罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
字符 数值
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。
X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。
C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。
给定一个罗马数字,将其转换成整数。输入确保在 1 到 3999 的范围内。
示例 1:
输入: "III"
输出: 3
示例 2:
输入: "IV"
输出: 4
示例 3:
输入: "IX"
输出: 9
示例 4:
输入: "LVIII"
输出: 58
解释: L = 50, V= 5, III = 3.
示例 5:
输入: "MCMXCIV"
输出: 1994
解释: M = 1000, CM = 900, XC = 90, IV = 4.
方法一:
照题目的描述,可以总结如下规则:
罗马数字由 I,V,X,L,C,D,M 构成;
当小值在大值的左边,则减小值,如 IV=5-1=4;
当小值在大值的右边,则加小值,如 VI=5+1=6;
由上可知,右值永远为正,因此最后一位必然为正。
一言蔽之,把一个小值放在大值的左边,就是做减法,否则为加法。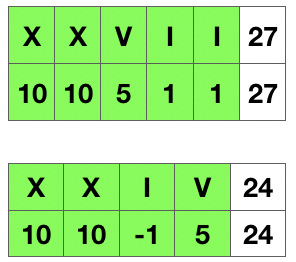
在代码实现上,可以往后看多一位,对比当前位与后一位的大小关系,从而确定当前位是加还是减法。当没有下一位时,做加法即可。
也可保留当前位的值,当遍历到下一位的时,对比保留值与遍历位的大小关系,再确定保留值为加还是减。最后一位做加法即可。
然后对字符串进行遍历,由于组合只有两种,一种是 1 个字符,一种是 2 个字符,其中 2 个字符优先于 1 个字符
先判断两个字符的组合在哈希表中是否存在,存在则将值取出加到结果中,并向后移2个字符。不存在则将判断当前 1 个字符是否存在,存在则将值取出加到结果中,并向后移 1 个字符
遍历结束返回结果

对于用hash的情况,其实java还有C++实现起来都是很容易的,但对于C而言则是非常麻烦的,需要自己实现整套HASH相关的操作,包括初始化,添加,遍历,释放整个hash表等的操作
虽然最后跑了一遍,时间比方法一还要长好多,但是为了能完整了看出来,用C来实现的整个过程,而且,其中我用到的HASH的操作,都是通用的,也就是说,如果其他的问题,也需要
引入HASH表才能实现的话,那么,可以直接把其中的代码拿走,这得益于C中指针的使用,以及struct list_head的使用,对于计算哈希值的算法,我采用的是time33,稍微做了一些修改
但不影响。
代码实现如下:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define HASH_SIZE 1024
struct list_head{
struct list_head *prev;
struct list_head *next;
};
struct roman_int{
struct list_head list;
char *key;
int value;
};
unsigned long hash33(char * key, int len){
unsigned long hash_id=0;
int ii=0;
for(;ii<len;ii++){
hash_id=hash_id*33+key[ii];
}
return hash_id;
}
struct list_head hash_map[HASH_SIZE];
void init_hash_map(){
int ii=0;
for(;ii<HASH_SIZE;ii++){
hash_map[ii].prev=hash_map[ii].next=&hash_map[ii];
}
}
void list_add_tail(struct list_head * new, struct list_head * head){
if(head->next == head && head->prev== head){
new->next=head;
new->prev=head;
head->next=new;
head->prev=new;
}else{
new->next=head;
new->prev=head->prev;
head->prev->next=new;
head->prev=new;
}
}
int search_map(char *s , int len, int * value){
int hash_id=hash33(s, len)%HASH_SIZE;
int ret=0;
struct list_head *head =&hash_map[hash_id];
struct list_head * ptr=NULL;
for(ptr=head->next;ptr!=head;ptr=head->next){
struct roman_int * node= (struct roman_int *)ptr;
if(!memcmp(node->key, s, len)){
*value=node->value;
ret=1;
goto end;
}
}
end:
return ret;
}
void destroy_hash_map(){
int ii=0;
for(;ii<HASH_SIZE;ii++){
if(hash_map[ii].prev!= &hash_map[ii] || hash_map[ii].next!= &hash_map[ii]){
struct list_head *ptr=NULL;
struct list_head *head=NULL;
head=&hash_map[ii];
for(ptr=head->next; ptr!=head; ptr=head->next){
ptr->prev->next=ptr->next;
ptr->next->prev=ptr->prev;
free(ptr);
}
}
}
}
int romanToInt(char * s){
int all_int[13]={1000, 900, 500, 400, 100, 90, 50, 40, 10, 9, 5, 4, 1};
char * all_roman[13]={"M", "CM", "D", "CD", "C", "XC", "L", "XL", "X", "IX", "V", "IV", "I"};
int ii=0;
init_hash_map();
for(;ii<13;ii++){
struct roman_int * ptr=malloc(sizeof(struct roman_int));
ptr->key=all_roman[ii];
ptr->value=all_int[ii];
int hash_id=hash33(ptr->key, strlen(ptr->key))%HASH_SIZE;
list_add_tail(&ptr->list, &hash_map[hash_id]);
}
int len=strlen(s);
int sum=0;
for(ii=0;ii<len;){
int value=0;
if(ii+1<len && search_map(s+ii, 2, &value)){
sum+=value;
ii+=2;
}else{
search_map(s+ii,1, &value);
sum+=value;
ii++;
}
}
destroy_hash_map();
return sum;
}
int main(int argc, char ** argv){
int ret=romanToInt(argv[1]);
printf("ret=[%d]
", ret);
}
作者:guanpengchn
链接:https://leetcode-cn.com/problems/roman-to-integer/solution/hua-jie-suan-fa-13-luo-ma-shu-zi-zhuan-zheng-shu-b/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:donespeak链接:https://leetcode-cn.com/problems/roman-to-integer/solution/yong-shi-9993nei-cun-9873jian-dan-jie-fa-by-donesp/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/roman-to-integer
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。