1.k8s概述
2.k8s安装单机与集群
3.pod
4.Replication Controller(RC)/Replica Set(RS)
5.Deployment
6.service
7.NodePort
8.service
9.Volume
1.k8s概述
k8s(Kubernetes)是容器集群管理系统,可以实现容器集群的自动化部署、自动化扩缩容、维护等功能。k8s能提供一个以“容器为中心的基础架构”,k8s的一个核心特点就是能够自主的管理容器来保证云平台中的容器按照用户的期望状态运行着。k8s着重于不间断的服务状态,即容器挂掉后自动重启,始终保持用户期望的集群数运行。
通过k8s可以实现的功能:
- 快速部署应用
- 快速扩展应用
- 无缝对接新的应用功能
- 节省资源,优化硬件资源的使用
k8s的特点:
- 可移植:支持公有云,私有云,混合云,多重云
- 可扩展:模块化,插件化,可挂载,可组合
- 自动化:自动部署,自动重启,自动复制,自动伸缩/扩展
k8s的核心组件:
- etcd:保存了整个集群的状态
- apiserver:提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制
- controller manager:负责维护集群的状态,比如故障检测、自动扩展、滚动更新等
- scheduler:负责资源的调度,按照预定的调度策略将pod调度到相应的机器上
- kubelet:负责维护容器的生命周期,同时也负责Volume和网络的管理
- container runtime:负责镜像管理以及pod和容器的真正运行(CRI)
- kube-proxy:负责为service提供cluster内部的服务发现和负载均衡
2.k8s安装单机与集群
这里笔者使用的是三台虚拟机(2G内存,2核),一主两从。
1.安装并更新依赖
[root@localhost ~]# yum -y update
[root@localhost ~]# yum install -y conntrack ipvsadm ipset jq sysstat curl iptables libseccomp
2.安装docker并设置docker仓库,配置镜像加速器等。关于docker的欢迎查看笔者的上一篇博客,这里就不再说明了:
https://www.cnblogs.com/pluto-charon/p/14118514.html
3.修改host文件,设置主从,保证集群中所有的机器的网络彼此能相互连接
[root@localhost ~]# yum install -y homanamectl
# 设置节点名称,主节点设置成m,从1设置为w1,从2设置为w2
[root@localhost ~]# hostnamectl set-hostname m
[root@localhost ~]# vi /etc/hosts
# 在这里我将153设置成主节点,将154设置成work1节点,将155设置成work2节点
192.168.189.153 m
192.168.189.154 w1
192.168.189.155 w2
# 测试,ping 节点名称,如果能名称,则说明已经设置成功了
[root@localhost ~]# ping w2
PING w2 (192.168.189.155) 56(84) bytes of data.
64 bytes from w2 (192.168.189.155): icmp_seq=1 ttl=64 time=0.689 ms
64 bytes from w2 (192.168.189.155): icmp_seq=2 ttl=64 time=0.559 ms
64 bytes from w2 (192.168.189.155): icmp_seq=3 ttl=64 time=0.686 ms
4.系统基础前提配置
# 关闭防火墙
[root@localhost ~]# systemctl stop firewalld && systemctl disable firewalld
# 关闭selinux
[root@localhost ~]# setenforce 0
[root@localhost ~]# sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
# 关闭swap,在linux下swap的作用类似于windows下的虚拟内存,关闭是为了更好的使用内存
[root@localhost ~]# swapoff -a
[root@localhost ~]# sed -i '/swap/s/^(.*)$/#1/g' /etc/fstab
# 配置iptables的ACCEPT规则
[root@localhost ~]# iptables -F && iptables -X && iptables -F -t nat && iptables -X -t nat && iptables -P FORWARD ACCEPT
# 设置系统参数
[root@localhost ~]# cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
5.安装kubeadm,kubelet和kubectl
# 配置yum源
[root@localhost ~]# cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
#查看kubeadm的版本
[root@localhost ~]# yum list kubeadm --showduplicates | sort -r
# 安装kubeadm,kubelet和kubectl,为了防止有坑,建议大家按照这样的顺便安装
[root@localhost ~]# yum install -y kubelet-1.14.0-0
[root@localhost ~]# yum install -y kubeadm-1.14.0-0 kubelet-1.14.0-0 kubectl-1.14.0-0
# 如果直接安装k8s可能会报错,因为docker中的cgroup和k8s的cgroup可能不一致,所以将docker和k8s设置同一个cgroup
[root@localhost ~]# vi /etc/docker/daemon.json
# 复制进去即可
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": ["https://fz0dvm3j.mirror.aliyuncs.com"]
}
# 重启docker
[root@localhost ~]# systemctl restart docker
[root@localhost ~]# sed -i "s/cgroup-driver=systemd/cgroup-driver=cgroupfs/g" /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
# 下面这个报错,才没有问题。这句话的涵义是检测k8s的cgroup是否是system,如果是就修改,没有就报错
sed:无法读取 /etc/systemd/system/kubelet.service.d/10-kubeadm.conf:没有那个文件或目录
# 开启k8s
[root@localhost ~]# systemctl enable kubelet && systemctl start kubelet
6.使用docker拉去k8s需要的镜像
# 查看docker hub上kubeadm所需要的镜像
[root@localhost ~]# kubeadm config images list
# 解决国内访问慢的问题,使用阿里云的镜像并拉取镜像
#!/bin/bash
set -e
KUBE_VERSION=v1.14.0
KUBE_PAUSE_VERSION=3.1
ETCD_VERSION=3.3.10
CORE_DNS_VERSION=1.3.1
GCR_URL=k8s.gcr.io
ALIYUN_URL=registry.cn-hangzhou.aliyuncs.com/google_containers
images=(kube-proxy:${KUBE_VERSION}
kube-scheduler:${KUBE_VERSION}
kube-controller-manager:${KUBE_VERSION}
kube-apiserver:${KUBE_VERSION}
pause:${KUBE_PAUSE_VERSION}
etcd:${ETCD_VERSION}
coredns:${CORE_DNS_VERSION})
for imageName in ${images[@]} ; do
docker pull $ALIYUN_URL/$imageName
docker tag $ALIYUN_URL/$imageName $GCR_URL/$imageName
docker rmi $ALIYUN_URL/$imageName
done
#拉取完成后,使用docker images查看镜像是否拉去成功
7.初始化
kubeadm init流程:
1.进行一系列的检查,确保这台机器能够部署k8s
2.生成k8s对外提供服务所需要的各种证书可对应的目录
目录在:/etc/kubernetes/pki
3.为其他组件生成kube-ApiServer所需要的配置文件
4.为Master组件生成Pod配置文件
5.生成etcd这样的yaml文件
6.master容器启动之后,kubeadm会通过检查localhost:6443/healthz这个master组件的健康检查URL,等待master组件完全运行起来
7.为集群生成一个bootstrap token
8.将master节点的重要信息,通过ConfigMap得方式保留在etcd中,供后续部署node节点使用
9.安装默认插件,kubernetes默认kube-haproxy和DNS两个默认安装(必须安装)
# 初始化master节点,然后让work节点加入192.168.189.153这个要换成自己的ip,如果init出了问题,在下一次init之前,需要先kubeadm reset
kubeadm init --kubernetes-version=1.14.0 --apiserver-advertise-address=192.168.189.153 --pod-network-cidr=10.10.0.0/16 --ignore-preflight-errors=Swap
#注意最后有这样的一句话,最好能保存一下,后面有需要用得到
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.189.153:6443 --token kfm4nl.6ptjcww2fl1rs7si
--discovery-token-ca-cert-hash sha256:9c134702ad78527df11429aa501d3db289b6c9272778429f10ed88ace7846830
# 查看是否kube是否创建成功,如下所示,有.kube表示已经创建成功
[root@m ~]# ls -a
. .. anaconda-ks.cfg .bash_history .bash_logout .bash_profile .bashrc .cshrc .kube .pki .tcshrc
# 创建文件并授权
[root@m ~]# mkdir -p $HOME/.kube
[root@m ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@m ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
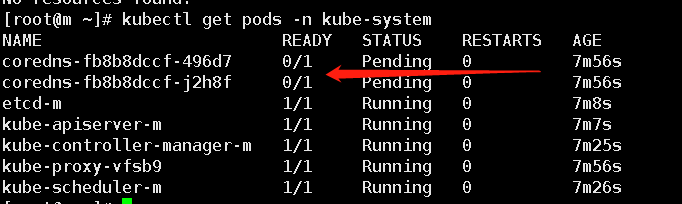
查看系统里中pod的情况,如下图可以看到有两个组件并没有开启,因为coredns解析需要网络插件,这个网络插件是为了在集群中能够通信,在这里笔者使用的是calico3.9。
[root@m ~]# kubectl get pods -n kube-system
# 下载文件
[root@m ~]# yum install -y wget
[root@m ~]# wget https://docs.projectcalico.org/v3.9/manifests/calico.yaml
# 下载完成后,apply
[root@m ~]# kubectl apply -f calico.yaml
# 查看calico中需要使用的镜像,然后使用docker pull 拉取这些镜像
[root@m ~]# cat calico.yaml | grep image
image: calico/cni:v3.9.6
image: calico/cni:v3.9.6
image: calico/pod2daemon-flexvol:v3.9.6
image: calico/node:v3.9.6
image: calico/kube-controllers:v3.9.6
# 拉去完成后,查看状态
[root@m ~]# kubectl get pods -n kube-system -w
还记得上面初始化成功后,有一句话最好保存一下吗?其实如果没保存,使用下面这行命令也可以查看的,如果想让其他工作节点加入,将下面的join命令复制到其他的虚拟机上执行即可。
[root@m ~]# kubeadm token create --print-join-command
kubeadm join 192.168.189.153:6443 --token ej3ta0.6smn0227gqafj95d --discovery-token-ca-cert-hash sha256:9c134702ad78527df11429aa501d3db289b6c9272778429f10ed88ace7846830
执行完成后,在主节点上查看k8s节点的信息
[root@m ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
m Ready master 91m v1.14.0
w1 NotReady <none> 40s v1.14.0
w2 NotReady <none> 30s v1.14.0
到这里,集群就配置完成了。
3.pod
pod是k8s创建或部署的最小/最简单的基本单元,一个pod代表集群上正在运行的一个进程。一个pod封装一个应用容器(也可以有多个容器),存储资源,一个独立的网络IP以及管理控制容器运行方式的策略选项,pod代表部署的一个单位:k8s中单个应用的实例,它可能有单个容器或多个容器共享组成的资源。
pod的两种主要使用方式:
- pod中运行一个容器,在这种情况下,可以将pod视为单个封装的容器,到那时k8s是直接管理pod而不是容器
- pods中运行多个需要一起工作的容器,pod可以封装紧密耦合的应用,他们需要由多个容器组成,他们之间能够共享资源,这些容器可以形成一个单一的内部service单位。
docker是k8s pod中最常用的容器运行时,但pod也能支持其他的容器运行时。
在这里我们使用pod创建一个nginx:
# 创建一个pod_nginx_rs.yaml文件
[root@m ~]# cat > pod_nginx_rs.yaml <<EOF
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx
labels:
tier: frontend
spec:
replicas: 3
selector:
matchLabels:
tier: frontend
template:
metadata:
name: nginx
labels:
tier: frontend
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
EOF
# 创建pod,创建的过程需要一点时间,需要拉取镜像等
[root@m ~]# kubectl apply -f pod_nginx_rs.yaml
# 查看nginx的详情信息
[root@m ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-8kvlj 1/1 Running 0 10m 192.168.80.193 w2 <none> <none>
nginx-jkvwh 1/1 Running 0 10m 192.168.190.66 w1 <none> <none>
nginx-r9rj2 1/1 Running 0 10m 192.168.190.65 w1 <none> <none>
# curl ip,访问nginx
[root@m ~]# curl 192.168.80.193
# 查看nginx是在哪台服务器上
[root@m ~]# kubectl describe pod nginx-jkvwh
# 在从机上查看该机器创建了几个pod
[root@w1 ~]# docker ps|grep nginx
pod终止流程:
-
用户发送一个命令来删除pod,默认的优雅退出时间为30s
-
API服务器中的pod更新时间,超过该时间则认为pod死亡
-
在客户端命令里面,pod显示为“Terminating(退出中)”的状态
-
与第三步同时,当kubelet看到pod被标记为退出中的时候,开始关闭pod
i.如果pod定义了一个停止前的钩子,其会在pod内部被调用,如果钩子在优雅退出时间段超时仍在运行,第二步会以一个很小的优雅时间段被调用
ii.进程被发送term的信号
-
与第三步同时,pod从service的列表中被删除,不在被认为是运行着的pod的一部分,缓慢关闭的pod可以继续对外服务,但负载均衡器将他们轮流移除
-
当优雅退出时间超时了,任何pod中正在运行的进程都会被SIGKILL信号杀死
-
kubelet会完成pod的删除,将优雅退出的时间设置为0(表示立即删除)。pod从API中删除,不在对客户端可见
4.Replication Controller(RC)/Replica Set(RS)
Replication Controller 保证了在所有时间内,都有特定数量的Pod副本正在运行并保证其可用性,如果太多了,Replication Controller就杀死几个,如果太少了,Replication Controller会新建几个。Replication Controller 就像一个进程管理器,监管着不同node上的多个pod,而不是单单监控一个node上的pod,Replication Controller 会委派本地容器来启动一些节点上服务(Kubelet ,Docker)。
由Replication Controller监控的Pod的数量是由一个叫 label selector(标签选择器)决定的,label selector在Replication Controller和被控制的pod创建了一个松散耦合的关系,与pod相比,pod与他们的定义文件关系紧密。
# 创建replicaset_nginx.yaml文件
[root@m ~]# cat > relicaset_nginx.yaml <<EOF
apiVersion: v1
# 表示新建对象的类型
kind: ReplicationController
metadata:
name: nginx
spec:
# 副本的数量,外部容器可以通过修改replicas的值来实现pod数量的变化
replicas: 3
selector:
app: nginx
# 用于定义pod的模板,如pod的名称等
template:
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
EOF
删除一个pod,会发现,马上又创建了一个
[root@m ~]# kubectl delete pod nginx-927f9
扩缩容:
我上面是创建的3个pod,现在将起扩充到5个
[root@m ~]# kubectl scale rc nginx --replicas=5
# 可以看到有两个正在创建
[root@m ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-927f9 1/1 Running 0 5m18s
nginx-9sb48 0/1 ContainerCreating 0 10s
nginx-fgpxk 1/1 Running 0 5m18s
nginx-sn4gx 1/1 Running 0 5m18s
nginx-x6jtx 0/1 ContainerCreating 0 10s
如果都不想要了,那么必须是要删除yaml文件才行。
[root@m ~]# kubectl delete -f relicaset_nginx.yaml
ReplicaSet是下一代复本控制器。ReplicaSet和 Replication Controller之间的唯一区别是现在的选择器支持。Replication Controller只支持基于等式的selector(env=dev或environment!=qa),但ReplicaSet还支持新的,基于集合的selector。
5.deployment
deployment为pod和ReplicaSet提供了一个声明式更新定义的方法。只需要在Deployment中描述你想要的目标状态是什么,Deployment controller就会帮你将Pod和Replica Set的实际状态改变到你的目标状态。
典型的应用场景包括:
- 定义Deployment来创建pod和ReplicaSet
- 滚动升级和回滚应用(可以在任何时间点更新应用的时候保证某些实例依然可以正常运行来防止应用 down 掉,当新部署的 Pod 启动并可以处理流量之后,才会去杀掉旧的 Pod。)
- 扩缩容
- 暂停和继续Deployment
下面的滚动更新的例子:
# 创建deployment.yaml文件
[root@m ~]# cat > deployment_nginx.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
EOF
# 创建pod
[root@m ~]# kubectl apply -f deployment_nginx.yaml
# 查看
[root@m ~]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 0/3 3 0 21s
[root@m ~]# kubectl get deployment -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
nginx-deployment 1/3 3 1 81s nginx nginx:1.7.9 app=nginx
# 如上所示,现在的nginx的版本是1.7.9,现在将版本更新,nginx-deployment为yaml文件中的metadata的name
[root@m ~]# kubectl set image deployment nginx-deployment nginx=1.9.1
deployment.extensions/nginx-deployment image updated
# 再次查看,可以看到已经更新成了1.9.1了
[root@m ~]# kubectl get deployment -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
nginx-deployment 1/3 1 1 5m nginx 1.9.1 app=nginx
6.service
由于Pod和Service是k8s集群范围内的虚拟概念,所以集群外的客户端系统无法通过Pod的IP地址或者Service的虚拟IP地址和虚拟端口号访问到它们。为了让外部客户端可以访问这些服务,可以将Pod或Service的端口号映射到宿主机,以使得客户端应用能够通过物理机访问容器应用。
Service 能够支持 TCP 和 UDP 协议,默认 TCP 协议。
对一些应用(如 Frontend)的某些部分,可能希望通过外部(Kubernetes 集群外部)IP 地址暴露 Service。
ServiceTypes 允许指定一个需要的类型的 Service,默认是 ClusterIP 类型。
Type 的取值以及行为如下:
- ClusterIP:通过集群的内部 IP 暴露服务,选择该值,服务只能够在集群内部可以访问,这也是默认的 ServiceType。
- NodePort:通过每个 Node 上的 IP 和静态端口(NodePort)暴露服务。NodePort 服务会路由到 ClusterIP 服务,这个 ClusterIP 服务会自动创建。通过请求
: ,可以从集群的外部访问一个 NodePort 服务。 - LoadBalancer:使用云提供商的负载局衡器,可以向外部暴露服务。外部的负载均衡器可以路由到 NodePort 服务和 ClusterIP 服务。
- ExternalName:通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容(例如, foo.bar.example.com)。 没有任何类型代理被创建,这只有 Kubernetes 1.7 或更高版本的 kube-dns 才支持。
Service还有一种资源叫HostPort:直接将容器的端口与所调度的节点上的端口路由,这样用户就可以直接通过宿主机的IP来访问Pod了。
HostPort和NodePort区别:HostPort只会在一台物理主机上打开端口,而NodePort在所有主机上都会打开
k8s默认的映射端口是30000-32767,如果需要映射其他端口,需修改kube-apiserver.yaml
vi /etc/kubernetes/manifests/kube-apiserver.yaml
# 找到这一行--service-cluster-ip-range ,在其下添加一个如下内容
- --service-node-port-range=1-65535
# 重启k8s
systemctl daemon-reload && systemctl restart kubelet
7. NodePort
如果设置 type 的值为 "NodePort",k8smaster 将从给定的配置范围内(默认:30000-32767)分配端口,每个 Node 将从该端口(每个 Node 上的同一端口)代理到 Service。该端口将通过 Service 的 spec.ports[*].nodePort 字段被指定。
如果需要指定的端口号,可以配置 nodePort 的值,系统将分配这个端口,否则调用 API 将会失败(比如,需要关心端口冲突的可能性)。
# 创建一个 Deployment
[root@m ~]# cat > whoami-deployment.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: whoami-deployment
labels:
app: whoami
spec:
replicas: 3
selector:
matchLabels:
app: whoami
template:
metadata:
labels:
app: whoami
spec:
containers:
- name: whoami
image: jwilder/whoami
ports:
- containerPort: 8000
EOF
[root@m ~]# kubectl apply -f whoami-deployment.yaml
# 创建成功后,查看当前service的状况
[root@m ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d1h
# 暴露一个service
[root@m ~]# kubectl expose deployment whoami-deployment
service/whoami-deployment exposed
# 再次查看,新增了一个service
[root@m ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d1h
whoami-deployment ClusterIP 10.99.211.118 <none> 8000/TCP 2s
# 测试 在任意一个节点上使用 10.99.211.118:8000访问,发现是能访问通的
[root@w2 ~]# curl 10.99.211.118:8000
I'm whoami-deployment-678b64444d-s2m2m
上面的这种方式只能在容器内部访问,要想在容器外部访问,要做如下的配置:
# 删除上面创建的yaml文件
[root@m ~]# kubectl delete -f whoami-deployment.yaml
# 删除service
[root@m ~]# kubectl delete svc whoami-deployment
# 创建一个 Deployment
[root@m ~]# cat > whoami-deployment.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: whoami-deployment
labels:
app: whoami
spec:
replicas: 3
selector:
matchLabels:
app: whoami
template:
metadata:
labels:
app: whoami
spec:
containers:
- name: whoami
image: jwilder/whoami
ports:
- containerPort: 8000
EOF
[root@m ~]# kubectl apply -f whoami-deployment.yaml
deployment.apps/whoami-deployment created
# 创建成功后,查看当前service的状况
[root@m ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d1h
# 暴露一个service
[root@m ~]# kubectl expose deployment whoami-deployment --type=NodePort
service/whoami-deployment exposed
# 再次查看,新增了一个service
[root@m ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d1h
whoami-deployment NodePort 10.99.86.219 <none> 8000:31669/TCP 26s
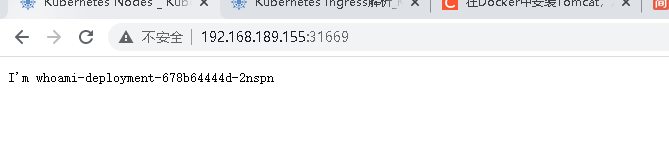
在虚拟机内部使用8000端口,可以访问:
[root@m ~]# curl 10.99.86.219:8000
I'm whoami-deployment-678b64444d-2nspn
[root@m ~]# lsof -i tcp:31669
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
kube-prox 2292 root 10u IPv6 79783 0t0 TCP *:31669 (LISTEN)
在浏览器上使用工作节点的ip+暴露的端口也访问:
8.Ingress
如果想让外界访问,我们可以使用service.type=NodePort这样的方式,但是生产环境不推荐使用这种方式。NodePort 的缺点是一个端口只能挂载一个 Service。所以生产环境一般使用Nginx Ingress Controller运行在一个合适的节点上,并使用hostport暴露出一个端口。
ingress就可以配置提供外部可访问的URL,负载均衡,SSL终结,基于名称的虚拟主机等。用户通过POST Ingress资源到API server的方式来请求ingress。Ingress 控制器通常负责通过负载均衡来实现Ingress ,尽管它可以配置边缘路由器火其他前端来帮助处理流量。Ingress 不会公开任意端口或协议,将HTTP和HTTPS以外的服务公开到Internet时,通常使用Service.Type=NodePort或Service.Type=LoadBalancer类型的服务。
# 部署Ingress Controller
[root@m ~]# vi mandatory.yaml
# 这个文件是从官网上下载的
# 也可以使用命令下载 wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/mandatory.yaml
apiVersion: v1
kind: Namespace
metadata:
name: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
---
kind: ConfigMap
apiVersion: v1
metadata:
name: nginx-configuration
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
---
kind: ConfigMap
apiVersion: v1
metadata:
name: tcp-services
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
---
kind: ConfigMap
apiVersion: v1
metadata:
name: udp-services
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: nginx-ingress-serviceaccount
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: nginx-ingress-clusterrole
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
rules:
- apiGroups:
- ""
resources:
- configmaps
- endpoints
- nodes
- pods
- secrets
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
- apiGroups:
- ""
resources:
- services
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- apiGroups:
- "extensions"
- "networking.k8s.io"
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
- "networking.k8s.io"
resources:
- ingresses/status
verbs:
- update
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: Role
metadata:
name: nginx-ingress-role
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
rules:
- apiGroups:
- ""
resources:
- configmaps
- pods
- secrets
- namespaces
verbs:
- get
- apiGroups:
- ""
resources:
- configmaps
resourceNames:
# Defaults to "<election-id>-<ingress-class>"
# Here: "<ingress-controller-leader>-<nginx>"
# This has to be adapted if you change either parameter
# when launching the nginx-ingress-controller.
- "ingress-controller-leader-nginx"
verbs:
- get
- update
- apiGroups:
- ""
resources:
- configmaps
verbs:
- create
- apiGroups:
- ""
resources:
- endpoints
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:
name: nginx-ingress-role-nisa-binding
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: nginx-ingress-role
subjects:
- kind: ServiceAccount
name: nginx-ingress-serviceaccount
namespace: ingress-nginx
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: nginx-ingress-clusterrole-nisa-binding
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: nginx-ingress-clusterrole
subjects:
- kind: ServiceAccount
name: nginx-ingress-serviceaccount
namespace: ingress-nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-ingress-controller
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
template:
metadata:
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
annotations:
prometheus.io/port: "10254"
prometheus.io/scrape: "true"
spec:
# wait up to five minutes for the drain of connections
terminationGracePeriodSeconds: 300
serviceAccountName: nginx-ingress-serviceaccount
# 为true表示Pod中运行的应用程序可以直接使用node节点的端口,这样node节点主机所在网络的其他主机,都可以通过该端口访问到此应用程序。
hostNetwork: true
nodeSelector:
name: ingress
kubernetes.io/os: linux
containers:
- name: nginx-ingress-controller
image: quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.26.1
args:
- /nginx-ingress-controller
- --configmap=$(POD_NAMESPACE)/nginx-configuration
- --tcp-services-configmap=$(POD_NAMESPACE)/tcp-services
- --udp-services-configmap=$(POD_NAMESPACE)/udp-services
- --publish-service=$(POD_NAMESPACE)/ingress-nginx
- --annotations-prefix=nginx.ingress.kubernetes.io
securityContext:
allowPrivilegeEscalation: true
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
# www-data -> 33
runAsUser: 33
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
ports:
- name: http
containerPort: 80
- name: https
containerPort: 443
livenessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 10254
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
readinessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 10254
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
lifecycle:
preStop:
exec:
command:
- /wait-shutdown
---
[root@m ~]# kubectl apply -f mandatory.yaml
# 创建tomcat-service文件
[root@m ~]# vi tomcat-service.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: tomcat-deployment
labels:
app: tomcat
spec:
replicas: 1
selector:
matchLabels:
app: tomcat
template:
metadata:
labels:
app: tomcat
spec:
containers:
- name: tomcat
image: tomcat
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: tomcat-service
spec:
ports:
- port: 80
protocol: TCP
# 因为service的端口与tomcat的端口不一致,所以需要指定tomcat的端口
targetPort: 8080
selector:
app: tomcat
[root@m ~]# kubectl apply -f tomcat-service.yaml
deployment.apps/tomcat-deployment created
service/tomcat-service created
# 查看服务
[root@m ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 4d1h
tomcat-service ClusterIP 10.104.189.196 <none> 80/TCP 2m21s
# 查看tomcat的pod是运行在 w1 上的
[root@m ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
tomcat-deployment-6b9d6f8547-t67nw 1/1 Running 0 6m29s 192.168.190.94 w1 <none> <none>
# service和pod都准备好后,在容器内部访问,这个时候访问,肯定会是一个404的html,因为docker拉取tomcat镜像,拉取得是最简单的tomcat镜像
[root@m ~]# curl 192.168.190.94:8080
# 进入tomcat容器
[root@m ~]# kubectl exec -it tomcat-deployment-6b9d6f8547-t67nw /bin/bash
# 将webapps.dist 文件的内容拷贝进webapp文件内
root@tomcat-deployment-6b9d6f8547-t67nw:/usr/local/tomcat# cp -r webapps.dist/* webapps
# 查看内容是否已经复制进去了
root@tomcat-deployment-6b9d6f8547-t67nw:/usr/local/tomcat# cd webapps
root@tomcat-deployment-6b9d6f8547-t67nw:/usr/local/tomcat/webapps# ls
ROOT docs examples host-manager manager
# 退出再次访问,就会发现可以访问
root@tomcat-deployment-6b9d6f8547-t67nw:/usr/local/tomcat/webapps# exit
因为tomcat-service是运行在w1上的,所以希望将nginx也运行在w1上面,原来这个文件是随机部署在任意节点上,现在使用标签选择器将文件指定部署在w1上。
[root@m ~]# kubectl label node w1 name=ingress
node/w1 labeled
查看节点信息会发现给w1打上了ingress的标签
[root@m ~]# kubectl get node --show-labels

上面配置的mandatory.yaml中配置nodeSeletor,这样就能保证Ingress Controller运行在w1节点上。

# 查看ingress-nginx
[root@m ~]# kubectl get pods -n ingress-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-ingress-controller-7c66dcdd6c-8dcvk 0/1 ContainerCreating 0 104s 192.168.189.154 w1 <none> <none>
# 如果处理问题可以查看详情
[root@m ~]# kubectl describe pod nginx-ingress-controller-7c66dcdd6c-5cmhp -n ingress-nginx
# 出了问题,可以删掉文件重新拉取
[root@m ~]# kubectl delete -f mandatory.yaml
[root@m ~]# kubectl apply -f mandatory.yaml
当上面这些都完成后,在w1节点上,会开放出HTTP对应的80端口和HTTPS对应的443端口。需要配置ingress的规则:
[root@m ~]# vi ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: nginx-ingress
spec:
rules:
- host: tomcat.charon.com
http:
paths:
- path: /
backend:
serviceName: tomcat-service
servicePort: 80
[root@m ~]# kubectl apply -f ingress.yaml
ingress.extensions/nginx-ingress created
# 查看
[root@m ~]# kubectl get ingress
NAME HOSTS ADDRESS PORTS AGE
nginx-ingress tomcat.charon.com 80 5s
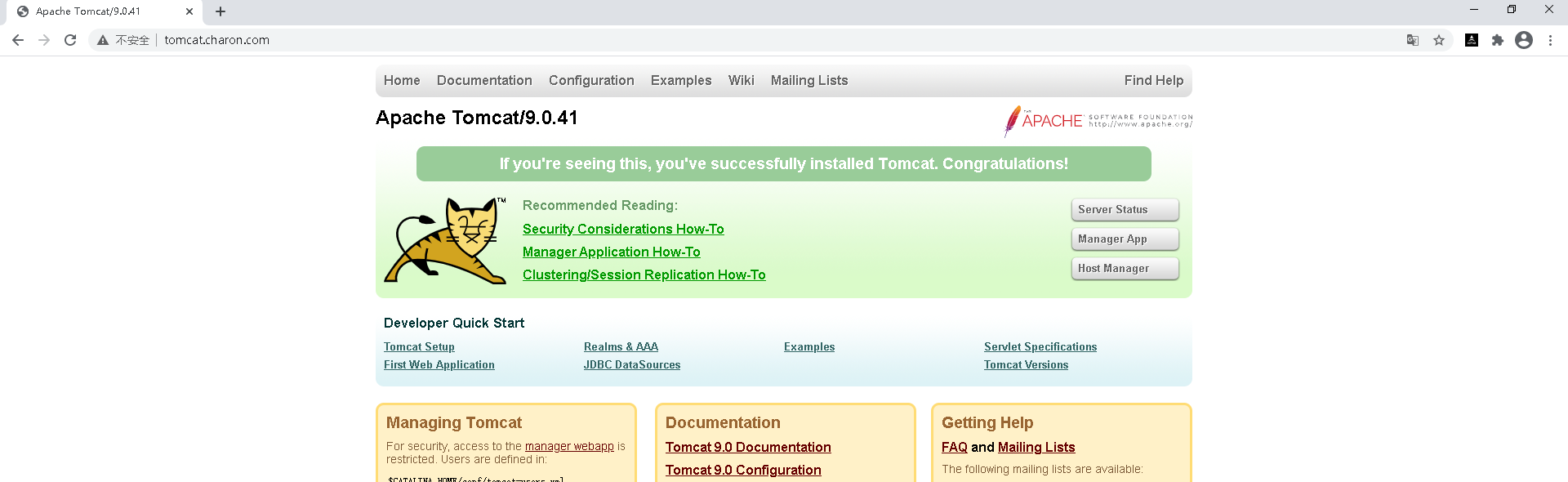
我在ingress.yaml文件中配置了域名是tomcat.charon.com,所以需要在windows里面配置域名。
目录:C:WindowsSystem32driversetc 的hosts文件
添加内容,因为我们要去w1上访问,所以配置的ip应该是w1的ip:192.168.189.154 tomcat.charon.com
然后再浏览器上输入域名即可访问
9.Volume
默认情况下容器中的磁盘文件是非持久化的,对于运行在容器中的应用来说面临两个问题,第一:当容器挂掉kubelet将重启启动它时,文件将会丢失;第二:当Pod中同时运行多个容器,容器之间需要共享文件时。k8s的Volume解决了这两个问题。
对于上面的示例,我们修改了tomcat的webapps的文件,如果重启pod之后,会发现访问依然会报404的错误。
# 安装nfs服务器
# w1节点上安装,因为tomcat就是安装在w1的
[root@m ~]# yum -y install nfs-utils rpcbind
# 其他节点安装
[root@w1 ~]# yum -y install nfs-utils
[root@w2 ~]# yum -y install nfs-utils
# w1节点上创建文件
[root@w1 app]# cd /
[root@w1 /]# mkdir -p /app/tomcat_data
# w1节点上授权
[root@m ~]# chmod -R 777 /app/tomcat_data
# w1节点上修改文件
[root@w1 ~]# vi /etc/exports
/app/tomcat_data 192.168.189.154(rw,no_root_squash,subtree_check,fsid=0)
# w1节点上重新挂载
[root@m tomcat_data]# exportfs -r
# w1节点上启动
[root@w1 ~]# systemctl start rpcbind && systemctl enable rpcbind
[root@w1 ~]# systemctl start nfs && systemctl enable nfs
Created symlink from /etc/systemd/system/multi-user.target.wants/nfs-server.service to /usr/lib/systemd/system/nfs-server.service.
# 其他节点上启动
[root@w1 ~]# systemctl start nfs
# w1节点上查看
[root@m tomcat_data]# showmount -e
Export list for w1:
/app/tomcat_data 192.168.189.154
# 这一步好像不是必须的,我没有加这一步也可以
[root@w1 ~]# mount -t nfs 192.168.189.154:/app/tomcat_data /app/tomcat_data
安装和配置完nfs服务器后(一定要注意,pod在那个节点服务器上,对应的文件应该也在那个服务器上),在主节点做如下配置:
# 创建 persistent-volume.yaml
[root@m ~]# vi persistent-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: tomcat-data
spec:
capacity:
storage: 2Gi
accessModes:
- ReadWriteMany
nfs:
path: /app/tomcat_data
server: 192.168.189.154
persistentVolumeReclaimPolicy: Recycle
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: tomcat-data
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 2Gi
[root@m ~]# kubectl apply -f persistent-volume.yaml
persistentvolume/tomcat-data created
persistentvolumeclaim/tomcat-data created
# 修改tomcat-service.yaml(位置如下图)
[root@m ~]# vi tomcat-service.yaml
volumeMounts:
- mountPath: /usr/local/tomcat/webapps
name: tomcat-data
volumes:
- name: tomcat-data
persistentVolumeClaim:
claimName: tomcat-data
# 重启pod
[root@m ~]# kubectl replace --force -f tomcat-service.yaml
deployment.apps "tomcat-deployment" deleted
service "tomcat-service" deleted
deployment.apps/tomcat-deployment replaced
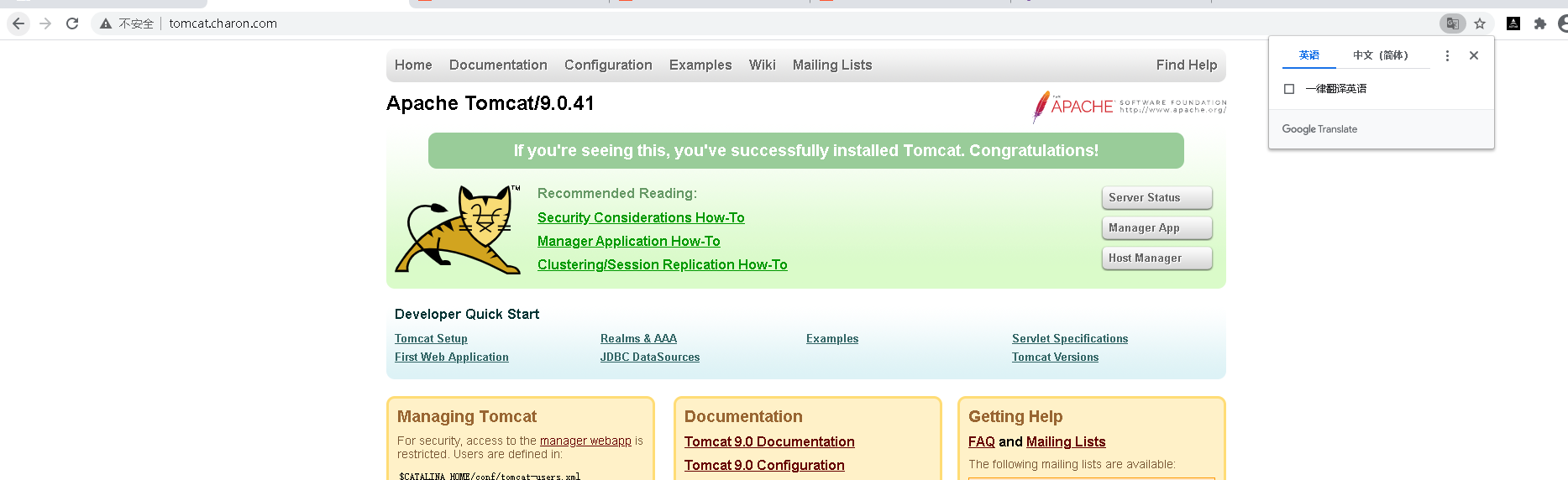
service/tomcat-service replaced

再次在浏览器上访问,出现tomcat的首页:
在w1节点上访问挂载的目录可以发现,tomcat的webapps目录下的文件全部都在里面:
[root@w1 ~]# cd /app/tomcat_data/
[root@w1 tomcat_data]# ls
docs examples host-manager manager ROOT
到这里persistentVolume就配置好了。
参考文档:
http://docs.kubernetes.org.cn/227.html#Kubernetes