一些参考资料:
[1] 李宏毅机器学习教学视频 semi-supervise
[2] 李宏毅视频的文字稿
(上面两个资料的讲解顺序是:semi-supervised generative model --> low density assumption --> smooth assumption)
[3] A survey on semi-supervised learning. Engelen et al. 2018.
[4] MixMatch (bilibili视频讲解)
以下内容是对上述资料的总结。
1. Why does semi-supervised learning help?
The distribution of the unlabeled data tell us something.
unlabeled data虽然只有input,没有label,但它的分布,却可以告诉我们一些事情 (前提是用上一些假设)
比如没有unlabeled的data的时候,boundary是这样的:
有unlabeled的话,boundary可能就是这样的了:

2. When does semi-supervised learning work?
Unlabelled data is only useful if it carries information useful for label prediction that is not contained in the labelled data alone or cannot be easily extracted from it.
Themain takeaway from these observations is that semi-supervised learning should not be seen as a guaranteed way of achieving improved prediction performance by the mere introduction of unlabelled data. Rather, it should be treated as another direction in the process of finding and configuring a learning algorithm for the task at hand.
3. Three Assumption
smoothness assumption: if two samples x and x' are close in the input space, their labels y and y' should be the same.
low-density assumption: the decision boundary should not pass through high-density areas in the input space.
manifold assumption: data points on the same low-dimensional manifold should have the same label.
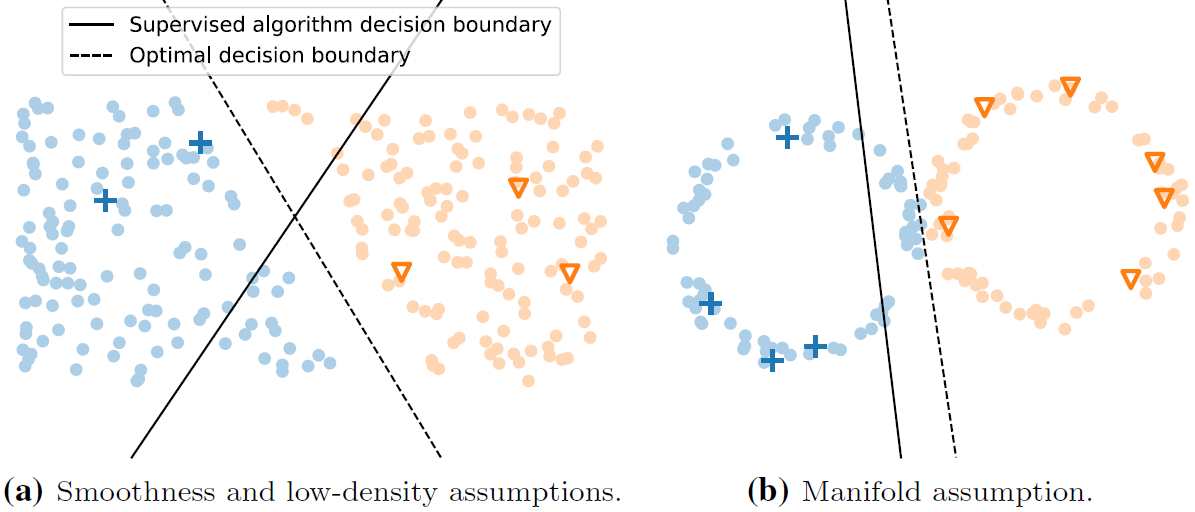
low-density assumption can be considered the counter part of the smoothness assumption for the underlying data distribution. 所以李宏毅视频中是这么介绍smooth assumption的:
假设下图是data的分布,x1 ,x2 ,x3是其中的三笔data,如果单纯地看x的相似度,显然x2和x3更接近一些,但对于smoothness assumption来说,x1和x2是处于同一块区域的,它们之间可以有一条相连的路径;而x2与x3之间则是“断开”的,没有high density path,因此x1与x2更“像”。

4. Empirical evaluation of semi-supervised learning methods
- It is important to establish high-quality supervised baselines to allow for proper assessment of the added value of the unlabelled data.
- In research, data sets used for evaluating semi-supervised learning algorithms are usually obtained by simply removing the labels of a large amount of data points from an existing supervised learning data set.
- In practice, the choice of data sets and their partitioning can have significant impact on the relative performance of different learning algorithms.
- Some algorithms may work well when the amount of labelled data is limited and perform poorly when more labelled data is available; others may excel on particular types of data sets but not on others.
- To provide a realistic evaluation of semi-supervised learning algorithms, researchers should thus evaluate their algorithms on a diverse suite of data sets with different quantities of labelled and unlabelled data.
5. Taxonomy of semi-supervised learning methods
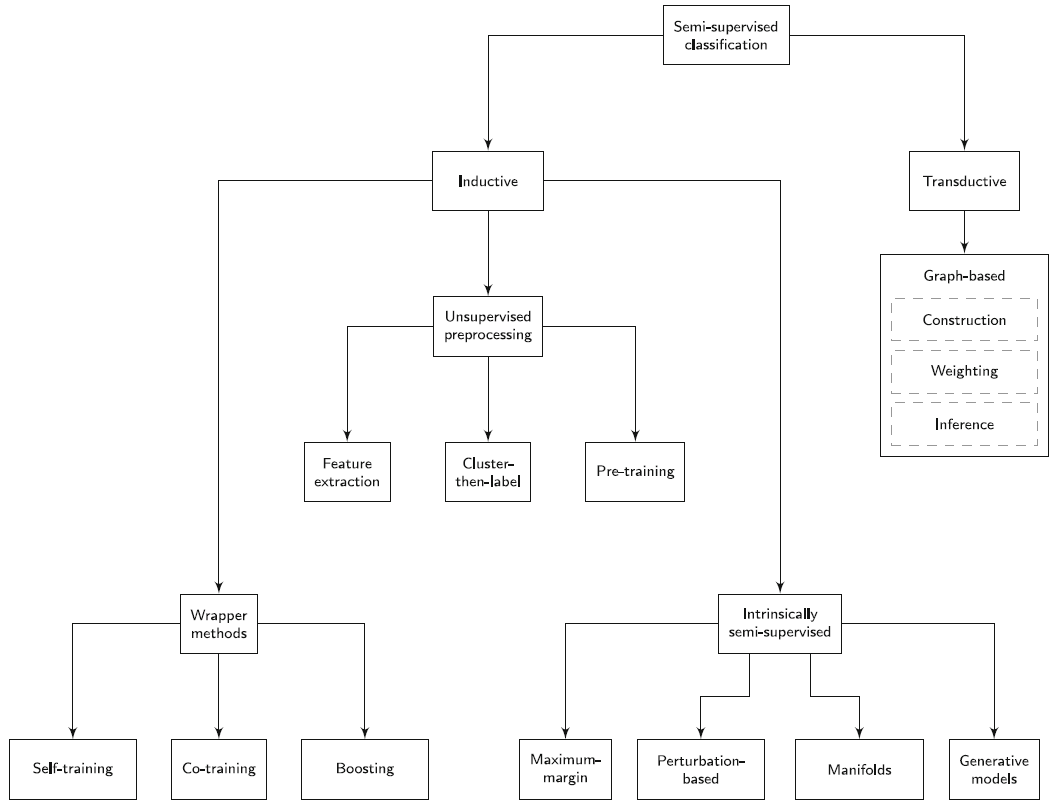
- Inductive methods attempt to find a classification model, whereas transductive methods are solely concerned with obtaining label predictions for the given unlabelled data points.
- Inductive methods, like supervised learning methods, yield a classification model that can be used to predict the label of previously unseen data points. Transductive methods do not yield such a model, but instead directly provide predictions.
- Inductive methods involve optimization over prediction models, whereas transductive methods optimize directly over the predictions.
6. Inductive methods
Inductive methods aim to construct a classifier that can generate predictions for any object in the input space.
6.1. Wrapper methods
Wrapper methods are to first train classifiers on labelled data, and to then use the predictions of the resulting classifiers to generate additional labelled data. The classifiers can then be re-trained on this pseudo-labelled data in addition to the existing labelled data.
6.1.1. Self-training
- Self-training methods consist of a single supervised classifier.
- The selection procedure for data to be pseudo-labelled is of particular importance. In typical self-training settings, where this selection is made based on prediction confidence, the quality of the confidence estimates significantly influences algorithm performance.
6.1.2. Co-training
- Co-training is an extension of self-training to multiple supervised classifiers. In co-training, two or more supervised classifiers are iteratively trained on the labelled data, adding their most confident predictions to the labelled data set of the other supervised classifiers in each iteration.
- For co-training to succeed, it is important that the base learners are not too strongly correlated in their predictions. If they are, their potential to provide each other with useful information is limited.
- These classifiers exchange information through unlabelled data, for which different learners predict different labels.
6.1.3. Boosting
Ensemble classifiers consist of multiple base classifiers, which are trained and then used to form combined predictions.
6.2. Unsupervised preprocessing
这类方法潜在地包含两个步骤:第一步,feature extraction, clustering;第二步,supervise classify。
6.2.1. Feature extraction
- Principal component analysis, Autoencoder, ...
- they inherently act on the assumption that the input space contains lower-dimensional substructures on which the data lie.
6.2.2. Cluster-then-label
These mehtods first apply an unsupervised or semi-supervised clustering algorithm to all available data, and use the resulting clusters to guide the classification process.
6.2.3. Pre-training
- Unlabelled data is used to guide the decision boundary towards potentially interesting regions before applying supervised training.
- For deep learning methods, the unsupervised pre-training aim to guide the parameters (weights) of a network towards interesting regions in model space using the unlabelled data, before fine-tuning the parameters with the labelled data.
- Unsupervised pre-training guides the neural network model towards regions in model space that provide better generalization.
6.3. Intrinsically semi-supervised methods
These methods directly optimize an objective function with components for labeled and unlabeled samples.
也就是说,这类方法的优化目标函数至少有2项,一项是关于labeled data,另一项是关于unlabeled data。
6.3.1. Maximum-margin methods
这类方法会应用到low-density assumption。
One can incorporate knowledge from the unlabelled data to determine where the density is low and thus, where a large margin can be achieved.
support vector machine (SVM): 人们提出了各种方法把unlabeled data加入到优化目标函数中。
Gaussian processes: incorporating the unlabelled data points into the likelihood function.
Density regularization: 把各个class的概率分布放到损失函数中。explicitly incorporate the amount of overlap between the estimated posterior class probabilities into the cost function. When there is a large amount of overlap, the decision boundary passes through a high-density area, and when there is a small amount of overlap, it passes through a low-density area.
6.3.2. Perturbation-based methods
这类方法的核心思想是,对于一个样本,给它一点小扰动(噪声),它的标签不变。
The smoothness assumption entails that a predictive model should be robust to local perturbations in its input. This means that, when we perturb a data point with a small amount of noise, the predictions for the noisy and the clean inputs should be similar. Since this expected similarity is not dependent on the true label of the data points, we can make use of unlabelled data.
Many different methods exist for incorporating the smoothness assumption into a given learning algorithm. For instance, one could apply noise to the input data points, and incorporate the difference between the clean and the noisy predictions into the loss function. Alternatively, one could implicitly apply noise to the data points by perturbing the classifier itself. These two approaches give rise to the category of perturbation-based methods.
Ladder networks:the underlying idea is that latent representations that are useful for input reconstruction can also facilitate class prediction. 可参考A survey on semi-supervised learning文中的介绍,或者是原论文Semi-Supervised Learning with Ladder Networks,或者是博客阶梯网络Ladder Network_sxt1001的博客-CSDN博客_ladder network。
Pseudo-ensembles: Instead of explicitly perturbing the input data, one can also perturb the neural network model itself.
$prod$-model: Instead of comparing the activations of the unperturbed parent model with those of the perturbed models in the cost function, one can also compare the perturbed models directly. 也就是说,直接比较扰动之后的多个模型的activations,而不是扰动的与未扰动的模型的activations之间的比较。
Temporal ensembling: they compare the activations of the neural network at each epoch to the activations of the network at previous epochs. In particular, after each epoch, they compare the output of the network to the exponential moving average of the outputs of the network in previous epochs. 关于exponential moving average可参考理解滑动平均(exponential moving average)。This approach—dubbed temporal ensembling, because it penalizes the difference in the network outputs at different points in time during the training process。
Mean teacher: Temporal ensembling的缺点是 intervals. Since the activations for each input are only generated once per epoch, it takes a long time for the activations of unlabelled data points to influence the inference process. Tarvainen and Valpola (2017) attempted to overcome this problem by considering moving averages over connection weights, instead of moving averages over network activations. Specifically, they suggested calculating the exponential moving average of weights at each training iteration, and compared the resulting final-layer activations to the final-layer activations when using the latest set of weights.
Virtual adversarial training: 这类方法把perturbation的方向也考虑进去了,也就是说扰动不是各向同性的。这样做的原因是:it has been suggested in several studies that the sensitivity of neural networks to perturbations in the input is often highly dependent on the direction of these perturbations.
6.3.3. Manifolds
manifold regularization techniques, which define a graph over the data points and implicitly penalize differences in predictions for data points with small geodesic distance.
manifold approximation techniques, which explicitly estimate the manifoldsMon which the data lie and optimize an objective function accordingly.
6.4. Generative models
Mixture models,如高斯混合模型。
Generative adversarial networks
Variational autoencoders
7. Transductive methods
Unlike inductive algorithms, transductive algorithms do not produce a predictor that can operate over the entire input space. Instead, transductive methods yield a set of predictions for the set of unlabelled data points provided to the learning algorithm.
Transductive methods typically define a graph over all data points, both labelled and unlabelled, encoding the pairwise similarity of data points with possiblyweighted edges. An objective function is then defined and optimized, in order to achieve two goals:
- For labelled data points, the predicted labels should match the true labels.
- Similar data points, as defined via the similarity graph, should have the same label predictions.