flume采集过程:
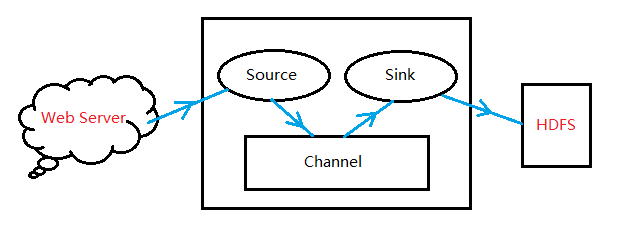
#说明:案例是flume监听目录/home/hadoop/flume_kafka采集到kafka;
启动集群
启动kafka,
启动agent,
flume-ng agent -c . -f /home/hadoop/flume-1.7.0/conf/myconf/flume-kafka.conf -n a1 -Dflume.root.logger=INFO,console
开启消费者
kafka-console-consumer.sh --zookeeper hdp-qm-01:2181 --from-beginning --topic mytopic
生产数据到kafka
数据目录:
vi /home/hadoop/flume_hbase/word.txt
12345623434
配置文件
vi flume-kafka.conf
#Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir=/home/hadoop/flume_kafka
# Describe the sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = mytopic
a1.sinks.k1.kafka.bootstrap.servers = hdp-qm-01:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.ki.kafka.producer.compression.type = snappy
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1