最近公司在做一个推荐系统,让我给论坛上的帖子找关键字,当时给我说让我用jieba分词,我周末回去看了看,感觉不错,还学习了一下具体的原理
首先,通过正则表达式,将文章内容切分,形成一个句子数组,这个比较好理解
然后构造出句子的有向无环图(DAG)
def get_DAG(self, sentence): self.check_initialized() DAG = {} N = len(sentence) for k in xrange(N): tmplist = [] i = k frag = sentence[k] while i < N and frag in self.FREQ:#对每一个字从这个字开始搜索成词位置 if self.FREQ[frag]: tmplist.append(i)#如果可以成词就加入到DAG中 i += 1 frag = sentence[k:i + 1] if not tmplist: tmplist.append(k)#如果找不到词语,就将自己加入DAG DAG[k] = tmplist return DAG
- 对句子中的每个字进行分析,从右边一位开始,看sentence[k:i+1]这个词语是否在预设的字典中,这个字典保存了常用的词语(和词语的一部分,但权重为0)和其权重.如果有,并且如果字典中的这个词的权值不等于0,那么就将i放到tmplist里,然后i+=1,继续下一轮循环,如果没有这个词,那就停下来,然后移动k,让k=k+1,找下一个字的成词位置
- 比如有这样一个句子:'我从海淀区搬到了朝阳区',一共11个字
- 通过上面的计算,得到一个字典:<class 'dict'>: {0: [0], 1: [1], 2: [2, 3, 4], 3: [3, 4], 4: [4], 5: [5, 6], 6: [6], 7: [7], 8: [8, 9, 10], 9: [9], 10: [10]},字典键代表每个字在字符串中的位置,比如,0代表'我',1代表'从',而每个键对应一个数组,比如2对应[2,3,4],这个表示:'海'(2)/'海淀'(2-3)/'海淀区'(2-4),这三个字符串可以成为词语
- 这样,我们就得到了所有可以成词的位置了
选出成词概率最大的位置
def calc(self, sentence, DAG, route): N = len(sentence) route[N] = (0, 0) logtotal = log(self.total)#常数值 for idx in xrange(N - 1, -1, -1):#从后往前分析 route[idx] = max((log(self.FREQ.get(sentence[idx:x + 1]) or 1) - logtotal + route[x + 1][0], x) for x in DAG[idx])
- 对于句子中的每一个字,计算候选位置中,哪个成词概率最大
- 比如2:[2,3,4],分别对2/3/4进行计算,计算公式:log(词的概率)-常数+下一个字的成词概率
- 词语的概率还是用之前保存了所有常用词的字典(也可以自己定义字典),下一个字的成词概率是上一个循环计算出来的,我们要从末尾开始计算,得到的结果作为下一个循环的参数,这样我们就找到了最大成词概率的切分位置
- 为什么要加上下一个字的成词概率的呢?因为下一个词的成词概率高的话,我们做出的切分就越正确,越有可能切成两个正确的词语,而不是左边的词语概率高,而右边根本不是一个正确的词语
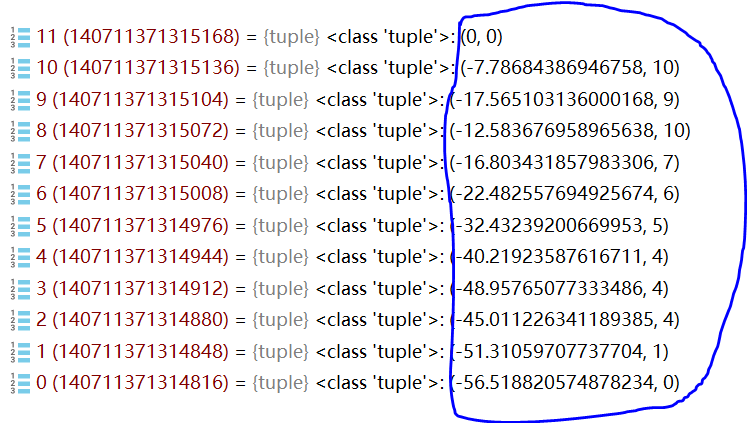
如上图,蓝色圈中的部分,括号右边代表了成词的位置,比如2,括号的右边是4,说明2-4这个词的成词概率高,我们就切成'海淀区'
切分的过程是这样的
- 从头开始,寻找每个位置对应的成词位置,取出来
- 跳到成词位置的下一个位置开始循环
这样,我们就能得到:0/1/2-4/5/6/7/8-10
具体为:我/从/海淀区/搬/到/了/朝阳区
到此为止整个过程就结束了
不过,官方默认算法还有个hmm,这次先不说了,请听下回分解