一、scrapy的安装:
本文基于Anacoda3,
Anacoda2和3如何同时安装?
将Anacoda3安装在C:ProgramDataAnaconda2envs文件夹中即可。
如何用conda安装scrapy?
安装了Anaconda2和3后,

如图,只有一个命令框,可以看到打开的时候:
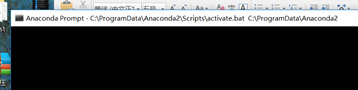
可以切到Anaconda3对应的路径下即可。
安装的方法:cmd中:conda install scrapy即可。
当然,可能会出现权限的问题,那是因为安装的文件夹禁止了读写。可以如图:
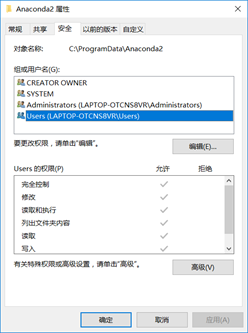
将权限都设为“允许“。
注意:此时虽然scapy安装上了,但是在cmd中输入scapy可能会不认,可以将安装scrapy.exe的路径添加到环境变量中。
二、scapy的简单使用
例子:爬取图片
1、 创建scrapy工程
譬如,想要创建工程名:testImage
输入:scrapy startproject testImage
即可创建该工程,按照cmd中提示的依次输入:
cd testImage
scrapy genspider getPhoto www.27270.com/word/dongwushijie/2013/4850.html
其中:在当前项目中创建spider,这仅仅是创建spider的一种快捷方法,该方法可以使用提前定义好的模板来生成spider,后面的网址是一个采集网址的集合,即为允许访问域名的一个判断。注意不要加http/https。
至此,可以在testImage estImagespiders中找到创建好的爬虫getPhoto.py,可以在此基础上进行修改。
2、创建爬虫
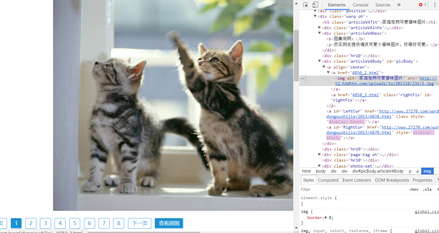
如图,可以在图片的位置右键,检查,查看源码,在图片所在的位置处,将xpath拷贝出来。
此时,可以找出图片的地址:
class GetphotoSpider(scrapy.Spider):
name = 'getPhoto'
allowed_domains = ['www.27270.com']
start_urls = ['http://www.27270.com/word/dongwushijie/2013/4850.html']
def parse(self, response):
urlImage = response.xpath('//*[@id="picBody"]/p/a[1]/img/@src').extract()
print(urlImage)
pass
此时,注意网络路径的正确书写,最后没有/,
http://www.27270.com/word/dongwushijie/2013/4850.html/
此时将4850.html 当作了目录,会出现404找不到路径的错误!
3、 下载图片
items.py:
class PhotoItem(scrapy.Item):
name = scrapy.Field()
imageLink = scrapy.Field()
pipelines.py:
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class ImagePipeline(ImagesPipeline):
def get_media_requests(self,item,info):
image_link = item['imageLink']
yield scrapy.Request(image_link)
settings.py:
IMAGES_STORE = r"C:Users24630Desktop est"
另外,对于上面的网址,还需要ROBOTSTXT_OBEY = False
并且,访问该网址会出现302错误,这是一个重定向的问题,
MEDIA_ALLOW_REDIRECTS =True
设置该选项,就可以正确下载,但是下载的还是不对,问题不好解决。
当然在爬虫中,还要对items赋值:
from testImage import items
。。。
for urllink in urlImage:
item = items.PhotoItem()
item['imageLink'] = urllink
三、 进一步爬取(读取下一页)
# -*- coding: utf-8 -*-
import scrapy
from testImage import items
class GetphotoSpider(scrapy.Spider):
name = 'getPhoto'
allowed_domains = ['www.wmpic.me']
start_urls = ['http://www.wmpic.me/93912']
def parse(self, response):
#//*[@id="content"]/div[1]/p/a[2]/img
urlImage = response.xpath('//*[@id="content"]/div[1]/p/a/img/@src').extract()
print(urlImage)
for urllink in urlImage:
item = items.PhotoItem()
item['imageLink'] = urllink
yield item
ifnext = response.xpath('//*[@id="content"]/div[2]/text()').extract()[0]
# 当没有下一篇,即最后一页停止爬取
if("下一篇" in ifnext):
nextUrl = response.xpath('//*[@id="content"]/div[2]/a/@href').extract()[0]
url=response.urljoin(nextUrl)
yield scrapy.Request(url=url)
此时,便可以看到路径下的下载后的文件了。(由于该网址每页的图片所在的xpath都不一样,故下载的图片不全)