下载
官网地址:https://www.apache.org/dyn/closer.lua/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz
验证Java是否安装
java -verison
解压安装
tar -zxvf jdk-14.0.1_linux-x64_bin.tar.gz
mv jdk-14.0.1 /usr/local/java
验证Scala是否安装
scala -verison
wget https://downloads.lightbend.com/scala/2.13.1/scala-2.13.1.tgz
tar xvf scala-2.13.1.tgz
mv scala-2.13.1 /usr/local/
- 设置jdk与scala的环境变量
vi /etc/profile
export JAVA_HOME=/usr/local/java
export SPARK_HOME=/usr/local/spark
export CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH:$SPARK_HOME/bin
source /etc/profile
- 再次验证一下是否安装成功
scala -version
java -verison
安装spark
- 解压并移动到相应的目录
tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz
mv spark-2.4.5-bin-hadoop2.7 /usr/local/spark
- 设置spark环境变量
vi /etc/profile
export PATH=$PATH:/usr/local/spark/bin
保存,刷新
source /etc/profile
- 验证一下spark shell
spark-shell
出现以下信息,即成功

设置Spark主结点
spark配置都提供了相应的模板配置,我们复制一份出来
cd /usr/local/spark/conf/
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
- 设置主结点Master的IP
SPARK_MASTER_HOST='192.168.56.109'
JAVA_HOME=/usr/local/java
- 如果是单机启动
./sbin/start-master.sh
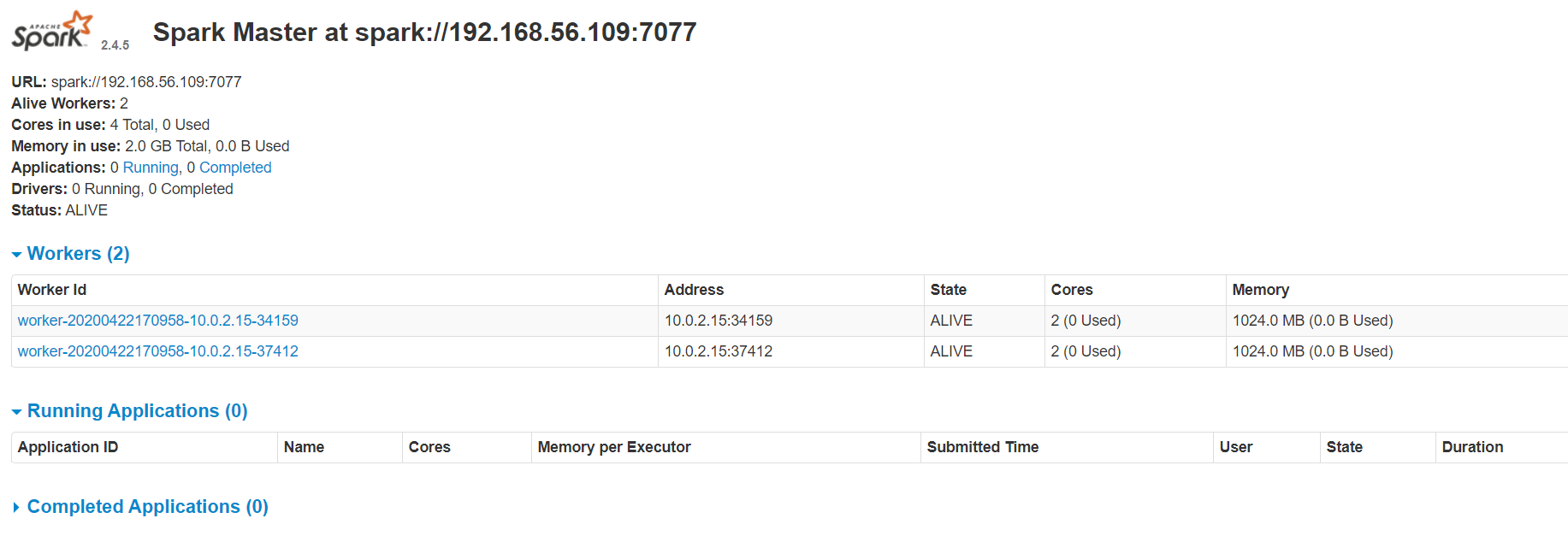
- 打开 http://192.168.56.109:8080/
出现以下界面即成功:

- 停止
./sbin/stop-master.sh
- 设置hosts
192.168.56.109 master
192.168.56.110 slave01
192.168.56.111 slave02
免密登录
Master上执行
ssh-keygen -t rsa -P ""
生成三个文件

将id_rsa.pub复制到slave,注意authorized_keys就是id_rsa.pub,在slave机器上名为authorized_keys,操作
scp -r id_rsa.pub root@192.168.56.110:/root/.ssh/authorized_keys
scp -r id_rsa.pub root@192.168.56.111:/root/.ssh/authorized_keys
cp id_rsa.pub authorized_keys
到slava机器上
chmod 700 .ssh
- 检查一下是否可以免密登录到slave01,slave02
ssh slave01
ssh slave02
Master与Slave配置worker结点
cd /usr/local/spark/conf
cp slaves.template slaves
加入两个slave,注意:slaves文件中不要加master,不然master也成为一个slave结点
vi slaves
slave01
slave02
Master结点启动
cd /usr/local/spark
./sbin/start-all.sh
如果出现 JAVA_HOME is not set 错误,则需要在slave结点的配置目录中的spark-env.sh中加入JAVA_HOME=/usr/local/java
如果启动成功访问:http://192.168.56.109:8080/,会出现两个worker
本地开发
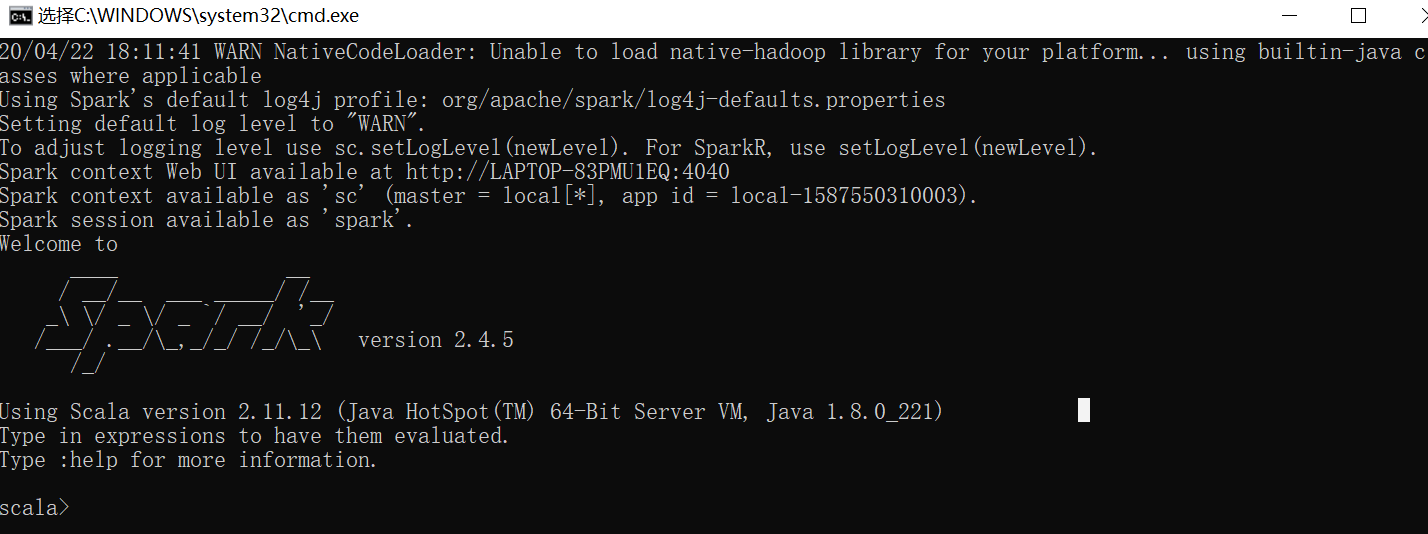
将上面spark-2.4.5-bin-hadoop2.7解压到本地,到bin目录双击spark-shell.cmd,不出意外应该会报错
Could not locate executable nullinwinutils.exe in the Hadoop binaries.
错误原因是因为没有下载Hadoop windows可执行文件。因为我们本地没有hadoop环境,这里可以用winutils来模拟,并不需要我们真的去搭建hadoop
可以到这里下载,如果要下载其它版本的可以自行选择
- 设置本机环境变量

再次重启,可以看到如下信息即成功
-
idea里Run/Debug配置里加入以下环境变量

-
idea里还需要加入scala插件,后面可以愉快的用data.show()查看表格了


请关注,后续有更精彩的文章分享
