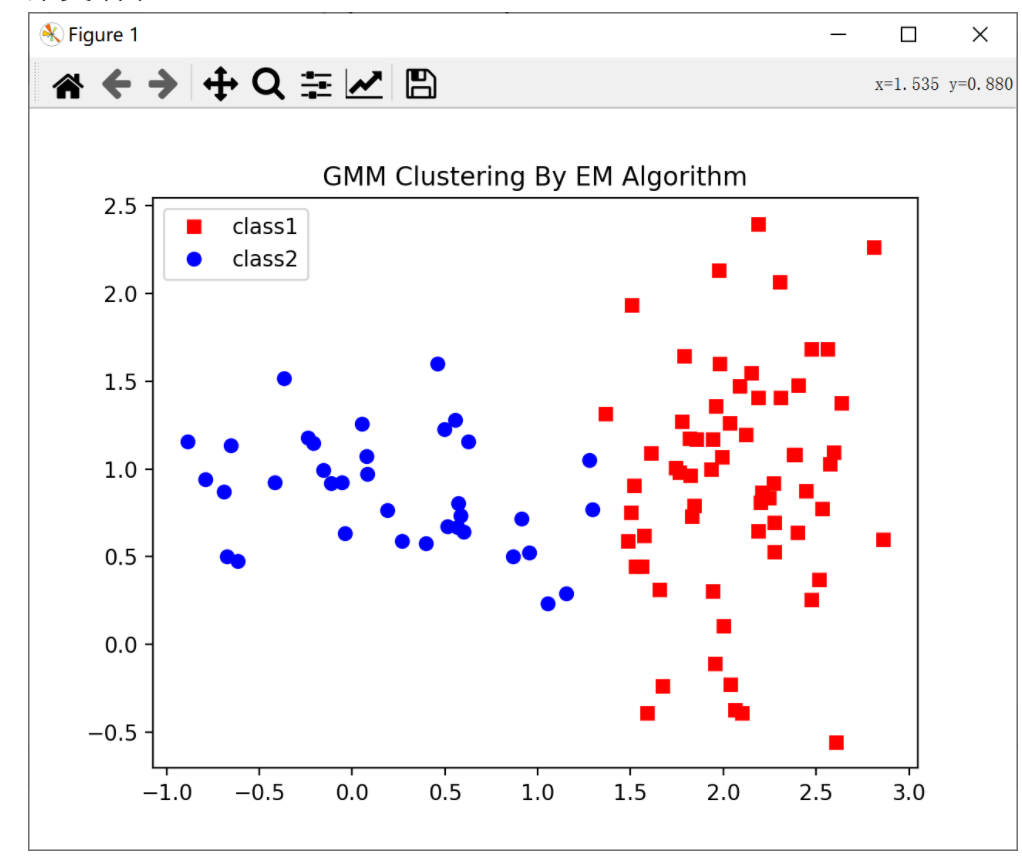
plt.plot(class1[:, 0], class1[:, 1], 'rs', label="class1")
plt.plot(class2[:, 0], class2[:, 1], 'bo', label="class2")
plt.legend(loc="best")
plt.title("GMM Clustering By EM Algorithm")
plt.show()
代码解析
- argmax()函数
import numpy as np
a = np.array([3, 1, 2, 4, 6, 1])
#print(np.argmax(a))
#4
#argmax返回的是最大数的索引.argmax有一个参数axis,默认是0,表示第几维的最大值.
- flatten()函数
#a.flatten():a是个数组,a.flatten()就是把a降到一维,默认是按行的方向降
from numpy import *
a=array([[1,2],[3,4],[5,6]])
print(a)
'''
array([[1, 2],
[3, 4],
[5, 6]])'''
a.flatten() #默认按行的方向降维
#array([1, 2, 3, 4, 5, 6])
a.flatten('F') #按列降维
#array([1, 3, 5, 2, 4, 6])
a.flatten('A') #按行降维
#array([1, 2, 3, 4, 5, 6])
- tolist()函数
#tolist()作用:将矩阵(matrix)和数组(array)转化为列表。
from numpy import *
a1 = [[1,2,3],[4,5,6]] #列表
a2 = array(a1) #数组
print(a2)
# array([[1, 2, 3],
# [4, 5, 6]])
a3 = mat(a1) #矩阵
print(a3)
# matrix([[1, 2, 3],
# [4, 5, 6]])
a4 = a2.tolist()
print(a4)
# [[1, 2, 3], [4, 5, 6]]
a5 = a3.tolist()
print(a5)
# [[1, 2, 3], [4, 5, 6]]
print(a4 == a5)
# True
聚类结果: