本文内容:
- 什么是seq2seq模型
- Encoder-Decoder结构
- 常用的四种结构
- 带attention的seq2seq
- 模型的输出
- seq2seq简单序列生成实现代码
一、什么是seq2seq模型
seq2seq全称为:sequence to sequence ,是2014年被提出来的一种Encoder-Decoder结构。其中Encoder是一个RNN结构(LSTM、GRU、RNN等)。
主要思想是输入一个序列,通过encoder编码成一个语义向量c(context),然后decoder成输出序列。这个结构重要的地方在于输入序列和输出序列的长度是可变的。
应用场景:机器翻译、聊天机器人、文档摘要、图片描述等
二、Encoder-Decoder结构
最初Encoder-Decoder模型由两个RNN组成

这个结构可以看到,输入一个句子后,生成语义向量c,编码过程比较简单;
解码时,每个c、上一时刻的yi-1,以及上一时刻的隐藏层状态si-1都会作用到cell,然后生成解码向量。
三、常用的四种seq2seq结构
对于上面模型中的编码模型,是一种比较常用的方式,将编码模型最后一个时刻的隐层状态做为整个序列的编码表示,但是实际应用中这种效果并不太好。
因此,对于常用的模型中,通常直接采用了整个序列隐层编码进行求和平均的方式得到序列的编码向量。因此通常有四种模式:
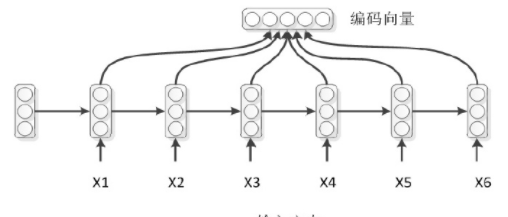
对于解码模式:
普通作弊模式
如上,编码时,RNN的每个时刻除了上一时刻的隐层状态,还有输入字符,而解码器没有这种字符输入,用context作为输入,即为一种比较简单的模式。
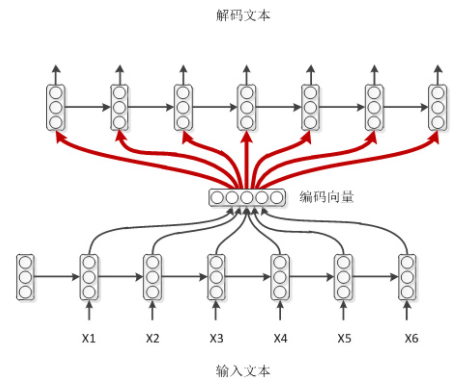
学霸模式

如上是一种带输出回馈的方式。输入即为上一时刻的输出。
学弱模式
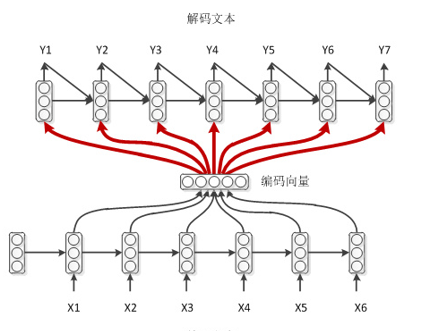
学渣作弊模式
学渣作弊模式就是在学弱的基础上在引入Attention机制,加强对于编码输入的特征的影响。
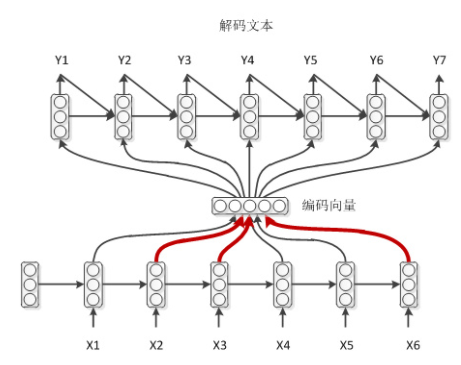
下面主要梳理带attention机制的seq2seq模型:
四、带attention的seq2seq
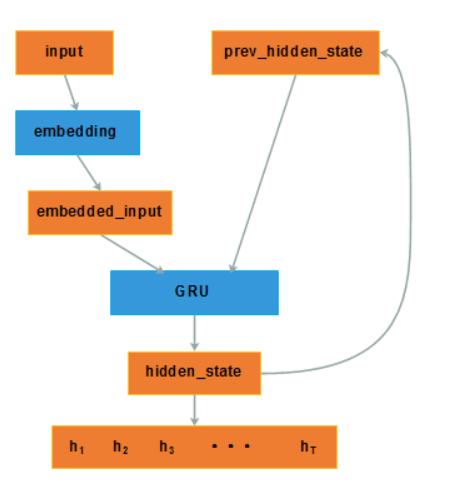
编码器如上,公式不再赘述。
注意:对于使用双向的GRU编码时,得到的两个方向上的hi,通常进行contact作为输入。

对于解码的过程,可以看到,在语义向量C的求解的过程中,添加了attention。
如上,当计算Y4时,上一时刻解码的隐层状态会作用于编码器的输入,这样会从新计算context,过程就是这样的。公式表示:
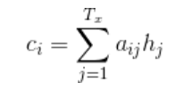
其中,i对应的是翻译的第i个字,j对应的是输入的第j个字。

其中的aij是一个归一化的值,归一化的方法为softmax。其中eij为attention计算的输出,这么做的原因是因为,本质上这个权值是一个概率值,如果直接用eij的话,context缩放变大。
![]()
s为解码器的隐层状态,h为编码器的输出。
五、模型输出转化为语句
GRU的输出已经包含了待生成的词的信息了,但是要生成具体的词,还需要进一步操作。
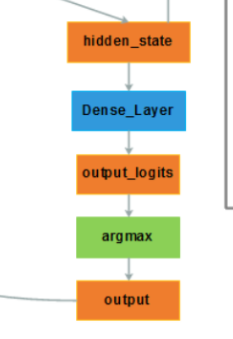
如上图,output是一个具体的词向量,这个词向量的获取是通过softmax获得的所有的语料库的词向量的概率最大的那一个词向量。
而softmax的输入通常是这个词典的维度,但这个维度的大小往往和GRU输出的维度并不对应,这时,通过一个全连接层(Dense_Layer)来做一个维度上的映射。
事实上,softmax可以简单理解为一个归一化操作,求的是概率。
六、使用seq2seq做序列生成
说白了,seq2seq就是两个lstm/GRU嘛,做序列生成的化,并不是一个十分复杂的过程,本文在网上流传的代码基础上进行裁剪,保留最简单的代码:
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import copy
vocab_size=256 #假设词典大小为 256
target_vocab_size=vocab_size
LR=0.006
inSize = 10
#outSize = 20 假设输入输出句子一样长
buckets=[(inSize, inSize)] #设置一个桶,主要是为了给model_with_buckets函数用
batch_size=1
input_data = np.arange(inSize)
target_data = copy.deepcopy(input_data)
np.random.shuffle(target_data)
target_weights= ([1.0]*inSize + [0.0]*0)
class Seq2Seq(object):
def __init__(self, source_vocab_size, target_vocab_size, buckets, size):
self.encoder_size, self.decoder_size = buckets[0]#因为只有一个桶,索引为0即可
self.source_vocab_size = source_vocab_size
self.target_vocab_size = target_vocab_size
cell = tf.contrib.rnn.BasicLSTMCell(size)
cell = tf.contrib.rnn.MultiRNNCell([cell])
def seq2seq_f(encoder_inputs, decoder_inputs, do_decode):
return tf.contrib.legacy_seq2seq.embedding_attention_seq2seq(
encoder_inputs, decoder_inputs, cell,
num_encoder_symbols=source_vocab_size,
num_decoder_symbols=target_vocab_size,
embedding_size=size,
feed_previous=do_decode)
# computational graph
self.encoder_inputs = []
self.decoder_inputs = []
self.target_weights = []
for i in range(self.encoder_size):
self.encoder_inputs.append(tf.placeholder(tf.int32, shape=[None], name='encoder{0}'.format(i)))
for i in range(self.decoder_size):
self.decoder_inputs.append(tf.placeholder(tf.int32, shape=[None], name='decoder{0}'.format(i)))
self.target_weights.append(tf.placeholder(tf.float32, shape=[None], name='weights{0}'.format(i)))
targets = [self.decoder_inputs[i] for i in range(len(self.decoder_inputs))]# - 1
# 使用seq2seq,输出维度为seq_length x batch_size x dict_size
self.outputs, self.losses = tf.contrib.legacy_seq2seq.model_with_buckets(
self.encoder_inputs, self.decoder_inputs, targets,
self.target_weights, buckets,
lambda x, y: seq2seq_f(x, y, False))
self.getPoints = tf.argmax(self.outputs[0],axis=2)#通过argmax,得到字典中具体的值,因为i只有一个批次,所以取0即可
self.trainOp = tf.train.AdamOptimizer(LR).minimize(self.losses[0])
def step(self, session, encoder_inputs, decoder_inputs, target_weights):
input_feed = {}
for l in range(self.encoder_size):
input_feed[self.encoder_inputs[l].name] = [encoder_inputs[l]]
for l in range(self.decoder_size):
input_feed[self.decoder_inputs[l].name] = [decoder_inputs[l]]
input_feed[self.target_weights[l].name] = [target_weights[l]]
output_feed = [self.losses[0],self.getPoints,self.trainOp]
outputs = session.run(output_feed, input_feed)
return outputs[0], outputs[1]
# 训练 LSTMRNN
if __name__ == '__main__':
# 搭建 LSTMRNN 模型
model= Seq2Seq(vocab_size, target_vocab_size, buckets, size=5)
sess = tf.Session()
saver=tf.train.Saver(max_to_keep=3)
sess.run(tf.global_variables_initializer())
# matplotlib可视化
plt.ion() # 设置连续 plot
plt.show()
# 训练多次
for i in range(100):
losses, points= model.step(sess, input_data, target_data, target_weights)
x = range(inSize)
plt.clf()
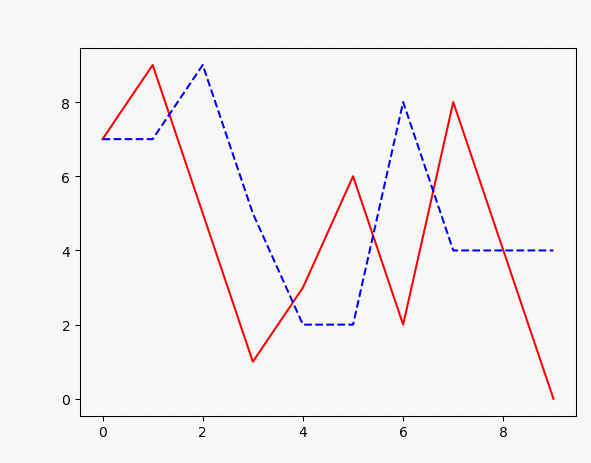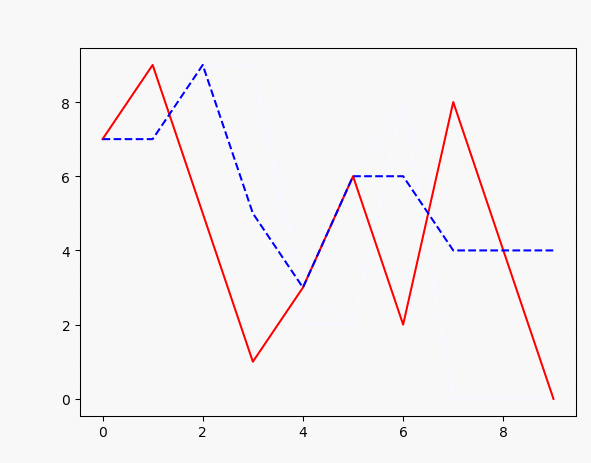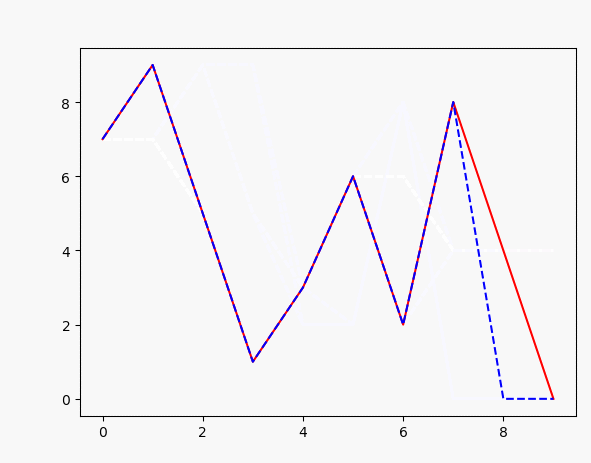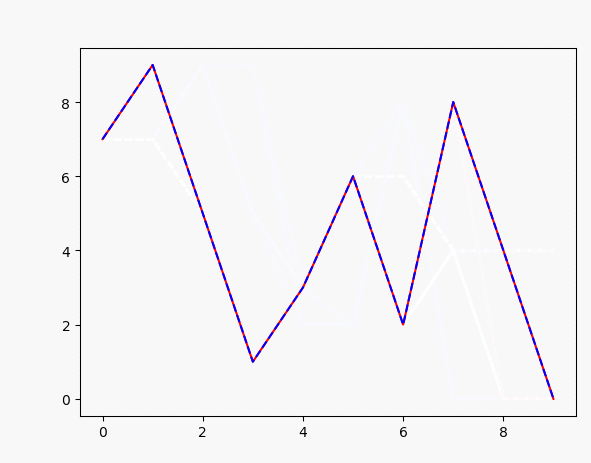
plt.plot(x, target_data, 'r', x, points, 'b--')#
plt.draw()
plt.pause(0.3) # 每 0.3 s 刷新一次
# 打印 cost 结果
if i % 20 == 0:
saver.save(sess, "model/lstem_text.ckpt",global_step=i)#
print(losses)
如上,可以很容易实现输入一个序列,然后训练生成另一个序列,效果如图: