本文主要包含以下内容:
一、什么是正则化
二、参数范数模型
2.1 L1正则和L2正则
2.2 为什么通过L1正则、L2正则能够防止过拟合
2.3 L2正则的表现
2.4 L1正则化为什么会产生稀疏解
2.5 L2正则为什么求解比较稳定
三、Dropout和集成方法
3.1 Dropout
3.2 集成方法bagging及boosting
一、什么是正则化
正则化即为对学习算法的修改,旨在减少泛化误差而不是训练误差。正则化的策略包括:
(1)约束和惩罚被设计为编码特定类型的先验知识
(2)偏好简单模型
(3)其他形式的正则化,如:集成的方法,即结合多个假说解释训练数据
在实践中,过于复杂的模型不一定包含数据的真实的生成过程,甚至也不包括近似过程,这意味着控制模型的复杂程度不是一个很好的方法,或者说不能很好的找到合适的模型的方法。实践中发现的最好的拟合模型通常是一个适当正则化的大型模型。
二、参数范数模型
对于线性模型,譬如线性回归、逻辑回归,可以使用简单有效的参数范数模型进行正则化。许多正则化方法通过对目标函数J添加惩罚项,其中α也被称为惩罚系数,限制模型的学习能力:

对于神经网络中,参数通常是包括权值w和偏置b,而我们通常对w做惩罚而不对偏置b做处理,这是因为不对b进行处理也不会有太大的影响。
2.1 L1正则和L2正则
L1正则项表示:
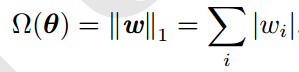
L2正则项表示:
![]()
2.2 为什么通过L1正则、L2正则能够防止过拟合
解释:
过拟合产生的原因通常是因为参数比较大导致的,通过添加正则项,假设某个参数比较大,目标函数加上正则项后,也就会变大,因此该参数就不是最优解了。
问:为什么过拟合产生的原因是参数比较大导致的?
答:过拟合,就是拟合函数需要顾忌每一个点,当存在噪声的时候,原本平滑的拟合曲线会变得波动很大。在某些很小的区间里,函数值的变化很剧烈,这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。
2.3 L2正则的表现
对于L2正则,其目标函数为:
![]()
进一步做简化分析,令w*作为未正则化的目标函数取得最小值时的权重向量(当然这个值是有可能会过拟合的),在w*的邻域对目标函数做二次近似(泰勒展开,因为极值点的导数为0,因此一阶项为0),其中用H表示该函数的Hessian矩阵(关于w),其表达式为:
![]()
当它取得最小值时,其梯度为0,梯度表达式:
![]()
为了研究权重衰减带来的影响,添加权重衰减的梯度,使用![]() 表示此时的最优点:
表示此时的最优点:
![]()
![]()
可以看到,当α趋向于0时,正则化的解和未正则化的解相近;当α增加时,会怎样呢?因为H是实对称的,可以分解为一个对角矩阵Λ和一组特征向量的标注正交基Q。
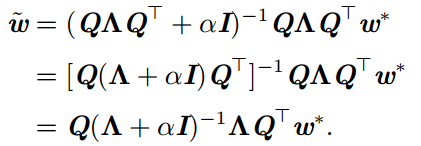
可以看到,权重衰减的效果是沿着由H的特征向量所定义的轴缩放w*。对于特征值较小的情况,加上α后的影响会比较大;而这种正则化的影响对于特征值大的数影响较小。
补充:
对于每个实对称矩阵都可以分解成实特征向量和实特征值:
![]()
其中,Q是A的特征向量组成的正交矩阵,Λ是对角矩阵。特征向量和特征值可以看作为方向和速度,如图,可以看到特征向量和特征值的作用,参考:
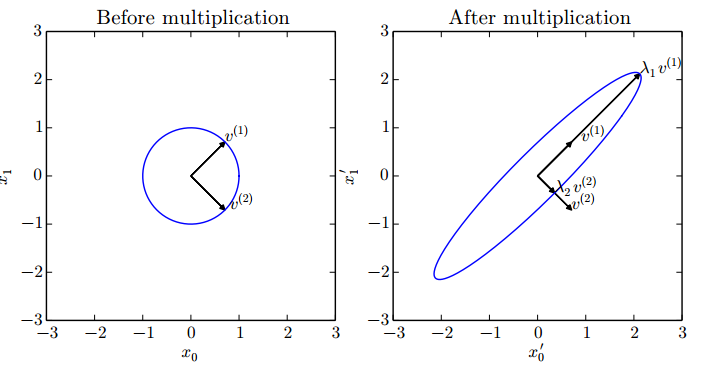
具体的缩放因子表示为:

即,若λi>>α时,正则化的影响较小,而λi<<α时,该参数分量wi缩减到0。
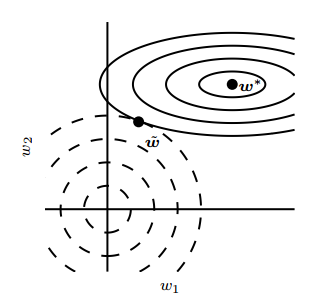
如图所示,对于正则化后的解为结合了缩放因子与原始解的结果,这个结果即表现为:当w1为梯度变化较小的方向,其拉伸作用会比较大;而w2上的拉伸作用比较小,也就是说,目标函数与约束条件的交点的坐标值与目标函数的梯度变化有关系,当噪声影响下,目标函数沿着w1轴移动,交点的影响不会太大的(缩放因子的影响)。
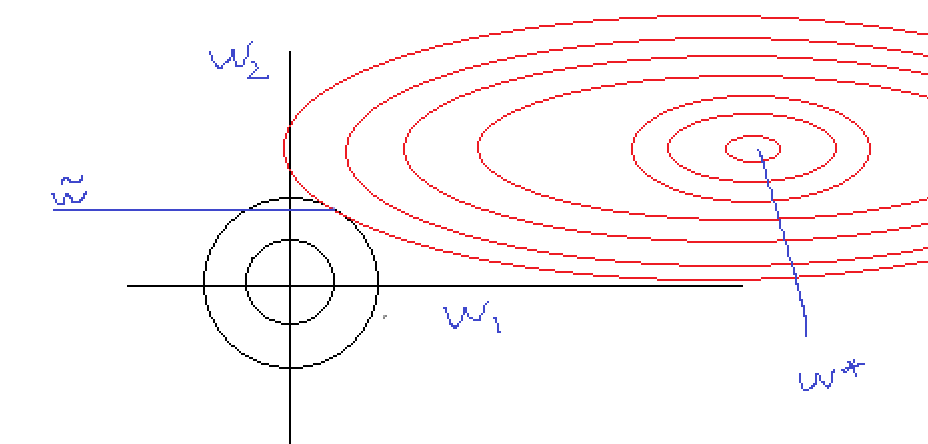
事实上,DeepLearning书中,对于该部分所表达的意思就是一个“在不重要的方向上对应的分类会在训练过程中因正则化衰减掉”,这个衰减的过程就是如图,对每次迭代时进行w的缩放,导致最终优化结果发生改变,梯度下降的路线给改了,原本要下降到最小值点的路径发生扭曲:
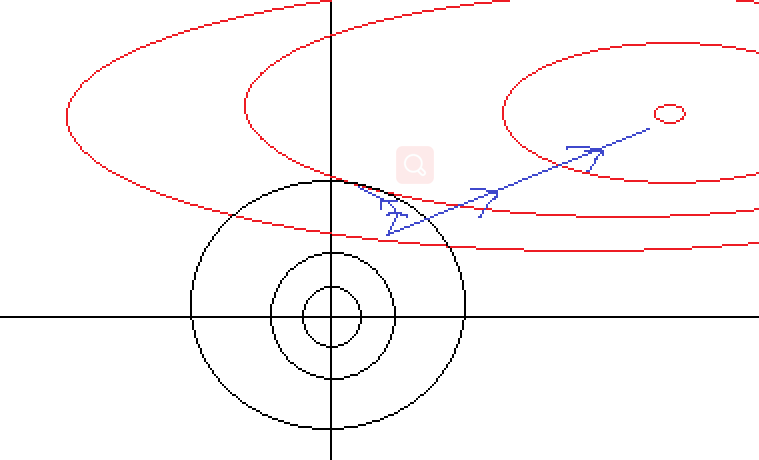
如上就可以解释了为什么L2正则等值线相交时为什么w1、w2可能会很小但等于0 的概率很低了,ps:对于w*,其如果存在稀疏解,则wi*一定在坐标轴上。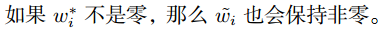
这个通过图是很容易陷入误区,因为很有可能画出如下的图,这样就解释不了了:
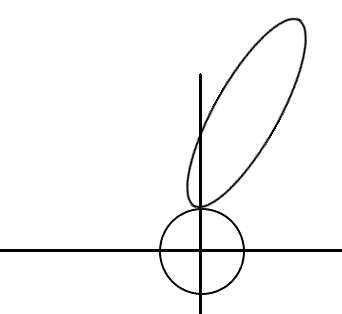
实际上真正的结果:

2.4 L1正则化为什么会产生稀疏解
对于为什么L1正则会产生稀疏解,如图:

但是我认为,这个图只能解释为什么会产生稀疏解,并不能解释为什么L1具有特征选择或者说时为什么能产生大量稀疏解的原因。
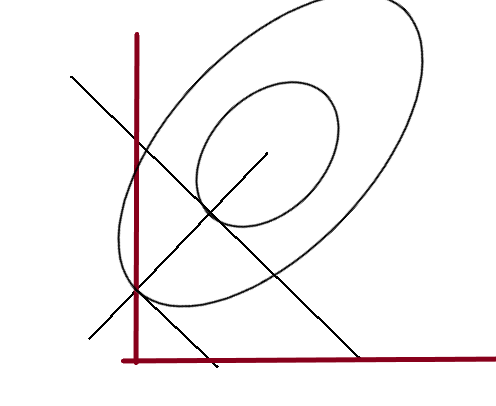
原因如上图所示,可以通过控制α,产生大量稀疏解。这也就是deeplearning一书中公式推导后的结论的直观理解:
![]()

对于上面的惩罚系数α的理解:
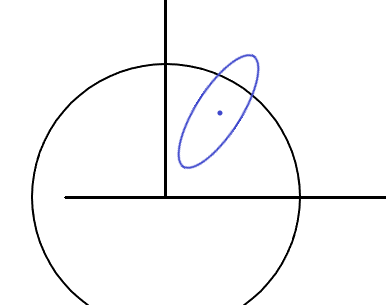
如图,设置了一个惩罚系数,结果把原有解包含了,这说明:惩罚系数设小了,对原有解没有影响。同理,越增大α越收缩圈,结合上面的图就可以解释为什么增大α能够获得稀疏解了吧。
2.5 L2正则为什么求解比较稳定
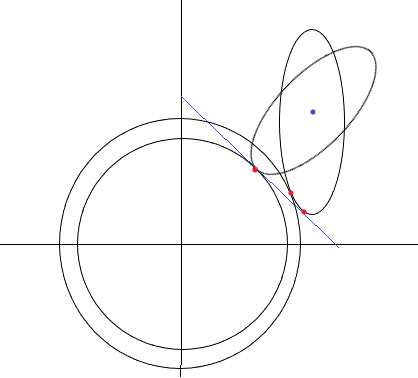
如图,可以看到,对于L2正则,如果原始的目标函数由于噪声的影响,发生偏移,可以看到,由于L2的约束函数的梯度存在一个变化的范围,比L1正则更容易在原最优解附近找到最优解,而L1正则则求解的变化比较大,因此L2求解更加稳定。
三、Dropout和集成方法
3.1 Dropout
Dropout提供了正则化一大类模型的方法,计算方便且功能强大。它不同于L1、L2正则项那样改变损失函数。而是改变模型本身。Dropout可以被认为是集成大量深层神经网络的使用Bagging的方法。Dropout提供一种廉价的Bagging集成近似,能够训练和评估指数级数量的神经网络。
假设训练的网络:
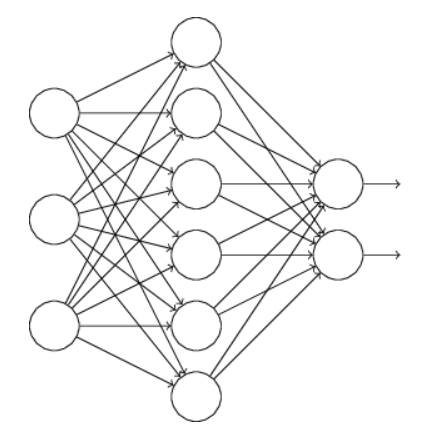
对于使用dropout技术的话,我们随机删除隐层的神经元,形成新的网络:

然后,我们通过前向求损失,反向传到损失,批量梯度下降完成一批,更新完w和b,然后继续随机删除隐藏层的神经元,继续批量梯度下降更新权值和偏置。
“when we dropout different sets of neurons, it's rather like we're training different neural networks. And so the dropout procedure is like averaging the effects of a very large number of different networks.”这也就解释了为什么Dropout能防止过拟合,实际上,就是Bagging策略,在Bagging中,每个模型在其相应的训练集上都收敛,而Dropout通常大部分模型都没有显示的被训练,因为子网络太多,我们单个步骤会采用一小批样本,训练一个子网,参数共享会使得剩余的子网继续训练这些参数。这些是仅有的区别,除了这些,Dropout和Bagging都一样,譬如:每个子网中遇到的训练集确实是有放回的采样原始训练集的一个子集。
3.2 集成方法bagging及boosting
Bagging是一种在原始数据集上通过有放回抽样重新选出S个新数据集来训练分类器的集成技术。其主要思想是通过模型平均来实现集成模型比单一模型更加正则化的目的。而不是所有集成算法都是如此,Boosting是增强算法的意思,也就是由弱分类器转变为强分类器的过程。在神经网络中,其可以理解为逐渐增强神经网络的隐层神经元的个数。因此,其正则化的主要方法是通过构建比单个模型容量更高的集成模型。
Bagging和Boosting的区别:
1)样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。