原文:(PDF) 。
摘要 一等(first-class)函数是一种非常强大的语言结构,并且是函数式语言的基础特性。少数过程式语言由于其基于栈的实现,也支持一等函数。本文讨论了Lua 5.x用于实现一等函数的新算法。与之前所使用的技术不同,该算法不需要对源代码做静态分析(一种会极大降低Lua代码生成器即时性的技术)并且可支持使用顺序栈存储常规局部变量。
1 介绍
一等函数是函数式语言的标志性特征,在过程式语言中也是很实用的概念。很多过程式函数如果以高阶函数的形式编写则会增加可读性。例如,C语言标准库中的排序函数(qsort)需要一个比较函数,这个函数是以函数指针的形式作为参数传入qsort的。回调函数是另一个体现一等函数对于过程式语言的实用性的例子。此外,对一等函数的支持也使开发者能够在过程式语言中使用函数式编程技术。
面向对象特性可以部分满足对高阶函数的需要,因为一等对象也携带了函数(方法)。然而,当开发者只需要一个单独的函数时,使用类就会显得过于累赘,因此面向对象语言也提供了其他机制以支持高阶函数,例如Java中的匿名内部类[AGH05]、C#中的代理和匿名方法[ISO06]。
Lua [IdFC96, Ier03]是一种过程式脚本语言,被广泛应用于游戏中,这些游戏大量应用了一等函数。它的标准库中包含了一些高阶函数,例如:sort函数需要一个比较函数作为参数;gsub函数对字符串做模式匹配和替换,它可接受一个替换函数作为参数,替换函数接受匹配了模式的原字符串并返回它的替换字符串。标准库也提供了遍历函数,它接受一个函数,并对集合中的每个元素调用这个函数(命令式版本的map)。
Lua和Scheme一样,所有函数都是匿名的,并且在运行时动态创建。Lua提供了创建函数的传统写法,示例如下:
function fact(n) if n <= 1 then return 1 else return n * fact(n - 1) end end
实际上,上述代码中创建函数的写法只是将一个匿名函数赋值给一个常规变量的语法糖:
fact = function (n) ... end
Lua解释器的内核也包括一等函数([IdFC07]中描述了该特性的演化)。大部分解释型语言提供了求值(eval)函数,用于执行任意表示为数据的代码片段。与这些语言不同,Lua提供了编译(compile)函数loadstring,它返回与传入的代码片段一致的匿名函数。当然,eval和compile是等价的,他们中的任意一个都能用于实现另一个。但是我们认为compile更好,因为它没有副作用,并且它分离了数据到代码的转换和代码的实际执行。
Lua通过闭包[Lan64, Car84]支持使用词法作用域的一等函数。由于简单性是Lua的目标之一,任何可接受的闭包实现都必须满足以下要求:
- 对不使用非局部变量的程序的执行效率不会造成影响;
-
命令式程序的执行效率必须可接受。在命令式程序中副作用(例如赋值)是常态;
-
必须与过程式语言的标准执行模型相兼容,在这个模型中变量是保存在从顺序栈中分配的活动记录中的;
-
必须能够应用在一遍式编译器中。一遍式编译器即时生成代码,而不会生成中间表示。
前两条要求适用于一部分命令式语言,在这些命令式语言中,高阶函数可能很重要,但大部分程序的核心都不包含它。第三条要求大体上适用于命令式语言,但由于Lua简单的编译器,这个要求在Lua中更严格。最后一条要求是针对Lua的,下面将进行说明。
Lua的实现相当简洁。解释器、编译器和标准库总共不超过17000行C代码。Lua经常被应用于内存受限的设备上,如乐高Mindstorms NXT(256K闪存和64K RAM)。此外,Lua经常被应用于数据表示。表示数据的Lua程序可能包含庞大的表达式,这些表达式会占用数千行代码。所有这些应用都要求编译器必须小而快。
整个Lua编译器(包括词法分析器、语法分析器和代码生成器)不超过3000行代码。Lua 5.1的编译速度是Perl 5.8的四倍、gcc 4.2(不优化)的30倍(Python在编译一个包含一百万行代码的函数时使一部具有1.5GB内存的Pentium 4机器崩溃了)。不使用任何中间表示是达到如此高性能的关键,编译器不需要浪费时间在构造和遍历数据结构上。
自从1994年Lua发布第一个版本开始,它就对一等函数提供有限的支持。由于早期版本的实现技术不满足前述的4个要求,早期版本并不支持严格(proper)词法作用域。1998年,Lua 3.1提出了upvalue的概念,它允许内层函数访问外部变量的值而不是变量本身[IdFc07]。2003年,Lua 5.0使用了一种新的实现,提供了对使用严格词法作用域的一等函数的完全支持。但在[IdFC05]中,对新的闭包实现的说明只有一段简短的介绍。本文将对Lua闭包的实现提供详尽的阐述。
下一节将讨论一些使用词法作用域的一等函数的实现技术;第3节描述了Lua的实现;第4节使用分析法和一些基准测试对这些实现进行了评估;最后,第5节将进行总结。
2 其他语言中的闭包
本节将讨论当前实现使用词法作用域的一等函数和其他语言中类似机制的技术。首先讨论函数式语言中的实现,再讨论命令式语言的实现。
所有函数式语言都对使用词法作用域的一等函数提供了充分的支持,毕竟一个函数只有支持了这个特性才能称为“函数式”。而命令式语言通常不支持或部分支持闭包。
函数式语言中的闭包
如何高效实现使用词法作用域的一等函数长期以来都是函数式语言所关心的问题,对这个问题进行了长期投入并且收效显著。我们不会对所有实现进行详尽的说明,而只对其中一些实现进行简要的介绍,特别是Scheme的实现,因为Scheme和Lua的语义相似。
由于Landin开创性的工作[Lan64],闭包被作为具有严格语义的语言中一等函数的常规实现。闭包是表示一个函数和执行该函数所需要的环境的数据结构。但在第一个闭包模型中,闭包保存了整个它被创建时的环境,并且闭包是使用链表表示的,导致这个模型的时间和空间效率都较低。
Rabbit [Ste78]是第一个严格的Scheme编译器,它在闭包创建的问题上下足了功夫:“在决定环境从栈分配或从堆分配的问题上进行了大量分析。”[Ste78, p. 60]。Rabbit编译器将函数(Scheme术语称为λ表达式)分为三种情况:第一种情况下函数的所有调用点(function-call position)和函数定义的位置处于同一个环境,在这种情况下函数不需要闭包,并且可在与调用者的环境相同的环境下执行;第二种情况下函数的调用点在其他函数内部,在这种情况下编译器创建“部分闭包”;最后一种是当函数“逃离”时,即函数作为参数或返回值,在这种情况下,编译器创建完全闭包。
Cardelli [Car84]提出了扁平闭包(flat closure)的概念。与传统闭包不同,扁平闭包只保存它所需要的环境中的变量的引用,而不是保存整个环境的引用。扁平闭包与“safe-for-space complexity”规则兼容,即“在某个局部变量的作用域内最后一次使用该变量后该变量的绑定就不能被访问”[SA00]。但由于从一个闭包到另一个闭包的变量有多余的拷贝,扁平闭包的效率较低[SA00]。
Shao和Appel [SA94, SA00]使用了大量控制流和数据流分析对每个闭包选择最好的闭包表示方法(他们称为“闭包转换”(closure conversion))。他们的表示方法支持闭包共享,因此能在保证safe-for-space complexity的同时减少拷贝。
不幸的是,大部分函数式语言中的闭包实现都不能轻易地被移植到过程式语言中,特别是Lua语言。主要的限制是他们把非局部变量作为只读的(我们在Lua 3.1中也限制upvalue为只读的)。在ML中,可赋值的单元(cell)没有名字,因此非局部变量是天然只读的。在Scheme中,大部分实现会做赋值转换(assignment conversion)[Ste78, AKK+86],即将可赋值的变量实现为ML单元。这在函数式语言中是聪明的决定,因为赋值在函数式语言中很少见,但不适用于过程式语言,因为赋值在过程式语言中是常态。此外,赋值转换需要进行源代码分析,而Lua编译器无法进行这种分析,原因在之前已经说明。
过程式语言
以往传统的过程式语言通过限制将函数作为值使用或限制访问外部变量以避免闭包的使用:
-
C不提供嵌套函数,因此一个函数不能访问另一个函数中的局部变量;
-
Pascal提供嵌套函数,但限制了嵌套函数的使用:函数能被作为参数传递给另外一个函数,但不能被返回,也不能保存在变量中,因此函数不能“逃离”创建它的函数;
-
Modula提供了嵌套函数和一等函数,但这两个特性不是同时具备的。只有在顶层定义的函数才是一等函数。
某些新的命令式语言提供了对一等函数的支持,但有一些限制:
-
Java不提供嵌套函数,但提供了匿名内部类,因此一个匿名类的一个方法是被嵌套在另一个方法内的。但一个内层方法只能访问外层方法的final变量[AGH05]。一个final变量的值为常量,因此Java编译器只需简单地将变量拷贝到内层类中,内层方法会像访问常规实例变量一样访问它。(换句话说,它避免了由于禁止赋值而需要赋值转换。)
-
Python提供了嵌套函数,但内层函数只能访问外层变量,而不能对外层变量进行赋值[Lut06]。
-
Perl提供了使用词法作用域的一等函数。Perl的所有变量都在堆中分配,因此很容易实现闭包[Sri97]。但所有函数调用(不仅包括闭包)的总体性能为此付出的代价很大。
3 Lua中的闭包
Lua使用基于寄存器的虚拟机[IdFC05](就我们所知,Lua的虚拟机是第一个被广泛应用的基于寄存器的虚拟机)。每次函数调用都在栈上分配一个活动记录,活动记录中包含了函数使用的寄存器,因此每个函数都有独立的寄存器集合。编译器按照栈的规则分配寄存器。在一次函数调用中,调用函数将参数保存到活动记录中位置最高的空闲寄存器中,这些寄存器会成为被调用函数位置最低的寄存器(如图1所示)(换句话说,Lua使用了软件版本的寄存器窗口)。

图1 Lua VM使用的软件寄存器窗口。
参数x和y被分配到寄存器0和1。
局部变量和临时变量总是被分配为寄存器。每个函数最多分配250个寄存器,这个限制是由于虚拟机指令使用8 bit表示寄存器。如果函数需要更多寄存器(如函数有过多局部变量或中间变量),编译器会引发“function or expression too complex”错误。在极少数情况下,开发者可能会超出寄存器的限制,此时可简单地通过重构解决这个问题(如通过显式的块或函数限制作用域)。
Lua使用闭包的扁平表示[Car84],如图2所示。GC头部包含了垃圾回收信息,本文并不讨论此部分。接下来,闭包包含了一个指向原型的指针,原型包含了函数的所有静态信息:主要部分是函数编译之后的代码,其余包括参数个数、调试信息和其他类似的数据。最后,闭包还包含0个或多个指向upvalue的指针,每个upvalue表示一个由闭包使用的非局部变量。这种每个upvalue对应一个变量的扁平表示非常适用于很少使用或不使用非局部变量的闭包,这类闭包在非函数式语言中很常见。此外,这种表示也支持safe-for-space的实现[SA94]。
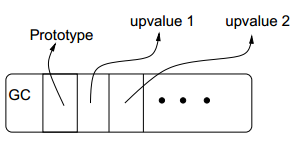
图2 Lua闭包的表示
Lua闭包实现的核心部件是upvalue结构,它表示了一个闭包和一个变量的连接。图3a显示了一个upvalue的结构。第一个成员GC在此不做讨论。下一个成员是一个指向upvalue包含的值的指针。通过该结构,解释器可通过一次间接访问而访问包含非局部变量值的单元(cell)。以下C代码粗略描述了取一个下标为i的非局部变量的地址的过程:
closure->upvalue[i]->cell
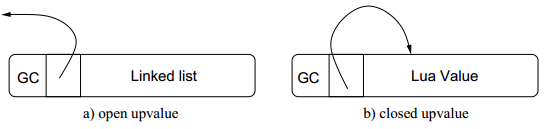
图3 upvalue结构
用于访问upvalue的虚拟机指令有2条:GETUPVALUE将一个upvalue的值复制到寄存器;SETUPVALUE将一个寄存器的值复制到upvalue。
一个upvalue有两种状态:open和closed。当一个upvalue被创建时,它是open的,并且它的指针指向Lua栈中对应的变量。当Lua关闭了一个upvalue,upvalue指向的值被复制到upvalue结构内部,并且指针也相应进行调整。图3b显示了一个closed upvalue。
现在,我们假设一个函数能访问的外部变量仅包括它的直接外层函数的局部变量,这样当Lua创建一个闭包时,它的所有外部变量都在当前正在执行的函数(直接外层函数)的活动记录中。因此,当Lua创建一个闭包时,为每个闭包使用的非局部变量创建一个upvalue结构,将upvalue关联到栈中对应的变量,并将闭包和upvalue连接。当一个变量退出作用域时,解释器关闭它所对应的upvalue,将变量的值复制到upvalue结构的一个保留成员中,并将upvalue的指针指向该成员(如图3b所示)。
下面讨论处理不在直接外层函数内的外层变量的方法。以下是一个柯里化(curried)的包含3个参数的加法函数:
function add3 (x) -- f1 return function (y) -- f2 return function (z) return x + y + z end -- f3 end end
内层函数f3需要3个变量:x、y和z。当函数f3执行时,变量z在函数f3的活动记录中。变量y在f3的闭包的一个upvalue中:当闭包被创建时,y在当前执行的函数(f2)的活动记录中。
变量x在f3的闭包被创建时可能已经消失了。为了解决这个问题,编译器将x加入f2的upvalue集合中,其效果与下面的代码类似:
function add3 (x) return function (y) local dummy = x return function (z) return dummy + y + z end end end
编译器不会为占位变量dummy的赋值生成代码,而是为中间函数(f2)加入一个保存变量x的upvalue。因此当f2的闭包被创建时,解释器会为x创建一个upvalue。现在,当f3的闭包被创建时,解释器只是简单地将f2闭包中x的upvalue复制到f3的闭包。
共享和关闭upvalue
前述的模式并未提供复用。如果两个闭包需要一个共同的外部变量,每个闭包都会有一个独立的upvalue。当这些upvalue关闭后,每个闭包都包含该共同变量的一个独立的拷贝。当一个闭包修改该变量时,另一个闭包将看不到此修改。
为避免这个问题,解释器必须确保每个变量最多只有一个upvalue指向它。解释器维护了一个保存栈中所有open upvalue的链表(如图4)。该链表中upvalue顺序与栈中对应变量的顺序相同。当解释器需要一个变量的upvalue时,它首先遍历这个链表:如果找到变量对应的upvalue,则复用它,因此确保了共享;否则创建一个新的upvalue并将其链入链表中正确的位置。

图4 open upvalue链表
由于upvalue链表是有序的,且每个变量最多有一个对应的upvalue,因此当在链表中查找变量的upvalue时,遍历元素的最大数量是静态确定的。最大数量是逃往(escape to)内层闭包的变量个数和在闭包和外部变量之间声明的变量个数之和。例如,以下的代码段:
function foo () local a, b, c, d local f1 = function () return d + b end local f2 = function () return f1() + a end ...
当解释器初始化f2时,解释器在确定a没有对应的upvalue之前会遍历3个upvalue,按顺序分别是f1、d和b。
当一个变量退出作用域时,它所对应的upvalue(如果有)必须被关闭。open upvalue链表也被用于关闭upvalue。当Lua编译一个包含逃离的变量(被作为upvalue)的块时,它在块的末尾生成一个CLOSE指令,该指令“关闭到某一层级(level)为止的upvalue”。执行该指令时,解释器遍历open upvalue链表直到到达给定层级为止,将栈中变量值复制到upvalue中,并将upvalue从链表中移除(如图5)。
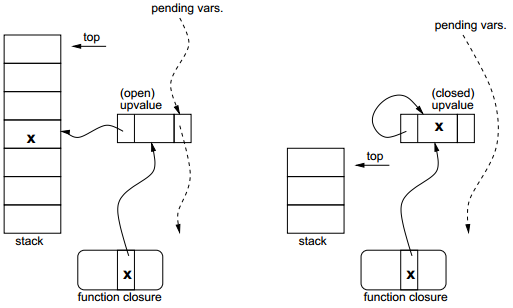
图5 关闭一个upvalue
为描述open upvalue链表如何确保upvalue共享,考虑如下的代码段:
local a = {} -- an empty array local x = 10 for i = 1, 2 do local j = i a[i] = function () return x + j end end x = 20
在代码段开头,open upvalue链表是空的。因此,当解释器在循环中创建第一个闭包时,它会为x和j创建upvalue,并将其插入upvalue链表中。在循环体的末尾有一条CLOSE指令标识j退出了作用域,当解释器执行这条指令时,它关闭j的upvalue并将其从链表移除。解释器在第二次迭代中创建闭包时,它找到x的upvalue并复用,但找不到j的upvalue,因此创建一个新的upvalue。在循环体末尾,解释器再一次关闭j的upvalue。
在循环结束之后,程序中包含两个闭包,这两个闭包共享一个x的upvalue,但每个闭包有一个独立的j的拷贝。x的upvalue是开启的,即x的值仍在栈中。因此最后一行的赋值(x=20)改变了两个闭包使用的x值。
编译器
下面将讨论编译器的工作方式,其要点是如何使用一遍式编译器为之前讨论的代码即时生成指令。
如之前讨论的,所有局部变量都保存在寄存器中。当编译器看到一个局部变量定义时,它为该变量分配一个新的寄存器。在当前函数内,所有对该变量的访问都会生成引用对应的寄存器的指令,即使该变量在之后逃往内层函数。
编译器递归地编译内层函数。当编译器看到一个内层函数时,它停止为当前函数生成指令,并为新的函数生成完整的指令。在编译内层函数时,编译器为该函数需要的所有upvalue(外部变量)创建一个表;在最终生成的闭包结构中也反映了这张表。当函数结束时,编译器返回外层函数,并生成一条创建带有所需upvalue的闭包的指令。
当编译器看到一个变量名时,它会查找该变量。查找的结果有三种:全局变量;局部变量;外部变量,即外层函数的局部变量。编译器首先查找当前的局部变量,若找到,则可确定变量保存在当前活动记录的某个固定的寄存器中。若没有找到,则递归地查找外层函数的变量;若没有找到变量名,则该变量是全局变量(与Scheme的某些实现相同,Lua的自由变量默认为全局。)。否则该变量是某个外层函数的局部变量。在这种情况下,编译器添加一条(或复用)该变量的引用到当前函数的upvalue表中。如果一个变量在upvalue表中,则编译器使用它在表中的位置生成GETUPVAL或SETUPVAL指令。
查找变量的过程是递归的,因此当一个变量被加入当前函数的upvalue表中时,该变量或是直接外层函数的局部变量,或已被加入外层函数的upvalue表。作为示例,考虑图6代码中函数C的return语句的编译。编译器在当前局部变量表找到变量c,因此将其作为局部变量处理。编译器在当前函数找不到g,因此在它的外层函数B中查找,接着递归地在函数A和包裹程序块的匿名函数中查找;最终没有找到g,因此编译器将其作为全局变量处理。编译器在当前函数中找不到变量b,因此在函数B中查找;在函数B的局部变量表中找到b,接着在C的upvalue表中加入b。最后,编译器在当前函数中找不到a,因此在B中查找;在B中也没有找到,紧接着在A中查找;因此,编译器将a加入B的upvalue表和C的upvalue表。

图6 访问不同类型的变量
upvalue表中的每个条目都包括一个标志和一个索引。标志标识变量是否是外层函数的局部变量。若变量是外层函数的局部变量,则索引表示它在活动记录中的寄存器位置;若变量是外层函数的upvalue,则索引表示它在upvalue表中的位置。在两种情况下,条目中都包含足够的信息用以定位外层函数的变量。
在图6所示的例子中,在编译即将结束时,函数C的upvalue表中包含两个upvalue:第一个(b)是外层函数的局部变量,其索引为1,因为它将保存在函数B的寄存器1中;第二个(c)是外层函数的upvalue,它的索引也为1,因为它是函数B的第一个(也是唯一一个)upvalue。
当编译器编译完一个函数后,它回到外层函数并生成一条CLOSURE指令,该指令创建闭包。该指令引用由内层函数生成的原型,并包含它的upvalue表的紧凑表示。在执行该指令时,解释器首先创建一个包含正确数量的upvalue的闭包对象,接着按照upvalue表填充它的upvalue成员:若upvalue是当前执行函数的upvalue,解释器复制当前执行闭包中指向upvalue对象的指针到新创建的闭包;若upvalue是当前执行函数的局部变量,解释器创建一个(或复用)指向栈中对应变量的upvalue对象。
为生成CLOSE指令,编译器跟踪记录每个块中的变量是否被内层函数使用。因此,当编译器到达块末尾时,它能够确定是否需要生成CLOSE指令。但能够打断块的命令可能引发问题,考虑如下代码:
function foo (x) while true do if something then return end globalvar = function () return x end end end
函数foo可能执行两次循环,在第一次循环中创建闭包,在第二次返回。然而当编译器为return语句生成指令时,它还不知道x逃离了。因此,RETURN指令始终会遍历open upvalue链表并关闭当前函数的所有upvalue。通常情况下函数不包含open upvalue,此时此遍历最多需要两次判断(表是否为空、第一个元素的层次是否比函数的基层次低)。
除了return语句之外,Lua中能够退出一个块的语句仅有break语句。Lua中没有goto语句。在Lua中,break语句仅能退出包含该语句的最内层循环,因此在循环外部定义的变量不会随着break而退出作用域。在循环内部定义的变量只有在break之前被使用才能逃离(因为循环内部没有回跳)。因此,当编译器编译break时,它能够确定是否退出了逃往内层函数的变量的作用域;若退出了作用域,则它在跳出循环之前生成一条CLOSE指令。
若发生错误,错误处理机制首先关闭upvalue链表中所有位于错误处理函数的层次之上的open upvalue。
协程
Lua提供对独立栈协程(stackful coroutines)的支持[dMRI04, dMI09],即每个协程有独立的栈。因此,Lua中的闭包可能构成“仙人掌”结构,在这个结构中一个闭包可能访问多个不同的栈的局部变量。图7的示例代码描述了这种情况。调用coroutine.create从给定的函数创建协程,coroutine.resume运行该协程。当协程运行时,它创建了闭包f。该闭包引用了变量x和y,变量x在主协程的栈中存活,而y在协程co的栈中存活。若这种情况再次发生(例如函数f使用一个新的函数创建一个新的协程),那么一个闭包可能从任意个不同的栈中访问变量。

图7 闭包访问多个栈中的变量
我们的机制能够不经修改而与协程正常协作,只需要每个栈都包含一个独立的upvalue链表。当Lua创建一个闭包时,它的upvalue或来自当前执行协程的栈,或来自外层闭包的upvalue。
4 评估
如我们之前讨论的,高阶函数在过程式语言中并非被频繁使用,而仅在少数重要任务中出现。因此,我们首先关注的是我们的实现在不使用高阶函数的程序中的开销。
不使用闭包的情况下的开销
需要考虑两点:函数的创建和调用。
函数创建的唯一更改是在函数引用和它的原型的引用之间增加了一个中间结构——闭包,因此Lua中的每个函数都需要承担这个额外结构的时间和空间开销。
当然,由不使用高阶函数的程序创建的函数数量是受程序源代码限制的。这样的程序不会动态创建新函数,程序源代码中每个函数都只有一个实例。因此,创建函数的额外开销是有限的。每个函数原型有且仅有一个闭包。
一个原型比一个不包含upvalue的闭包大得多。一个空函数的原型尺寸最小,大约80字节,而一个不包含upvalue的闭包为20字节。因此空间开销是微不足道的。
函数创建的时间开销也可按照相似的过程进行评估。函数的编译过程中创建了这些结构:原型本身,虚拟机指令数组,函数需要的常量的数组,由分析器使用的两个辅助表,等等。与大部分运行时操作相比,编译是一个相对高代价的过程。与编译相比,创建一个表示闭包的结构的时间开销也可忽略不计。
现在让我们考虑函数调用。当函数被调用时,解释器需要一次额外的间接访问才能获取到函数原型,因为函数的引用是指向闭包而非直接指向原型的。在虚拟机指令的执行期间是没有开销的:所有变量都在栈中的寄存器中;当源码中没有定义内层函数时不会出现CLOSE指令。仅有RETURN指令需要检查是否有需要关闭的upvalue(如我们在第3节讨论的),当没有函数使用外部变量时,open upvalue链表始终是空的,因此该检查只是简单地判断空链表。
使用闭包的开销
现在让我们分析使用闭包的开销,首先从内存分配开始。
Lua不支持任何形式的闭包共享。每个闭包访问的每个外部变量在闭包中都需要一个独立的条目。这种设计减少了编译器所需的额外内存开销和复制值到新闭包的开销。这些开销在过程式语言中不会太高,因为闭包创建在过程式语言中不会像在函数式语言中一样频繁。
除了条目本身以外,一个闭包也需要upvalue结构的内存。这个结构在访问一个共同变量的闭包之间共享。在最坏情况下,只有一个闭包访问给定的外部变量,因此我们可以考虑对每个闭包访问的外部变量,闭包都需要一个新的upvalue结构。因此,一个闭包所需要的总空间大约为32+28n字节,其中n是闭包使用的外部变量的数量。
访问upvalue的速度几乎和访问局部变量一样快,因为一次间接访问的开销相对于解释器的开销来说很小。然而,upvalue的使用在Lua中的成本可能很高。由于Lua使用基于寄存器的虚拟机,某些指令可直接访问栈帧中的局部变量。作为示例,考虑语句var = var + 1。若var是局部变量,并假设保存在寄存器5中,则该语句生成如下指令:
ADD R5, R5, 1
而在操作upvalue之前必须将其载入寄存器中。因此,若var是非局部变量,同样的语句var = var + 1需要3条指令:
GETUPVAL R6, 4 ADD R6, R6, 1 SETUPVAL R6, 4
虚拟机必须将upvalue载入寄存器后进行操作,最后将结果保存回upvalue。当然,通过添加直接操作upvalue的指令来减少甚至消除这个开销是可能的,但会增加虚拟机的复杂度。
5 结语
参考文献
[AGH05] Ken Arnold, James Gosling, and David Holmes. The Java Programming
Language. Prentice Hall PTR, fourth edition, 2005.
[AKK+86] Norman Adams, David Kranz, Richard Kelsey, Jonathan Rees, Paul Hudak,and James Philbin. ORBIT: an optimizing compiler for Scheme. SIGPLAN Notices, 21(7), July 1986. (SIGPLAN’86).
[Car84] Luca Cardelli. Compiling a functional language. In LFP’84: Proceedings of the 1984 ACM Symposium on LISP and Functional Programming, pages 208–217. ACM, 1984.
[dMI09] Ana L´ucia de Moura and Roberto Ierusalimschy. Revisiting coroutines. ACM Transactions on Programming Languages and Systems, 31(2):6.1–6.31, 2009.
[dMRI04] Ana Lucia de Moura, Noemi Rodriguez, and Roberto Ierusalimschy. Coroutines in Lua. Journal of Universal Computer Science, 10(7):910–925, July 2004. (SBLP 2004).
[Hem08] Ralph Hempel. Porting Lua to a microcontroller. In Luiz H. de Figueiredo, Waldemar Celes, and Roberto Ierusalimschy, editors, Lua Programming Gems, chapter 26. Lua.org, 2008.
[IdFC96] Roberto Ierusalimschy, Luiz H. de Figueiredo, and Waldemar Celes. Lua—an extensible extension language. Software: Practice and Experience, 26(6):635–652, 1996.
[IdFC05] Roberto Ierusalimschy, Luiz H. de Figueiredo, and Waldemar Celes. The implementation of Lua 5.0. Journal of Universal Computer Science, 11(7):1159–1176, 2005. (SBLP 2005).
[IdFC07] Roberto Ierusalimschy, Luiz H. de Figueiredo, and Waldemar Celes. The evolution of Lua. In Third ACM SIGPLAN Conference on History of Programming Languages, pages 2.1–2.26, San Diego, CA, June 2007.
[Ier03] Roberto Ierusalimschy. Programming in Lua. Lua.org, Rio de Janeiro, Brazil, 2003.
[ISO06] ISO. Information Technology — Programming Languages — C#, 2006. ISO/IEC 23270:2006(E).
[Lan64] P. B. Landin. The mechanical evaluation of expressions. The Computer Journal, 6(4):308–320, 1964.
[Lut06] Mark Lutz. Programming Python. O’Reilly Media, Inc., 2006.
[SA94] Shong Shao and Andrew W. Appel. Space-efficient closure representations. SIGPLAN Lisp Pointers, VII(3):150–161, 1994.
[SA00] Shong Shao and Andrew W. Appel. Efficient and safe-for-space closure conversion. ACM Transactions on Programming Languages and Systems, 22(1):129–161, January 2000.
[Sri97] Sriram Srinivasan. Advanced Perl Programming. O’Reilly & Associates, Inc., 1997.
[Ste78] Guy L. Steele, Jr. Rabbit: A compiler for Scheme. Technical Report AITR-474, MIT, Cambridge, MA, 1978.