作业要求:https://edu.cnblogs.com/campus/nenu/2016CS/homework/2139
git地址:https://git.coding.net/pipifan/wfAnalysis.git
一、第一次分析
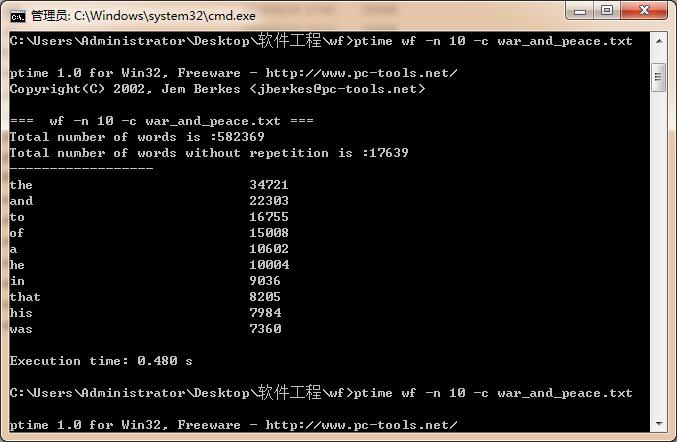
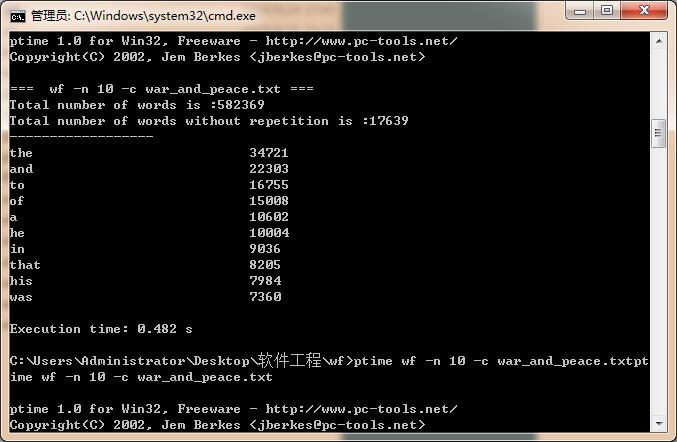
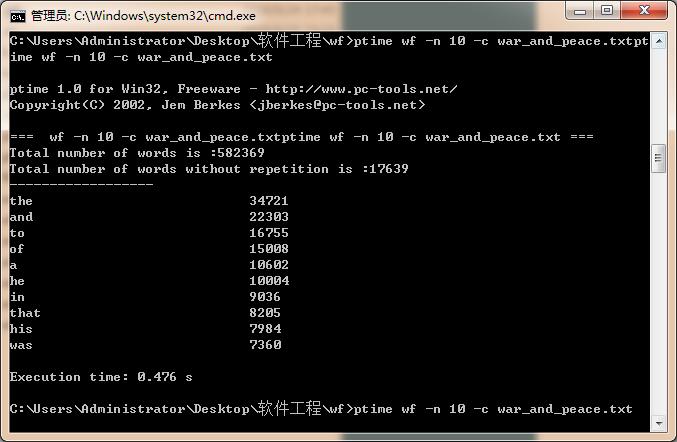
|
次数 |
消耗时间/s |
|
第一次 |
0.480 |
|
第二次 |
0.482 |
|
第三次 |
0.476 |
|
平均 |
0.476 |
二、猜测存在的瓶颈
猜测一:遍历字符串的每一行时,存储字符串出现多少次的unordered_map比较费时间
while (getline(file, str)) { for(auto ch : str) { if( ch >= 'A' && ch <= 'Z' ) ch = (char)( ch + 32 ); if (ch >= '0' && ch <= '9' || ch >= 'a' && ch <= 'z') { tmp += ch; continue; } if (!tmp.empty()) { if (tmp[0] >= 'a' && tmp[0] <= 'z') { tot++; mp[tmp]++; if( !limit ){ if (!id.count(tmp)) id[tmp] = cnt++; } } tmp = ""; } } if (!tmp.empty()) { if (tmp[0] >= 'a' && tmp[0] <= 'z'){ tot++; mp[tmp]++; if (!id.count(tmp)) id[tmp] = cnt++; } tmp = ""; } }
猜测二:对所有的pair<字符串,字符串出现个数>排序比较费时,时间复杂度为O(nlogn)
vector<psl> vec(mp.begin(), mp.end());
sort(vec.begin(), vec.end(), cmp());
三、Profile分析

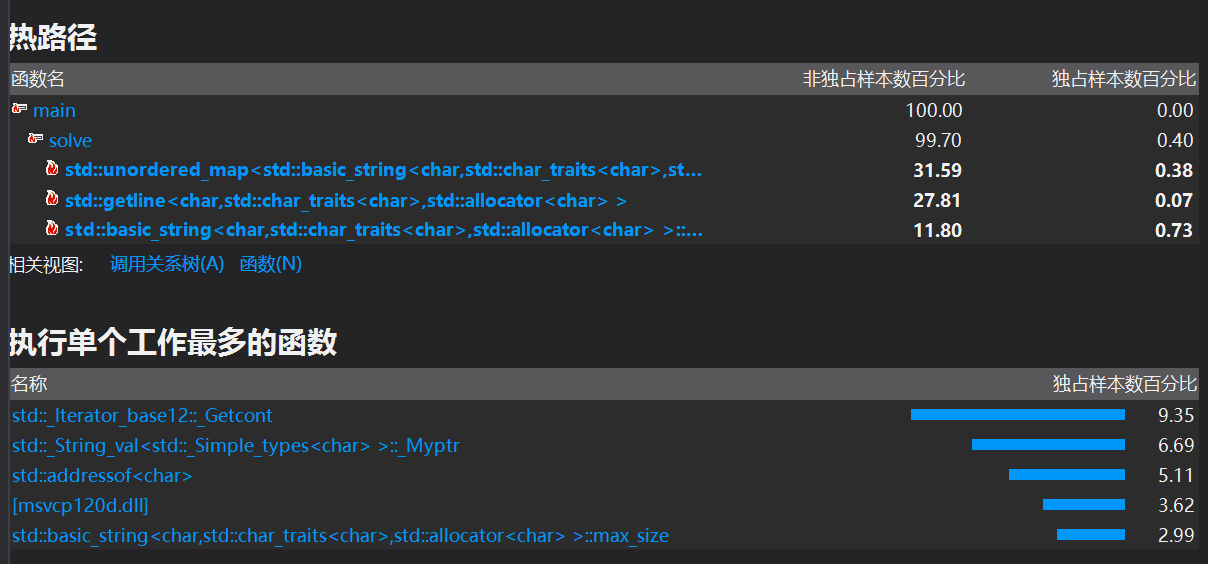

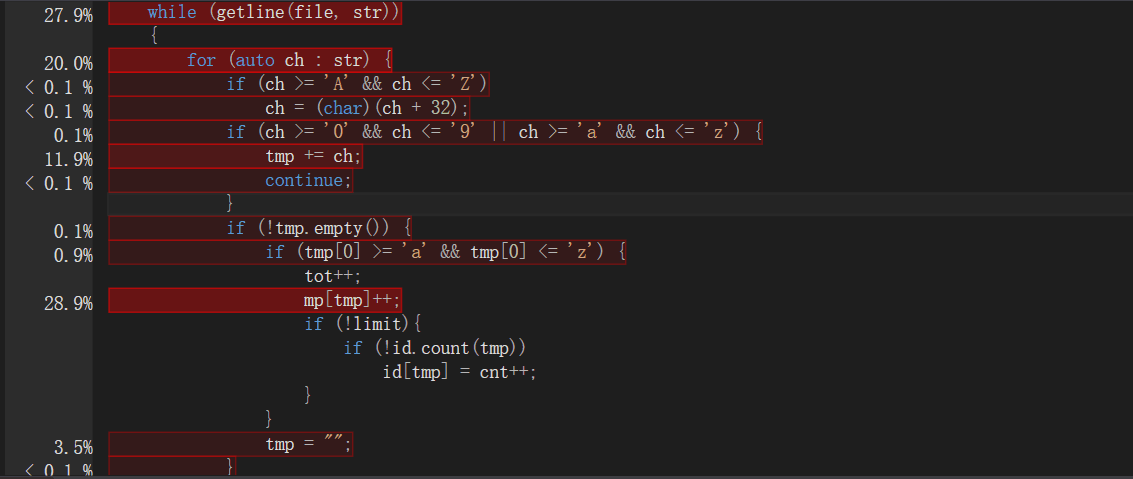
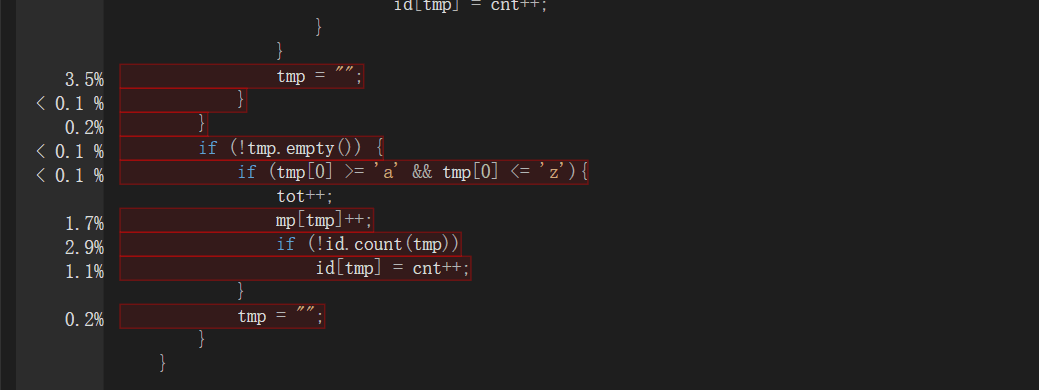
由图分析,最耗时的为遍历字符串,getline函数读入文件所有字符串和unordered_map
四、程序改进
我认为我在文件的读入上可以在优化一下,从原本的对每一行用getline函数再依次遍历,优化为用C语言的fread函数一次性读入,再从头遍历到尾,不好的就是,我多声明了一个全局变量。

int fread_analyse(const char *file_name ) { freopen(file_name,"rb",stdin); int len = fread(buf,1,maxn,stdin); buf[len] = '�'; return len; }
五、第二次分析
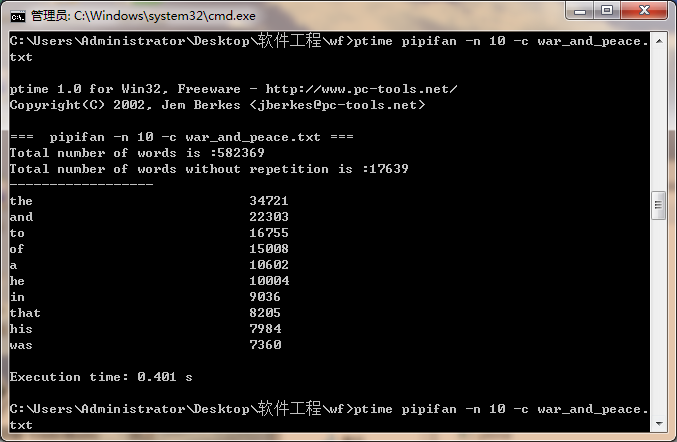
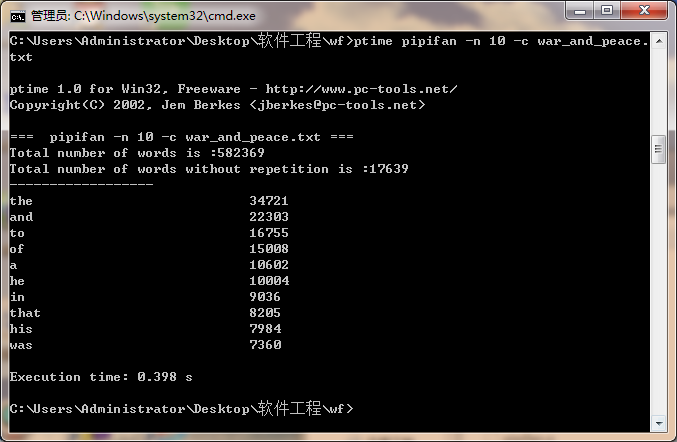
|
次数 |
消耗时间/s |
|
第一次 |
0.401 |
|
第二次 |
0.397 |
|
第三次 |
0.398 |
|
平均 |
0.399 |
六、总结
写代码真辛苦