
2020年天猫双十一成交额突破4982亿,在双十一走过12个年头之际,我们的订单创建峰值达到58.3万笔/秒,再次刷新全球在线交易系统的记录。历年双十一都是对技术人的一次大考,峰值的丝般润滑体验是大家一致的追求,而数据库可谓关键。多年双十一大促“磨练”出阿里巴巴DBA一整套技能来应对大考,比方说全链路压测、容灾预案、实时限流等,同时阿里的数据库产品能力也大幅提升,如智能化的企业级MySQL内核AliSQL,自研PolarDB引擎等,这些硬核能力是阿里巴巴集团数据库团队应对大考的底气。
在数据库引擎技术能力不断攀登高峰的同时,长期以来我们“似乎忽略”一个非常重要的因素,而该因素却是中大型企业上云的必须考量点。如果将时钟指针拨回到半年前,这个重要因素就摆在眼前,是阿里巴巴集团所有的数据库系统全面上云及云原生化过不去的“坎”,它是什么呢?
一、阿里集团数据库全面上云的挑战
当DBA维护的系统上百套甚至上万套以后,系统管理的复杂度就会急剧上升,加上资源利用效率、业务高峰支持(如大促活动评估)、流量管理等上级或业务方“强加给”DBA的工作后,整个系统复杂度就会居高不下,这种复杂度“熵”就会指数级增长,并且无法通过扩充DBA人数来有效解决问题,DBA自身也会陷入到繁杂的日常支持和“灭火”中,自身价值难以体现,这就是深坎。
阿里巴巴集团就是这样一个巨型的、系统复杂度“熵”奇高的大型企业。今年阿里双十一要求所有系统全面上云,相比单纯提升系统吞吐扩展能力的技术要求,这个任务更加难完成。简述下当初面临的严峻挑战:
1.如何保证大量数据库短时间内快速上云?
这不仅仅是数据的搬迁过程,还要在此期间支持业务需求,比方说如何做到对业务“无感知”的迁移数据上云。如何在阿里的巨型体量下,保障所有系统全面上云的丝般顺滑度?
2.如何高效支持DBA满足双十一期间的数据库业务需求?
DBA对业务系统是熟悉,多系统之间有的相互依赖有的相互排斥,如何有效的将它们编排好,从而整体利用好数据库资源,这是非常大的挑战。
3.全面上云以后,要支持DBA依旧对数据库的强管理能力,比方说能够及时登录操作系统排查数据库问题等。
二、全面上云的新打法,以专属集群RDS构建超高效数据库管理体系
在全面上云这个残酷指标下,必须找到全新的方法来解决上述三个重点问题,构建一个高复杂度的但“混乱熵值”很低的超高效的数据库管理体系。这就是全面采用专属集群RDS的根本前提。
那么我们是如何极短时间内全面上云并且能够丝般顺滑,如何充分发挥DBA的业务把控能力从而实现对RDS标准化服务的超高效能的管理,以及如何利用专属集群的源生内核能力构建全球最大的异地多活电商系统呢?
2.1 丝般顺滑上云
要实现丝般顺滑上云,需要充分规划和精细的执行。由于阿里集团是隔离于公有云的网络环境,底层对数据库资源的网络配置上云后都会涉及变化,数据库还要特别注意避免双写,要和业务做联动的流量管理。
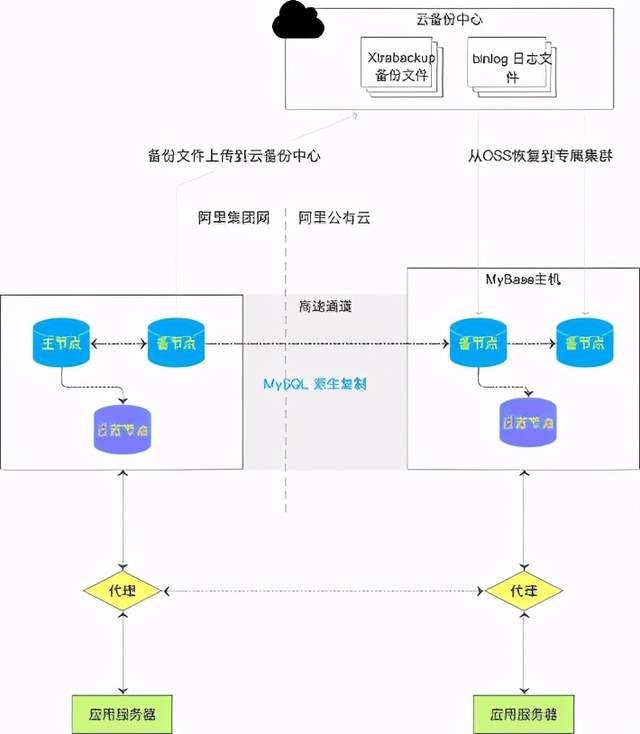
上图是我们实现丝般顺滑上云的基础框架图:
1.将数据传输路径尽量缩短,节省大量时间:由于阿里集团超高业务量,几乎每个数据库系统的数据量都是巨大的,少则TB多则PB为单位,我们采用最原始有效的方法,将备份文件拷贝到云上环境,然后执行快速恢复。
2.有效快速恢复是另一省时环节。阿里集团数据库普遍有两种存储类型,分别是本地SSD盘和ESSD云盘,两者的备份方案是不同的,本地SSD盘类似于Xtrabackup执行物理的备份,ESSD云盘采用存储级快照备份。对应的两者快速恢复的方法也不同,本地SSD盘在备份时采用库表级备份,而恢复的则采用并行表级恢复,大幅度的提升恢复速度,ESSD云盘则通过秒级快照恢复实现。也就是说从阿里集团网的全量备份、到数据两套环境的传输、到云上环境的快速恢复是一个联动的连续过程,从而大大节省恢复时间。
3.利用MySQL源生复制实时追加增量数据,确保业务对数据的搬迁无感知。在复制技术方面,AliSQL 针对高延迟网络做了大量的协议优化尝试和测试,通过合理的Batching和Pipelining,设计并实现了一整套自适应的针对高延迟高吞吐和低延迟高吞吐网络的通信模式,极大的提升了日志传输的性能。另外为了节省带宽,对binlog全面压缩,同时在压缩率和解压速率上采个较好的平衡值。
4.统一的混合网络环境代理实现流量的按需切换,确保业务感觉迁移的过程是顺滑的。联动于业务部署,先切换读流量到云上环境,后切换写流量。由于代理层实现透明切换能力,在分钟级级内会保持原有的数据库连接,保障切写过程中业务是无感知的,在绝大数情况下效果很好。
2.2 灵活可控的标准化服务管理
双十一涉及数据库系统数万套,除交易、商品、用户、评价、优惠、店铺、积分等核心系统外,还有各种“中小型”业务系统,机会每个业务都有一套或多套数据库,每个业务之间有亲和性或排斥性需求,即必须要在专属集群中满足多样性的业务部署要求。
举例而言,我们将购物车数据库和购物车应用自身部署在一起,确保购物车不受别的业务影响,同时购物车内部实现交叉部署,大致部署图如下所示,通过灵活的部署策略,业务方DBA可以制定一套复杂部署策略满足业务需要。
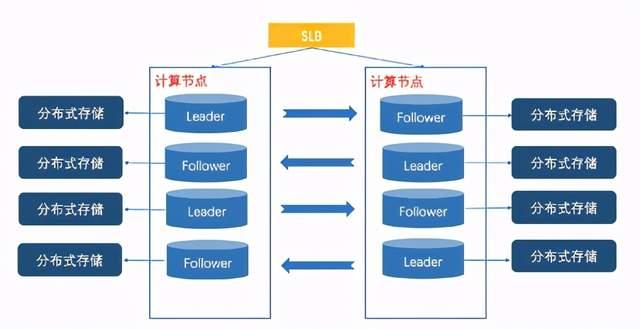
如上所述参与双十一的业务方特别多,而DBA人数有限,DBA对业务的掌控程度也是高低不一的。一般而言,上述的核心业务基本上比较清晰,这主要得益于双十一前的一次次全链路压测,交易核心链路业务模型比较清晰,对数据库容量的预估会很准确。但是这并不是所有情况,比方说创新型业务,对业务流量评估会非常的不准确,可能百倍增长也有可能是百分比增长,此情况下DBA预留数据库资源没有参考依据,如何在有限的资源中支持足够多的创新型业务绝对是一大挑战。再比方说原边缘型业务,会由于其他系统的新依赖、或者业务流量徒增导致流量预期不准,更常见的是被其他系统新依赖,还容易导致故障。
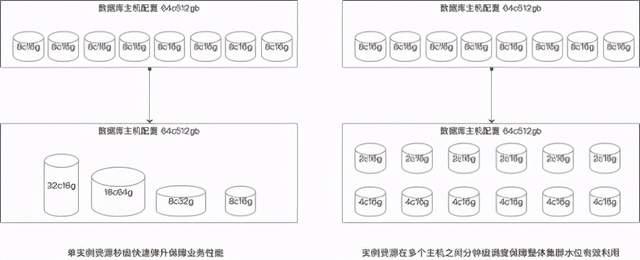
为了解决该不确定性问题,我们在专属集群上特别开发智能化DAS资源调度系统,DBA可以通过简单的设置实例的弹性策略,DAS会根据过去系统的表现情况以及突发状态,基本上以准实时的方式实现秒级资源弹性,分钟级资源调度。秒级资源弹性能力,是在整台主机范围内灵活的对实例资源进行调整,也可以人工干预保护一些实例资源不被争抢。分钟级的资源调度能力,这得益于存储计算分离架构,通过分布式存储的秒级快照能力,以分钟级在不同主机之间重新平衡资源利用调度实例,由于高可用保障系统和代理透明切换能力,这个过程几乎是平滑的。通过专属集群,DBA只需要投入一定量的服务器资源,然后专注监控整体集群的资源水位,就可以保障大量的创新和小型业务的大促性能需要,可谓一夫当关万夫莫开。
2.3 构建源生异地多活
双十一零点高峰流量是巨大的,今年交易笔数达到58.3 万笔/秒,数据库集群的TPS超过千万级每秒,巨大的洪峰流量通过阿里的单元化数据库部署来分流,从而规避单个实例单个机房的流量风险。与往年相比,今年单元化数据库全部采用全球数据库模式支持多地域的读流量,另外在内核中实现源生多写能力,支持实例集群级别的异地多写多活,从而可以在不同地域分担写流量。
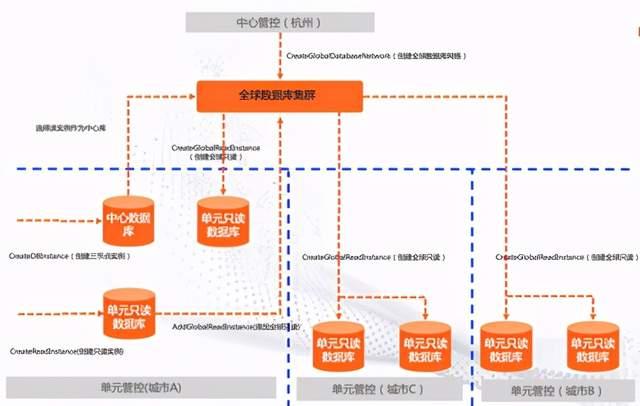
如上图所示本次双十一阿里巴巴启用张北、深圳、南通3个地域,针对每个Region是独立开服的,地域之间是低耦合的,通过一个桥梁把他们连接起来,它就是全球数据库网络,(GDN,Global database network)。部署于不同地域的数据库,采用MySQL的源生复制技术,保证数据的一致性和实时性。
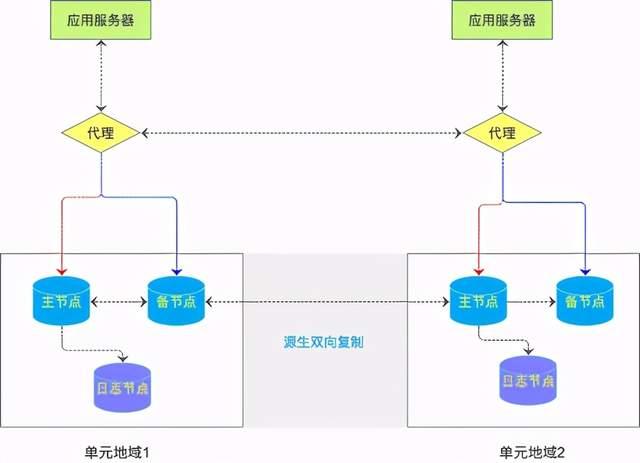
关于异地多活,第一次实现了在内核层的双向同步,在多个地域中都有各自主节点和备节点,在内核中实现双向复制,保障两个地域在数据总量上是一致的,同时写实现分地域分流。这里需要强调的一点,异地多活需要业务的改造,比如这个UID的数据只会在某一个地域写入避免性冲突,此外ID(PK键)也需要使用独立的Sequence,从而实现全局的一致性。业务和数据库在本套架构中实现完美结合,业务只需要关注逻辑的拆分,而数据库自身实现数据的同步组合,底层数据同步复杂性完全由数据库自身实现。
三、展望
总结而言,本次双十一为了保障集团数万数据库的全面上云及云原生化,我们基于专属集群做了很多定向改造和匹配,取得了非常好的效果。核心交易链路总共构建数千台机器集群,总共超过数万的数据库节点,并且所有数据库系统RPO等于0,主备延迟做到毫秒级,并保证整体人力效能数量级提升。灵活调度、源生复制等定制化能力,在专属集群内部实现产品化,经过双十一验证后,逐步开放,将会大幅度提升企业数据库管理生产力,敬请期待。
作者:阿里云高级技术专家 改天、阿里云高级产品专家 胜通
本文为阿里云原创内容,未经允许不得转载。
