几个月之前,冬瓜哥给大家发了一份免费大餐,叫做《可视化存储智能——思路、设计与展现》,50页pdf文件,可谓是瓜哥为大家精心准备的一份盛大宴席。这个解决方案,是瓜哥当年从零开始一步一步雕刻而成,虽然只形成了图纸,最终也只有其中个把名词得到了应用之外,可惜没有落到实处,因为在之前那个平台瓜哥寻觅了许久,找不到能够与瓜哥一样有匠心而且有人力的人来一起实现之,瓜哥黯然离去,打算从此不问江湖事,但是人在江湖身不由己,瓜哥还不能做到了无牵挂,所以,在这里瓜哥打算把这份大餐,分章节发送到微信这种快餐信息工具上,以飨大家。
这次打算分享一下Raid2.0这个东西,“可视化存储智能”必须建立在一个底层数据布局充分灵活的基础上,对于传统存储来讲,Raid2.0无疑是个好胚子。所以,本节先说说Raid2.0,但是瓜哥这套解决方案,和Raid2.0确没有直接关系,有人可能认为“Raid2.0多么高大上啊”,我被忽悠了好久,感觉他们忽悠的时候,那逼格,帅呆了!哈哈,冬瓜哥要说,那是由于你自身的逼格不够,那就只能被忽悠。冬瓜哥对Raid2.0没什么感觉,因为冬瓜哥属于曾经沧海难为水,一个Raid2.0,不足以撼动冬瓜哥那已经对忽悠免疫的神经。Raid2.0只是冬瓜哥要造的这台超级跑车的底盘。
1.1 Raid1.0 和Raid1.5
在机械盘时代,影响最终IO性能的根本因素无非就是两个,顶端源头一个,也就是应用的IO调用方式和IO属性;底端源头一个,那就是数据最终是以什么形式、形态和形状存放在多少机械盘上的。应用如何IO调用完全不是存储系统可以控制的事情,所以从这个源头来解决性能问题对于存储系统来讲是无法做什么工作的。但是数据如何组织、排布,绝对是存储系统重中之重的工作。
这一点从Raid诞生开始就一直在不断的演化当中。举个最简单的例子,从Raid3到Raid4再到Raid5,Raid3当时设计的时候致力于单线程大块连续地址IO吞吐量最大化,为了实现这个目的,Raid3的条带非常窄,窄到每次上层下发的IO目标地址基本上都落在了所有盘上,这样几乎每个IO都会让多个盘并行读写来服务于这个IO,而其他IO就必须等待,所以我们说Raid3阵列场景下,上层的IO之间是不能并发的,但是单个IO是可以多盘为其并发的。所以,如果系统内只有一个线程(或者说用户、程序、业务),而且这个线程是大块连续地址IO追求吞吐量的业务,那么Raid3非常合适。但是大部分业务其实不是这样,而是追求上层的IO能够充分的到并行执行,比如多线程、多用户发出的IO能够并发的被响应,此时就需要增大条带到一个合适的值,让一个IO目标地址范围不至于牵动Raid组中所有盘为其服务,这样就有一定几率让一组盘同时响应多个IO,而且盘数越多,并发几率就越大。Raid4相当于条带可调的Raid3,但是Raid4独立校验盘的存在不但让其成为高故障率的热点盘,而且也制约了本可以并发的IO,因为伴随着每个IO的执行,校验盘上对应条带的教研块都需要被更新,而由于所有校验块只存放在这块盘上,所以上层的IO只能一个一个的顺着执行,不能并发。Raid5则通过把校验块打散在Raid组中所有磁盘从而实现了并发IO。大部分存储厂商提供针对条带宽度的设置。比如从32KB到128KB。假设一个IO请求读16KB,在一个8块盘做的Raid5组里,如果条带为32KB,则每块盘上的Segment为4KB,这个IO起码要占用4块盘,假设并发几率为100%,那么这个Raid组能并发两个16KB的IO,并发8个4KB的IO;如果将条带宽度调节为128KB,则在100%并发几率的条件下可并发8个小于等于16KB的IO。
讲到这里,我们可以看到单单是调节条带深度,以及优化校验块的布局,就可以得到迥异的性能表现。但是再怎么折腾,IO性能始终受限在Raid组那少的可怜的几块或者十几块盘上。为什么是几块或者十几块?难道不能把100块盘做成一个大Raid5组,然后把所有逻辑卷创建在它上面来增加每个逻辑卷的性能么?你不会选择这么做的,当一旦有一块坏盘,系统需要重构的时候,你会后悔当时的决定,因为你会发现此时整个系统性能大幅降低,哪个逻辑卷也别想好过,因为此时99块盘都在全速读出数据,系统计算XOR校验块,然后把校验块写入到热备盘中。当然,你可以控制降速重构,来缓解在线业务的IO性能,但是付出的代价就是增加了重构时间,重构周期内如果有盘再坏,那么全部数据荡然无存。所以,必须缩小故障影响域,所以一个Raid组最好是几块或者十几块盘。这比较尴尬,所以人们想出了解决办法,那就是把多个小Raid5/6组拼接成大Raid0,也就是Raid50/60,然后将逻辑卷分布在其上。当然,目前的存储厂商黔驴技穷,再也弄出什么新花样,所以它们习惯把这个大Raid50/60组成为“Pool”也就是池,从而迷惑一部分人,认为存储又在革新了,存储依然生命力旺盛。
那我在这里也不放顺水推舟忽悠一下,如果把传统的Raid组叫做Raid1.0,把Raid50/60叫做Raid1.5。我们其实在这里面可以体会出一种轮回式上升的规律,早期盘数较少,主要靠条带宽度来调节不同场景的性能;后来人们想通了,为何不用Raid50呢?把数据直接分布到几百块盘中,岂不快哉?上层的并发线程小块随机IO在底层可以实现大规模并发,而上层单线程的大块连续IO在底层则可以实现夸张的数百块磁盘并行读写服务于一个IO的效果,达到超高吞吐量。此时,人们昏了头,没人再去考虑另一个可怕的问题。
至这些文字落笔时仍没有人考虑这个问题,至少从厂商的产品动向里没有看出。究其原因,可能是因为另一轮底层的演变,那就是固态介质。底层的车轮是不断的提速的,上层的形态是轮回往复的,但有时候上层可能直接跨越式前进,跨掉了其中应该有的一个形态,这个形态或者转瞬即逝,亦或者根本没出现过,但是总会有人产生火花,即便这火花是那么微弱。
这个可怕问题其实被一个更可怕的问题盖过了,这个更可怕的问题就是重构时间过长。一块4TB的SATA盘,在重构的时候就算全速写入,其转速决定了其吞吐量极限也基本在80MB/s左右,可以算一下,需要58小时,实际中为了保证在线业务的性能,一般会限制在中速重构,也就是40MB/s左右,此时需要116小时,也就是5天五夜,一周时间,我敢打赌没有哪个系统管理员能在这一周内睡好觉。
1.2 Raid5EE 和Raid2.0
20 年前有人发明过一种叫做Raid5EE的技术,其目的有两个,第一个目的是把平时闲着没事干的热备盘用起来,第二个目的就是为了加速重构。见图1-2-1:
图1-2-1 Raid5EE
很显然,如果把图中用“H(hot spare)”表示的热备盘的空间也像校验盘一样,打散到所有盘上去的话,就会变成图右侧所示的布局,每个P块都跟着一个H块。这样整个Raid组能比原来多一块磁盘干活了。另外,由于H空间也打散了,当有一块盘损坏时,重构的速度可以被加快,因为此时可以多盘并发写入了。
然而,这么好的技术,却没有被广泛使用,同样都是打散,把P打散的Raid5得到了广泛应用,而把H打散的Raid5EE却没落了。至少我是找不出原因,这技术实现起来并不复杂,唯一一个想到的可能就是早期硬盘容量很小,几百GB,重构很快就能完成,所以没有强烈需求。
时过境迁,很多生错了年代的技术放在10年后可能会容光焕发,然而几乎所有人都会忘却这些技术的创始者,而被后来人忽悠的不亦乐乎。Raid2.0同样是这样的情况。然而Raid2.0并非像“Pool(Raid50/60)”一样纯忽悠(这也是我称之为Raid1.5的原因,半瓶水),还是有很大变革的。首先,条带不再与磁盘绑定,而是“浮动”于磁盘之上,也就是同样一个条带,比如“D1+D2+D3+P”就是一个由3个DataSegment和一个Parity Segment组成的条带,之前的做法是,必须由4块盘来承载这个条带,换个角度说,之前从没有人想过把条带作为认知中心,而都是把一个Raid组的里的盘作为中心,什么东西必须绑定在这些盘上,盘坏了就必须整盘重构,丝毫不去分析盘上的数据到底怎么分布的。条带浮动之后的结果如下图所示: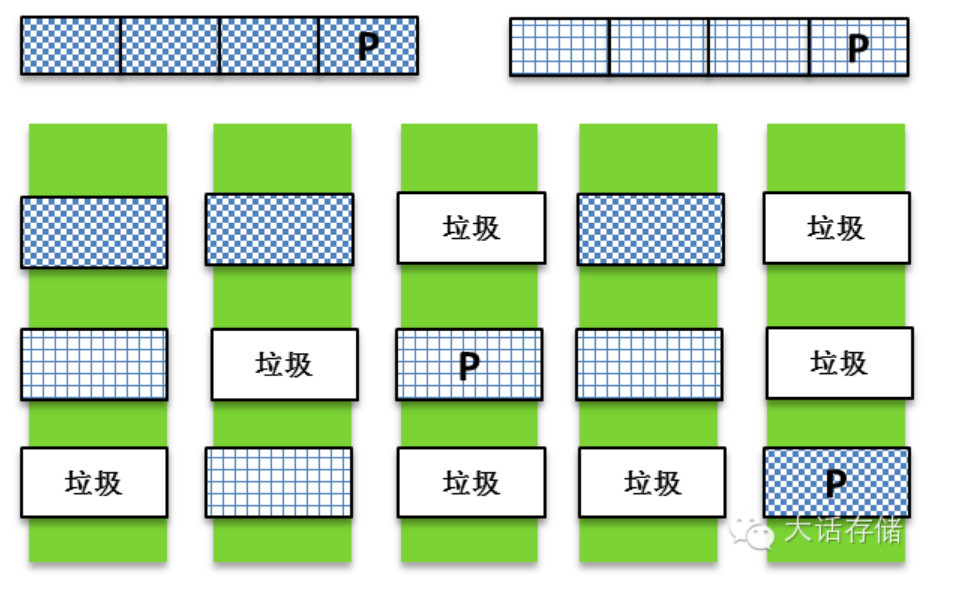
图1-2-2 Raid2.0
这完全颠覆了传统认知。首先,一个3D+1P的条带竟然可以放在5块盘里(实际上几块都行,1块也行!和盘数无关了)?其次天呐条带里的Segment怎么都是乱七八糟排列?感到惊讶说明你还有救,说明你还保持有人类最原始的好奇心。以条带为中心,条带得到了解放,解放意味着自由,自由意味着可以按照自己的思想做事,当然你得先有思想,没有思想的事物给它自由反而可能有反作用。条带为何会要努力挣扎以获得自由?就是因为它太看不惯那些不思进取和墨守成规了,拿着陈年的糠吃一辈子还自感良好的大有人在,这些人不但自己吃糠,而且还不许别人创新。当然,这一般不是工程师应用的素质。广大的工程师时刻都在创新。
传统Raid毫不关心条带是否已经被分配给逻辑卷,即便是有3/5的条带并没有分配给任何Lun,这块盘坏了之后,这3/5的垃圾数据一样会被重构,这是完全不必要的,但是又是必须进行的,因为如果不把这3/5的垃圾数据重构,那么新加入的盘和原来的盘在这3/5数据范围内是对不上的,如下图所示,如果不将垃圾块也重新重构然后写入热备盘,那么垃圾块D1 xor D2 xor D3 xor D4将≠垃圾块P,这属于不一致,是不能接受的。谁知道热备盘上这些块之前是什么内容?可以保证的是,如果不加处理,这些块是绝对和原来的盘上对应条带的块算出来的XOR结果不一致。所以,必须将垃圾块也一起重构,虽然垃圾重构之后还是垃圾,但是垃圾们之间最起码是能够保证XOR之后是一致的。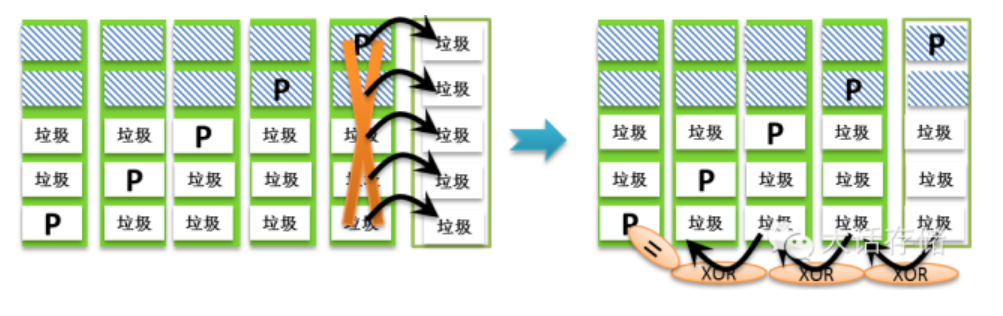
图1-2-3 传统Raid全盘重构
事实上,对这一点不同厂商还真有些不同的处理,比如,如果事先对热备盘上的数据全部清零,也就是真的全写入0x00,你会发现,任何数据与0做XOR,结果还是之前的数据,比如D1 xor = D1,再回来看上图,下面那些垃圾块,与0做xor之后,产生的Parity与原来的Parity相同,那么就没必要重构这些垃圾块。但是有些厂商不预先对热备盘做清零预处理,而在坏盘之后直接全盘重构,那就只能证明这些厂商懒。然而Raid2.0模式下,条带获得了自由,那就意味着只要一个条带的所有D块做xor之后等于它的P块,这个条带就是一致的,其他的垃圾数据根本不用考虑是否一致,也就根本不需要重构。好,首先保证不重构垃圾数据,这在一定程度上加快了重构速度。
其实条带“浮动”之后还没结束,条带还可以“漫游”,“条带漫游”也就意味着,一个条带,可以肆无忌惮的存在于存储空间的任何位置,自己的形状可以是直的、弯的、圆的、尖的。当然一开始没人希望自己奇形怪状,之所以变成这样是因为发生了山河改观的重构,下文会详细描述。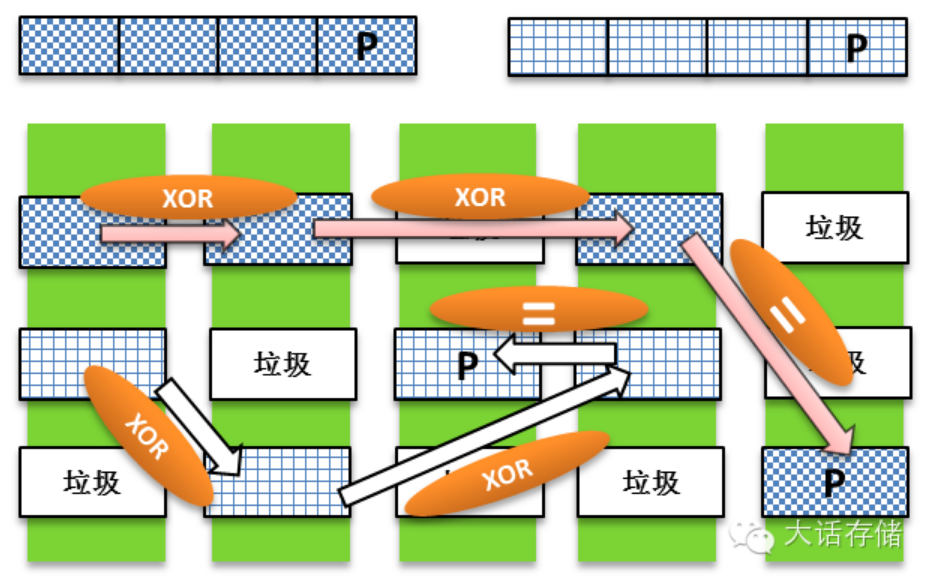
图1-2-4 Raid2.0条带漫游
其次,我们发现一个条带的D/P块完全不像传统Raid那样完全按照顺序排排坐在磁盘上的。为何要这样?其实并不是有意为之,事实上,在Raid2.0模式下,Lun逻辑卷与Raid1.0/1.5一样,依然是由n个条带拼接成的逻辑空间,这一点没变,而且Raid2.0模式下,在新建一个逻辑卷时,系统也是尽量把组成这个逻辑卷的条带按照Raid1.0/1.5模式一样,顺序的放在磁盘上。但是当发生坏盘的时候,所有受影响的条带需要被重构并写入到热备盘。且慢,如果在Raid2.0模式下你的脑袋里还有“热备盘”的概念,就输了。热备盘这个概念在Raid5EE技术里是不存在的,没看懂的请翻回去重新看,只有热备空间,或者说热备块的概念。Raid5EE很严格的摆放了H块,也就是跟着P块一起。但是在Raid2.0模式下,热备块在哪呢?明眼人一下子就能看出来,图中所有被标识为“垃圾”的块,都可以作为热备块。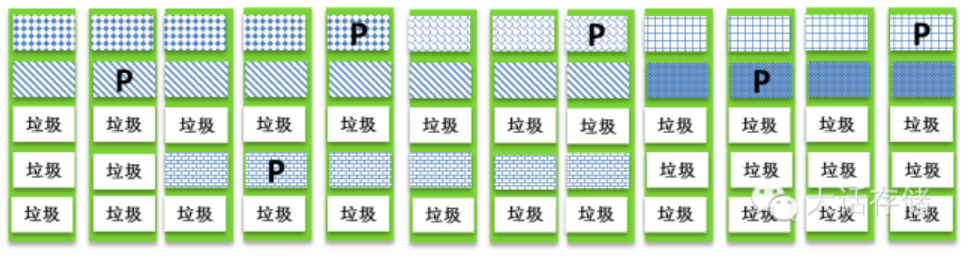
图1-2-5 Raid2.0浮动条带
如图1-2-5所示,一共12块盘,示意性的画了6个条带上去,实际上应该是数不清的条带。可以看到这些条带中,有5D+1P的,有2D+1P的,也有3D+1P的。它们一开始各自都被尽量连续的存放在这12块盘上。但是当其中某块盘坏掉之后,如图1-2-6所示,这块盘上原有的非垃圾数据块需要被重构到热备块中去,此时系统会仅仅读出受影响条带的内容然后计算出待重构块,然后写入到与本条带其他块不共享的任意一块盘上去,也就是说对于单P块保护的条带,算法要保证同一块盘上绝不能够存在同一个条带的2个或者2个以上的块,否则一个单P条带如果同时丢失2个块则该条带对应的逻辑卷数据等效于全部丢失。当然,如果是比如Raid6那种双P条带,则可以允许同一个条带最多2个块放在同一个盘上。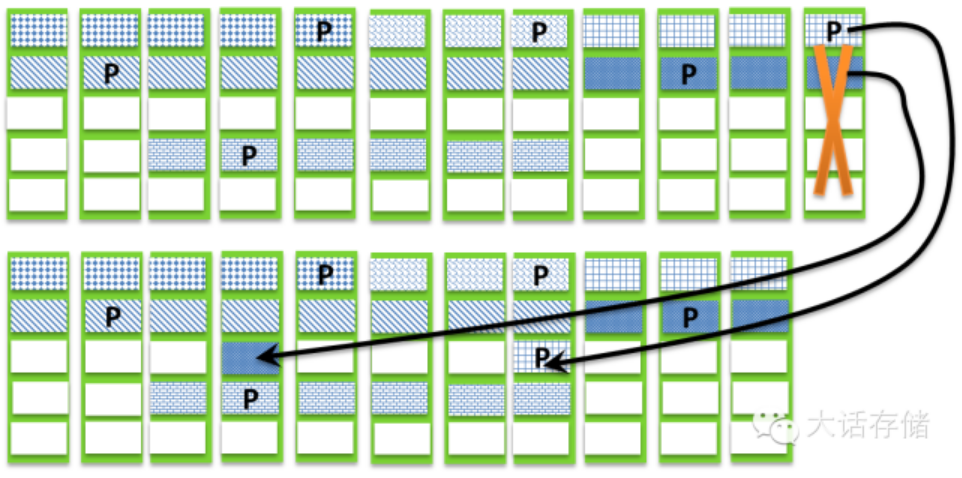
图1-2-6 Raid2.0重构过程
可以看到,Raid2.0属于见缝插针,任何块都可以被重构到任何热备块上去,只要不会产生同一条带内2个以上块位于同一个盘即可。Raid2.0的另一个特性就是,只要系统内还有足够的并且不会导致重构之后出现同一条带2个以上块处在同一个盘的热备块,那么在坏一块盘之后,系统用很少的时间重构完成,此时可以再允许坏一块,再重构完成,再坏一块,直到不能满足上面那两个条件之一为止。这个过程相当于把一个内部全是空洞的膨化物质不断的压紧到它的极限一样。
然而它也有其限制。Raid2.0一个前提是,系统中必须存在充足的可用空间,也就是热备块。如果所有空间都被逻辑卷所占用,此时坏掉一块盘的话,那么就必须向整个阵列中增加至少一块磁盘,如果只增加一块盘,那么所得到的重构速度就和传统Raid无差别了。另一个限制是组成Raid2.0阵列的物理磁盘数,必须远大于其上分布的条带的Segment数,也就是必须远大于xD+yP的数量,比如,如果条带是7D+1P,则你用8块盘组Raid2.0是没意义的,其效果和Raid5E一样,重构完成之后系统不再具备冗余性,因为肯定会出现同一块磁盘上同时分布了同一个条带中的两个Segment的情况。所以,以上这2个限制,对于Raid2.0比较尴尬。
如图1-2-7所示,如果磁盘数量没有远大于xD+yP的数量,这里我们让它们相等,看看是什么结果,首先剩余空间足够,可以重构,但是重构之后会发现必然会出现同一个条带的2个块处于同一屋里盘的情况,所以重构完成之后系统不再具有冗余性。再回头凝视一下图1-2-6,系统依然具有冗余性,还可以再允许坏盘。如果阵列内有x和y各不相同的条带,比如有些条带是3D+1P,有些是15D+1P,而共有16块盘组成Raid2.0阵列,那么此时就得分情况下结论了,对于3D+1P,16远大于4;但是对于15D+1P的条带,16不远大于16,所以此时系统的冗余性对3D+1P的条带们是很好的,但是对15+1P的条带们,只够冗余一次的。这就是“以条带为中心”的视角。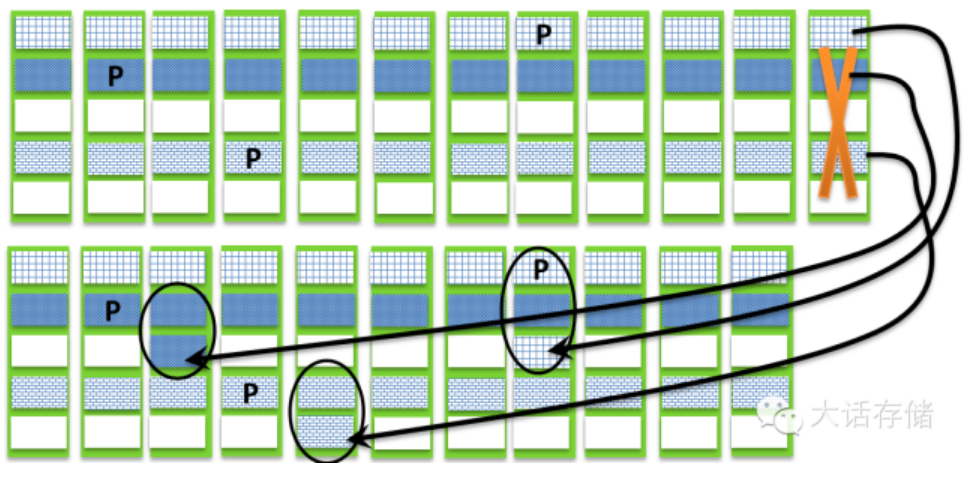
图1-2-7 磁盘数没有远大于xD+yP的结果
我们回过头来看,Raid2.0到底和Raid5EE或者说Raid5EE0有什么本质区别。图1-1-8为Raid5EE阵列重构示意图。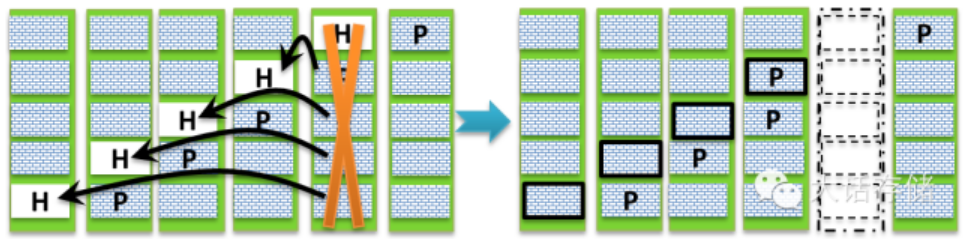
图1-2-8 Raid5EE阵列的重构
如果同样是100块盘,如果被设计做成Raid5EE0的话,由于RaidEE布局方面的固定性,首先要确定到底有多少个H热备块,有多少个,就能允许多少块盘接连发生损坏(必须在上一次重构完成后损坏),必须预先定义好,而且一旦确定就不能更改,这一点就很鸡肋了。其次,还是由于热备空间太过规则的分布,就会导致重构时候不够灵活,比如如果系统需要向某个条带的H块写入恢复之后的数据,但是此时这个盘正在响应其他IO,那么这笔H块就必须等待,而Raid2.0如果遇到这种情况,算法可以随时转向将该恢复的块写入其他符合条件的热备块,这样就避免了等待,使得吞吐量最大化。
Raid2.0 的重构速度完全取决于整个组成Raid2.0阵列的磁盘数以及损坏磁盘上之前的垃圾块比例,盘数越多,垃圾比例越多,重构速度就越快。没有绝对的标准值。
某厂商宣称其Raid5可以支持同时坏2块、3块或者更多的盘。当然,这纯属忽悠,这句话应该加一个前提是:“在Raid2.0模式下有一定几率可以”,把概率性事件忽悠成100%那一定不是工程师干的。如图1-2-6所示,对于左上角的条带,它的确是个单P类似Raid5,也的确如果最左边和最右边两块盘同时坏了,整个数据都没问题,可以重构,但是绝非不是坏任意两块都没问题。
那么逻辑卷是如何分布在Raid2.0之上的呢?如图1-2-10所示,图中只是象征性的画了几个条带或者Segment,实际中会有几百几千几万几十万百万千万个,请理解。从这张图中我们可以得出几个结论:
1. 逻辑卷是由数不清的条带组成的,这些条带可以很规则的连续分布,也可以毫无规则的任意分布。 但是不管怎么分布,都必须要用元数据来将这些零散的条带追踪拼接起来,在逻辑上形成一个地址连续的逻辑空间,也就是逻辑卷,也就是Lun。至于用什么形式的元数据结构,比如是否可以使用单向链表?还是诸如NTFS文件系统下的MFT的类似数据结构?那就是代码架构师要考虑的了。
2. 在一个Raid2.0阵列中可以存在多种条带深度 。但是推荐组成同一个逻辑卷的条带使用相同的条带深度,你要是非设计成允许不同的条带深度也可以,但是一般情况下没什么意义,因为一个逻辑卷应该是各向同性的。但是不排除一些精细化优化的设计能够感知到一个逻辑卷内部的不同差异化IO属性。
3. 在一个Raid2.0阵列中可以存在多种不同xy值组合的xD+yP的条带 。但是推荐组成同一个逻辑卷的条带使用相同的x和y,你要是非设计成允许不同的x和y也可以,但是没什么意义。
4. 整个阵列的存储空间不存在“地盘”的概念,任何逻辑卷都可以把手伸向任何地方。
5. 即便是一个条带里的不同D或者P的Segment也可以散落在各处。 这就意味着需要至少两级链表来描述整个逻辑卷,第一级链表用于把多个Segment拼接成一个条带,第二级链表用来多个条带拼接成一个逻辑卷。图中Lun4的D和P都被散开了,明显是经过了一场天崩地裂的重构,条带自身被分崩离析。而且还能看的出,Lun4里存在同一个单P条带中的2个块存储于同一块盘的情况。这明显可以推断出,Lun4被重构之前,系统的磁盘数量或者剩余空间已经捉襟见肘了,已经找不到那些能够保持重构之后冗余性的空间了,不得不牺牲冗余性。人的智慧是无限的,这里其实可以有一个办法来缓解这个问题,从而很大几率上恢复冗余性。如图1-2-9所示,当出现了同一个单校验条带中多于两个Segment不得不被摆放到同一块磁盘上的时候,为了恢复冗余性,可以将Segment做合并,从而压缩条带中Segment的数量,比如图示即把一个6D+1P的条带,变为了3D+1P,其后果是校验块P的容量加倍了,浪费了空间,但是同时系统却恢复了冗余性。观察一下不难发现,要实现这种优化,要求xD+yP条带中的x必须为偶数,否则将无法合并。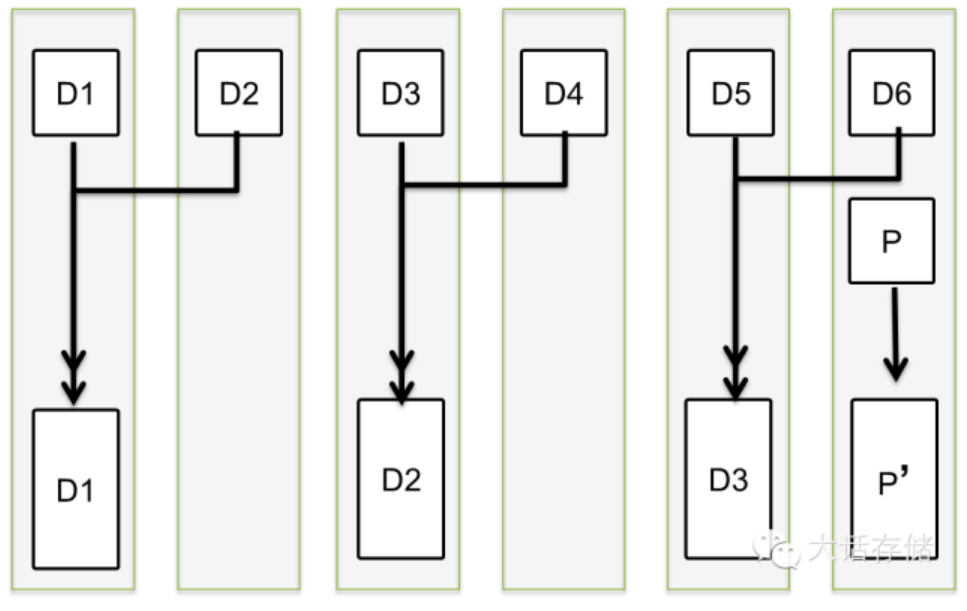
图1-2-9 牺牲很小的空间来恢复冗余性
6. 可以推断出这个阵列经过了一次扩容。 因为可以看Lun3和Lun4在阵列左侧的条带分布明显密度高于右侧,证明右侧的一部分盘是后来添加到阵列当中的。
7. 可以推断出Lun4是重构完之后尚未自动均衡的,Lun3是经过重构之后又经过了自动均衡的。而Lun1和Lun2很可能是新创建的。 Lun3 明显可以看出左侧稍微密度高一些,右侧密度低一些;而Lun4在右侧基本没有分布。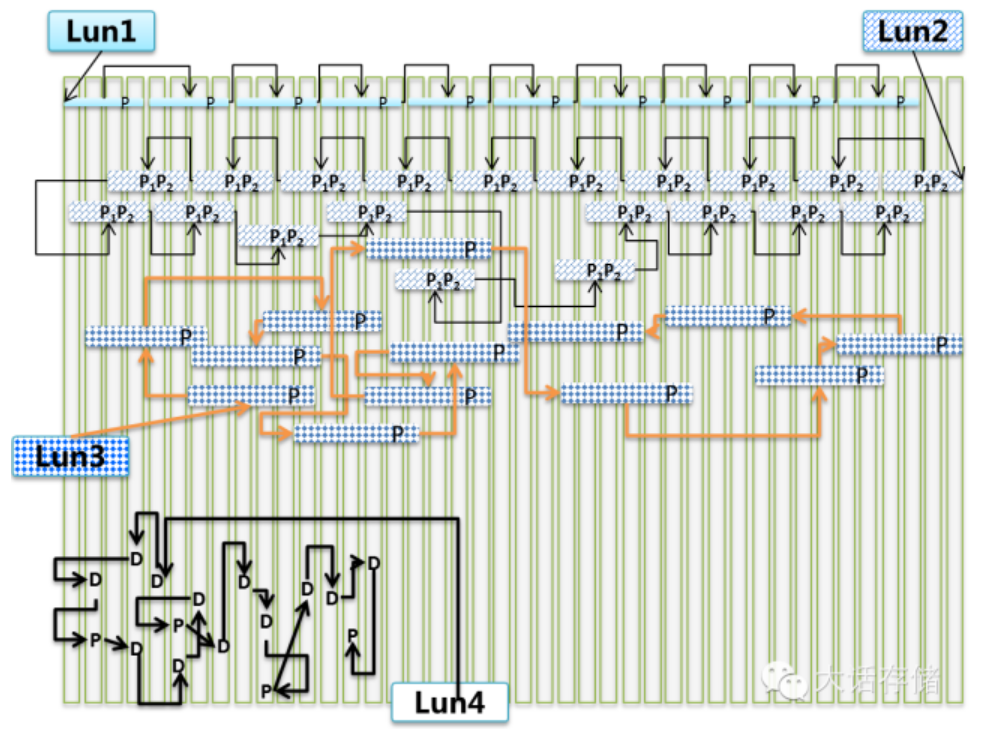
图1-2-10 逻辑卷在Raid2.0之上的分布
如果你从此奉Raid2.0为神那你就输了。由于一个条带中的Segment块可以被放置在任意磁盘的任意地点,那么就一定要用元数据比如链表来追踪每个块的实际物理地址。没有免费的午餐,自由是需要付出代价的,这体现在管理层需要管理的东西变多了。Raid2.0的条带碎片是其致命缺点。太过灵活所要付出的代价就是,映射关系不可能再像传统Raid那样通过套用某函数公式就可以简单的得出物理地址了,而必须查表,查大表,查特大表,查超级大表!大到什么程度?大到以至于无法全部缓存到内存中,必须像传统文件系统一样,现用现缓存,产生Page Fault然后Page In。每一笔IO都必须查表,可以这么说,原来每个IO在地址映射流程中耗费100个时钟周期,现在则需要耗费一万个时钟周期,就这种量级,也就是说徒增了百倍以上的计算量;另外,比如一个由300个4TB盘组成的Raid2.0阵列,每个Segment按照1MB来算,每个Segment均需要至少记录其逻辑地址和物理地址,如果是32bit地址,那么至少8字节,再加上2字节的其他属性,每个表项占10字节空间,那么300×4×1024×1024=1258291200个表项,乘以10字节后≈11GB的元数据表,由于存储系统的RAM主要用于读写缓存,把11GB的元数据放进去会导致读写缓存空间减少,影响性能,所以元数据不能全部缓存到内存里,这势必导致IO性能进一步下降。
但是请注意一点,既然Raid2.0导致平时IO性能下降,那谁还用它?其实这里说的“下降”是指相对下降了,还是那句话,如果能够用硬件速度的提升来弥补,那么就是可以接受的,比如增加了100倍计算量,你可要知道,存储系统里的CPU平时基本是睡大觉的,数据拷贝有DMA,除了iSCSI这种严重依赖内核里TCPIP模块进行数据收发的场景,FC、SAS通道对CPU耗费是很低的,所以计算量并不是多么严重的事情,加之CPU厂商不断提升规格,他们看到越来越多的软件不思进取越来越依赖硬件规格,心里肯定也是暗爽。其次,元数据量上来了,现在RAM也很便宜,截至文字落笔时,单条128GB的DDR RAM已经出现,所以元数据容量问题也不算个大事。
谁是大事?可靠性才是最大的事。庞大的元数据量,加上大量逻辑卷大范围的不加隔离的分布到阵列中所有磁盘,这让Raid2.0时刻处于高危状态中。由于不具备像Raid1.0那样得隔离性,一旦整个阵列元数据不一致或者出现问题,影响范围巨大,几乎所有逻辑卷均会出现数据不一致。这一点想想文件系统就可以了,非正常关机导致文件系统损坏的几率是很大的。何况对于一个管理着数千块磁盘的系统。就算是有电池保护RAM,也不能保证100%可靠。不用说别人了,就算我这种基本早已不碰设备的人,也遇到过多次主机或者阵列宕机之后的数据不一致现象(阵列都有电池保护RAM),不是卷挂不起来,就是应用启动时报错。所以越复杂的东西一定越不可靠,这是一定的。一块石头可以存在几亿年,但是一个生物很快要么病死要么老死,就是这个道理,即便是免疫系统进化的再百毒不侵,也可能随时被一砖撂倒。现在想想存储系统里搞得那么复杂,什么都是两份,还有心跳线,心跳都是冗余的,结果很多时候出的问题,就出在这些为了提高可靠性而设计的东西上,这很讽刺。为了隔离故障域,有些厂商不得不做出让步,也就是限制Raid2.0单阵列的磁盘数,这很尴尬。
另外一个大事,就是数据布局的打乱。原本连续存放的逻辑数据块,物理上却可以被凌乱的存放,在没重构之前,数据逻辑和物理是可以大范围一一对应连续存放的,但是每发生一次重构,就会乱一次,发生多次重构那就是乱上加乱,乱的平方更乱,这直接导致大块逻辑连续地址IO到了底层就会变为小块物理随机IO,性能惨不忍睹。 靠什么解决?靠使劲往里加盘,如果你只有10块盘,趁早别用Raid2.0,因为会死的很惨,但是当加到300块、500块盘的时候,盘数的增多会弥补性能的相对下降,绝对数值,相比10块盘的时候,必然也必须是提升的,当然,再怎么提升,也会比把这300/500块盘做成Raid50要低得多,所以性能是相对下降的。
好,Raid2.0彻底解决了重构速度慢的问题,然后又用高速CPU和大内存以及大数量的磁盘来掩盖其性能相对下降的事实,成功的在历史舞台上扮演了其角色,当然,我们不知道它能存活多久,按照现在硬件的发展速度,下一个形态轮回估计很快就会到来。
我曾经在博客里写过一些文字,其中一句话现在看来依然有所回味:“当卷从树上下来直立行走的时候,却发现文件系统早就进化成人了”。君不见,Raid2.0下的磁盘之上,千疮百孔,逻辑卷凌乱的分布着,那张大表在天空中弥漫着,仿佛是上帝的大手,没有了这张表,一切俱焚!Raid2.0如此灵活,已经接近传统的文件系统的思想了,如果把逻辑卷看做文件的话。有些人不知道,其实有些Raid2.0模式的多控SAN存储系统,其内部设计基本就是和开源的分布式系统类似了,而且还是非对称模式的了,也就是有专门的节点负责管理元数据,因为如果设计为对称式的,则扩大了广播域,扩展性很差;而如果将元数据集中存放在一个或者几个冗余节点,可以比较容易的实现更多节点扩展。
其实还有个隐情,ZFS文件系统底层使用的RaidZ,其实就是一种浮动条带的设计,所以Raid2.0相当于Raid5EE和RaidZ思想的结合。另外,NetApp WAFL文件系统也可以说是一种对逻辑卷的浮动,但是很遗憾它并不是Raid2.0,因为WAFL并没有搀和到Raid层,WAFL底层的Raid属于Raid40,条带并没有浮动起来,所以享受不到重构提速,然而其Lun的确是从文件虚拟出来的。
各个已经实现了Raid2.0的厂商对诸如“条带”“Segment”等概念的命名都不一样,比如有的人就叫Segment为“Block”,有的叫条带为“Chunk”,有的则叫“Slice”,有的叫“Cell”。当读者在阅读这些厂商的材料的时候,只要牢记Raid2.0的本质,这些概念,都是浮云。如果让我来包装概念的话,我会选择使用“Float Stripe”,浮动条带,因为既保持了条带这个传统概念,容易让人理解,同时又将其动态化展现,相比什么“Chunk”之类强太多,更能吸引眼球,当然,这也是一个彻底理解、思考之后的升华和创新过程。
三句话总结:Raid1.0就是几块或者十几块盘做Raid组然后分逻辑卷;Raid1.5就是利用Raid50或者Raid60技术在为数更多的盘上划分逻辑卷;Raid2.0就是将条带浮动于物理盘之上用类似文件系统的思想去管理逻辑空间。
总结一下Raid2.0相对于Raid1.0/1.5的优点和缺点:
优点:
1. 快速重构,不重构垃圾块,所有磁盘并发写入,盘数越多重构越快。
2. 阵列扩容缩容方便,扩容后自动均衡, 缩容前自动重分布。
3. 逻辑卷IO性能高,大范围跨越物理磁盘。
4. 灵活的配置,包括条带深度、x和y的值。
缺点:
1. 元数据庞大,布局凌乱,相对性能下降。
2. 盘数必须足够多,而且远大于xD+yP数才有意义。
不具备隔离性,一旦整个阵列元数据不一致或者出现问题,影响范围巨大,所有逻辑卷均不一致。
————————————————
转自:https://blog.csdn.net/TV8MbnO2Y2RfU/article/details/78103844