Overview
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Kinesis, or TCP sockets, and can be processed using complex algorithms expressed with high-level functions like map, reduce, join and window. Finally, processed data can be pushed out to filesystems, databases, and live dashboards. In fact, you can apply Spark’s machine learning and graph processing algorithms on data streams.
apply:申请,应用,运用

Internally, it works as follows. Spark Streaming receives live input data streams and divides the data into batches, which are then processed by the Spark engine to generate the final stream of results in batches.

Spark Streaming provides a high-level abstraction called discretized stream or DStream, which represents a continuous stream of data. DStreams can be created either from input data streams from sources such as Kafka, Flume, and Kinesis, or by applying high-level operations on other DStreams. Internally, a DStream is represented as a sequence of RDDs.
discretize /dɪ'skriːtaɪz/ 离散化
discretized stream or DStream
entry 入口 进入 条目
frequency 频繁 频率
和Spark 基于RDD 的概念很相似,Spark Streaming 使用离散化流(discretized stream)作为抽象表示,叫作DStream。DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为RDD 存在,而DStream 是由这些RDD 所组成的序列。DStream 可以从各种输入源创建,比如Flume、Kafka 或者HDFS。创建出来的DStream 支持两种操作,一种是转化操作(transformation),会生成一个新的DStream,另一种是输出操作(output operation),可以把数据写入外部系统中。和批处理程序不同,Spark Streaming 应用需要进行额外配置来保证24/7 不间断工作。
从创建StreamingContext 开始,它是流计算功能的主要入口。StreamingContext 会在底层创建出SparkContext,用来处理数据。
Note that when these lines are executed, Spark Streaming only sets up the computation it will perform when it is started, and no real processing has started yet. To start the processing after all the transformations have been setup, we finally call
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate首先打开一个终端
[root@host ~]# nc -lp 9999
ni ni hao ni haon^H n
hello hello haa^H you are pig
在另一个终端打开spark-shell
scala> import org.apache.spark.streaming._
import org.apache.spark.streaming._
scala> import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.StreamingContext._
scala> import org.apache.spark.api.java.function._
import org.apache.spark.api.java.function._
scala> import org.apache.spark.streaming._
import org.apache.spark.streaming._
scala> import org.apache.spark.streaming.api._
import org.apache.spark.streaming.api._
scala> val ssc = new StreamingContext(sc, Seconds(10)) // 从sc创建StreamingContext并指定10秒钟的批处理大小;批次间隔(batch interval)为10s
ssc: org.apache.spark.streaming.StreamingContext = org.apache.spark.streaming.StreamingContext@2329d041
scala> val lines = ssc.socketTextStream("localhost", 9999)//连接到本地机器9999端口上后,使用收到的数据创建DStream
lines: org.apache.spark.streaming.dstream.ReceiverInputDStream[String] = org.apache.spark.streaming.dstream.SocketInputDStream@5ecd3f34
scala> val words = lines.flatMap(_.split(" ")) //对DStream进行扁平化处理
words: org.apache.spark.streaming.dstream.DStream[String] = org.apache.spark.streaming.dstream.FlatMappedDStream@39906398
scala> val pairs = words.map(word => (word, 1))//将words转换为Map
pairs: org.apache.spark.streaming.dstream.DStream[(String, Int)] = org.apache.spark.streaming.dstream.MappedDStream@1e2ab369
scala> val wordCounts = pairs.reduceByKey(_ + _)
wordCounts: org.apache.spark.streaming.dstream.DStream[(String, Int)] = org.apache.spark.streaming.dstream.ShuffledDStream@524a63e0
scala> wordCounts.print()
//要开始接收数据,必须显式调用StreamingContext 的start() 方法。这样,Spark Streaming 就会开始把Spark 作业不断交给下面的SparkContext 去调度执行。
//执行会在另一个线程中进行,所以需要调用awaitTermination 来等待流计算完成,来防止应用退出
scala> ssc.start();ssc.awaitTermination();
-------------------------------------------
Time: 1514531730000 ms
-------------------------------------------
(hao,1)
(n,1)
(hao,1)
(ni,3)
-------------------------------------------
Time: 1514531770000 ms
-------------------------------------------
(are,1)
(ha,1)
(hello,2)
(pig,1)
(you,1)
请注意,一个Streaming context 只能启动一次,所以只有在配置好所有DStream 以及所需要的输出操作之后才能启动。
Spark Streaming 使用“微批次”的架构,把流式计算当作一系列连续的小规模批处理来对待。Spark Streaming 从各种输入源中读取数据,并把数据分组为小的批次。新的批次按均匀的时间间隔创建出来。在每个时间区间开始的时候,一个新的批次就创建出来,在该区间内收到的数据都会被添加到这个批次中。在时间区间结束时,批次停止增长。时间区间的大小是由批次间隔这个参数决定的。批次间隔一般设在500 毫秒到几秒之间,由应用开发者配置。每个输入批次都形成一个RDD,以Spark 作业的方式处理并生成其他的RDD。处理的结果可以以批处理的方式传给外部系统.
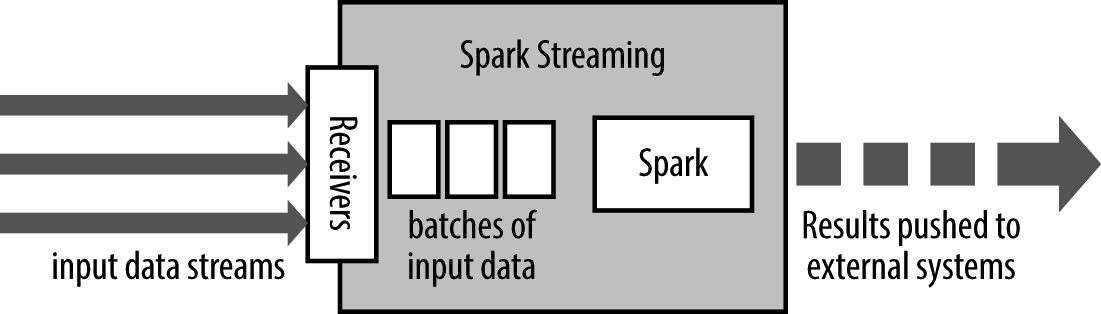
Spark Streaming 的编程抽象是离散化流,也就是DStream,它是一个RDD 序列,每个RDD 代表数据流中一个时间片内的数据。

DStream 是一个持续的RDD 序列,你可以从外部输入源创建DStream,也可以对其他DStream 应用进行转化操作得到新的DStream。
Stream 还有“有状态”的转化操作,可以用来聚合不同时间片内的数据。
Spark Streaming 在Spark 的驱动器程序—工作节点的结构的执行过程如下:

Spark Streaming 为每个输入源启动对应的接收器。接收器以任务的形式运行在应用的执行器进程中,从输入源收集数据并保存为RDD。它们收集到输入数据后会把数据复制到另一个执行器进程来保障容错性(默认行为)。数据保存在执行器进程的内存中,和缓存RDD 的方式一样1。驱动器程序中的StreamingContext 会周期性地运行Spark 作业来处理这些数据,把数据与之前时间区间中的RDD 进行整合。
Spark Streaming 对DStream 提供的容错性与Spark 为RDD 所提供的容错性一致:只要输入数据还在,它就可以使用RDD 谱系重算出任意状态(比如重新执行处理输入数据的操作)。默认情况下,收到的数据分别存在于两个节点上,这样Spark 可以容忍一个工作节点的故障。不过,如果只用谱系图来恢复的话,重算有可能会花很长时间,因为需要处理从程序启动以来的所有数据。因此,Spark Streaming 也提供了检查点机制,可以把状态阶段性地存储到可靠文件系统中(例如HDFS 或者S3)。一般来说,你需要每处理5-10 个批次的数据就保存一次。在恢复数据时,Spark Streaming 只需要回溯到上一个检查点即可。
转化操作
DStream 的转化操作可以分为无状态(stateless)和有状态(stateful)两种。
a.在无状态转化操作中,每个批次的处理不依赖于之前批次的数据。
b.有状态转化操作需要使用之前批次的数据或者是中间结果来计算当前批次的数据。有状态转化操作包括基于滑动窗口的转化操作和追踪状态变化的转化操作。
无状态转化操作就是把简单的RDD 转化操作应用到每个批次上,也就是转化DStream中的每一个RDD。
尽管这些函数看起来像作用在整个流上一样,但事实上每个DStream 在内部是由许多RDD(批次)组成,且无状态转化操作是分别应用到每个RDD 上的。
无状态转化操作也能在多个DStream 间整合数据,不过也是在各个时间区间内
在Scala 中连接两个DStream:
val ipBytesDStream =accessLogsDStream.map(entry => (entry.getIpAddress(), entry.getContentSize()))
val ipBytesSumDStream =ipBytesDStream.reduceByKey((x, y) => x + y)
val ipBytesRequestCountDStream =ipCountsDStream.join(ipBytesSumDStream)
我们还可以像在常规的Spark 中一样使用DStream 的union() 操作将它和另一个DStream的内容合并起来,也可以使用StreamingContext.union() 来合并多个流。最后,如果这些无状态转化操作不够用,DStream 还提供了一个叫作transform() 的高级操作符,可以让你直接操作其内部的RDD。这个transform() 操作允许你对DStream 提供任意一个RDD 到RDD 的函数。这个函数会在数据流中的每个批次中被调用,生成一个新的流。transform() 的一个常见应用就是重用你为RDD 写的批处理代码。
有状态转化操作
DStream 的有状态转化操作是跨时间区间跟踪数据的操作;也就是说,一些先前批次的数据也被用来在新的批次中计算结果。主要的两种类型是滑动窗口和updateStateByKey(),前者以一个时间阶段为滑动窗口进行操作,后者则用来跟踪每个键的状态变化.
有状态转化操作需要在你的StreamingContext 中打开检查点机制来确保容错性。
基于窗口的转化操作
基于窗口的操作会在一个比StreamingContext 的批次间隔更长的时间范围内,通过整合多个批次的结果,计算出整个窗口的结果。
所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长,两者都必须是StreamContext 的批次间隔的整数倍。窗口时长控制每次计算最近的多少个批次的数据,其实就是最近的windowDuration/batchInterval 个批次。如果有一个以10 秒为批次间隔的源DStream,要创建一个最近30 秒的时间窗口(即最近3 个批次),就应当把windowDuration设为30 秒。而滑动步长的默认值与批次间隔相等,用来控制对新的DStream 进行计算的间隔。如果源DStream 批次间隔为10 秒,并且我们只希望每两个批次计算一次窗口结果,就应该把滑动步长设置为20 秒。
对DStream 可以用的最简单窗口操作是window(),它返回一个新的DStream 来表示所请求的窗口操作的结果数据。换句话说,window() 生成的DStream 中的每个RDD 会包含多个批次中的数据,可以对这些数据进行count()、transform() 等操作
如何在Scala 中使用window() 对窗口进行计数:
val accessLogsWindow = accessLogsDStream.window(Seconds(30), Seconds(10))
val windowCounts = accessLogsWindow.count()
Scala 版本的每个IP 地址的访问量计数:
val ipDStream = accessLogsDStream.map(logEntry => (logEntry.getIpAddress(), 1))
val ipCountDStream = ipDStream.reduceByKeyAndWindow(
{(x, y) => x + y}, // 加上新进入窗口的批次中的元素
{(x, y) => x - y}, // 移除离开窗口的老批次中的元素
Seconds(30), // 窗口时长
Seconds(10)) // 滑动步长
Scala 中的窗口计数操作:
val ipDStream = accessLogsDStream.map{entry => entry.getIpAddress()}
val ipAddressRequestCount = ipDStream.countByValueAndWindow(Seconds(30), Seconds(10))
val requestCount = accessLogsDStream.countByWindow(Seconds(30), Seconds(10))
UpdateStateByKey转化操作:
有时,我们需要在DStream 中跨批次维护状态