Python实现论文查重(simhash算法)
| 这个作业属于哪个课程 | |
|---|---|
| 这个作业要求在哪里 | |
| 这个作业的目标 | 编程实操、PSP 表格实际使用、Git 使用与 GitHub 托管代码、项目性能测试 |
0 GitHub链接
1.1 开发环境
-
python 3.x
-
IDE:Visual Studio Code
-
性能测试工具:PyCharm
1.2 核心算法
-
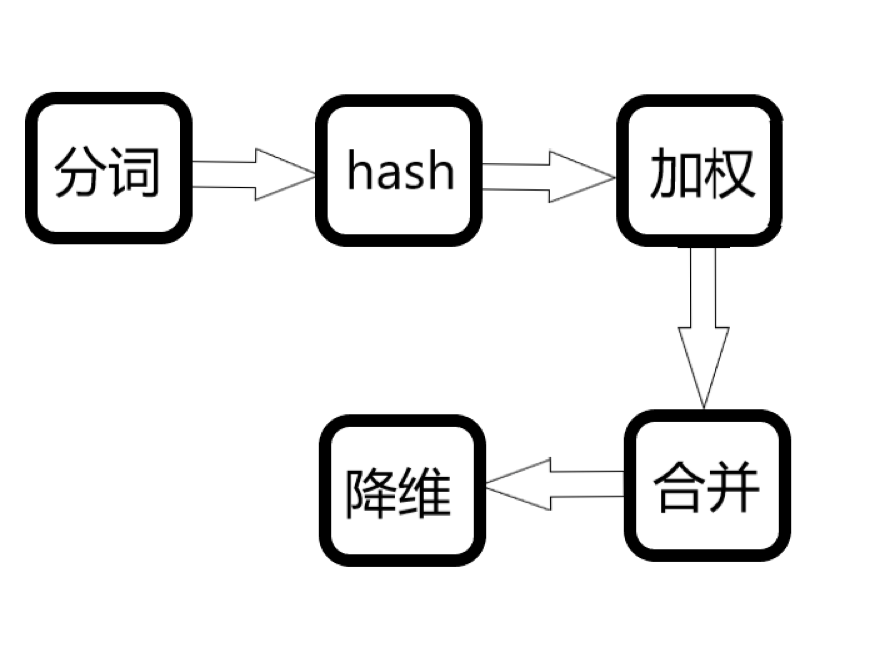
SimHash
-
具体可参考SimHash原理
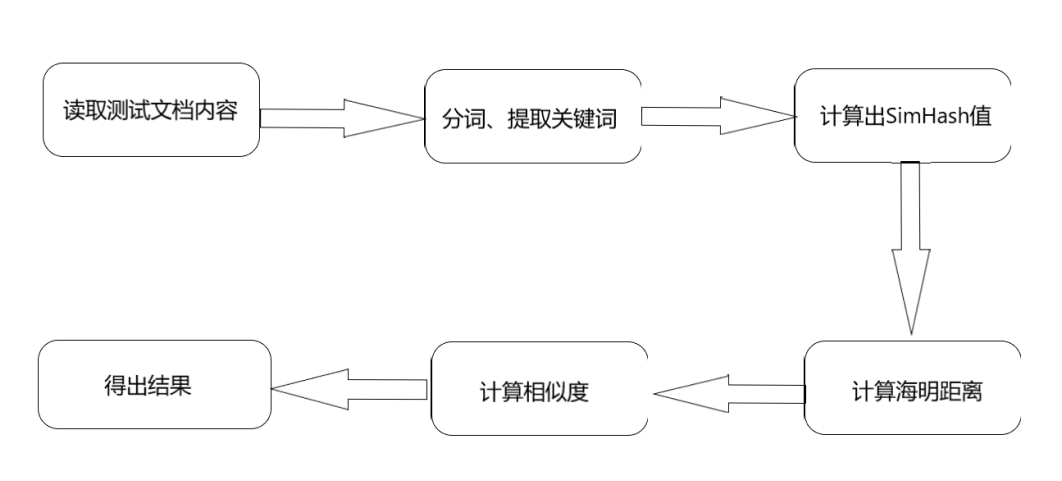
1.3 实现流程
2.0 核心算法代码实现
-
main.py中最终定义使用了四个函数:def cutText(text)、 getSimhash(str)、getDistance(hash1,hash2)、getSimilarity(hash1, hash2)
作用分别为分词、获取字符串的SimHash值、根据两hash值得到它们之间的汉明距离、得到相似度。
按逻辑顺序。
2.1 读取文件并分离关键词
def cutText(text):
file = open(text, 'r', encoding='utf-8')
seg_text = file.read()
words_len = len(list(jieba.lcut(seg_text)))
# topK_num为下面extract_tags()中参数topK的值,因为每篇文章不同,所以没有设置固定的参数值
topK_num = math.ceil(0.08 * words_len)
words = jieba.analyse.extract_tags(seg_text, topK=topK_num)
file.close()
return words
-
topK_num的存在使得用户可根据输入文档进行合适的选择
2.2 SimHash算法实现
def getSimhash(str):
vector = [0] * 128
i = 0
size = len(str)
for word in str:
# 利用MD5获得字符串的hash值
md5 = hashlib.md5()
md5.update(word.encode("utf-8"))
hash_value = bin(int(md5.hexdigest(), 16))[2:]
if len(hash_value) < 128: # hash值少于128位,需在低位以0补齐
dif = 128 - len(hash_value)
for d in range(dif):
hash_value += '0'
# 加权 合并
for j in range(len(vector)): # 加权:权重由词频决定,从高到低分别是10 -> 0
if hash_value[j] == '1':
vector[j] += (10 - (i / (size / 10)))
else:
vector[j] -= (10 - (i / (size / 10)))
i += 1
# 降维
simHash_value = ''
for x in range(len(vector)):
if vector[x] >= 0: # 对特征向量的每一位进行遍历,大于0置1,小于0置0
simHash_value += '1'
else:
simHash_value += '0'
return simHash_value
-
根据SimHash算法原理编写的算法,能通过计算词频加权,更好地计算长文本相似度。
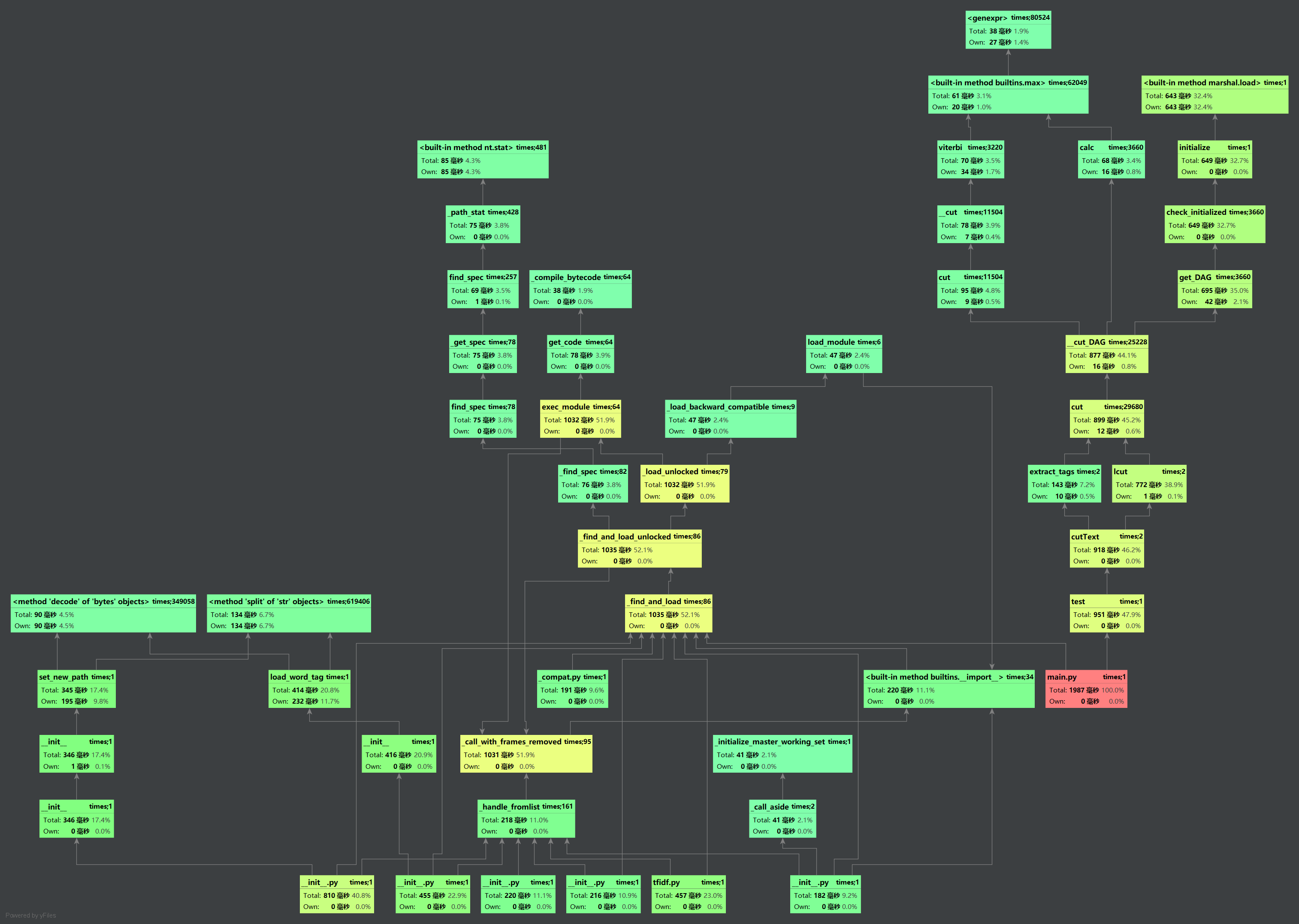
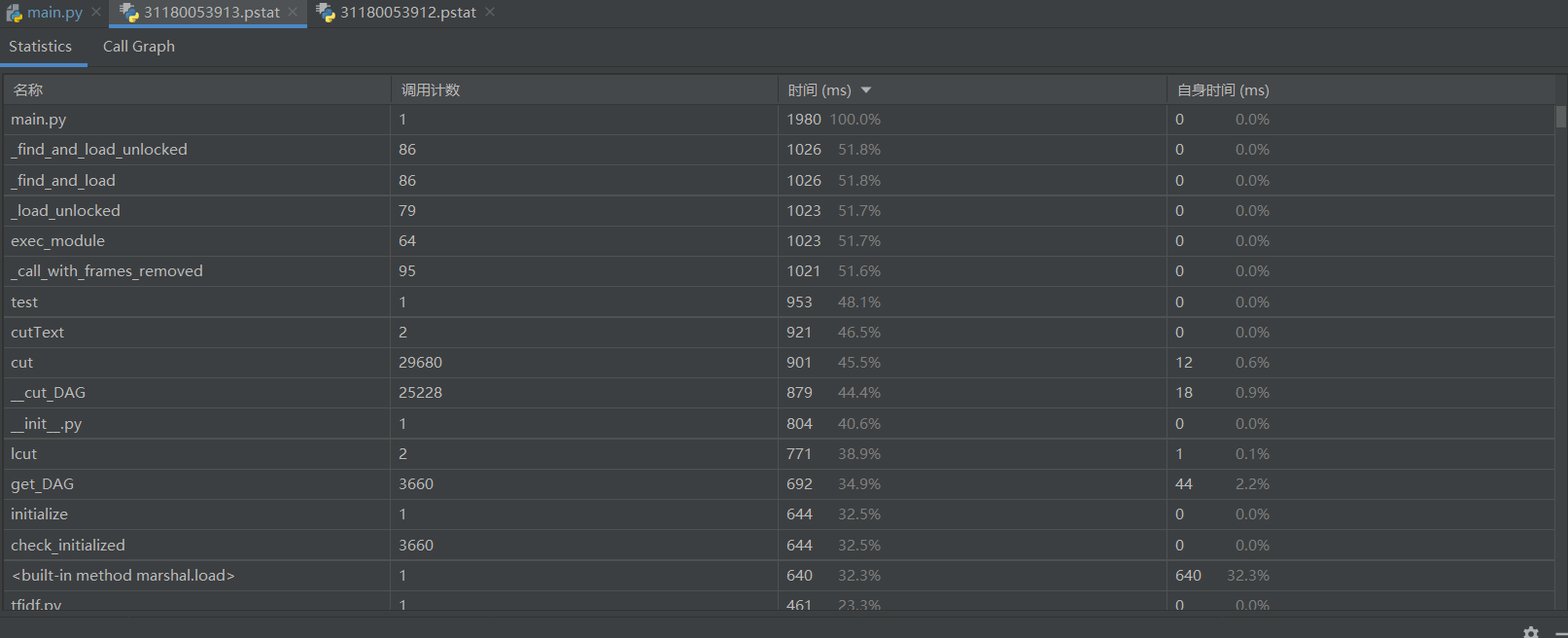
3.0 性能测试
3.1 性能分析
-
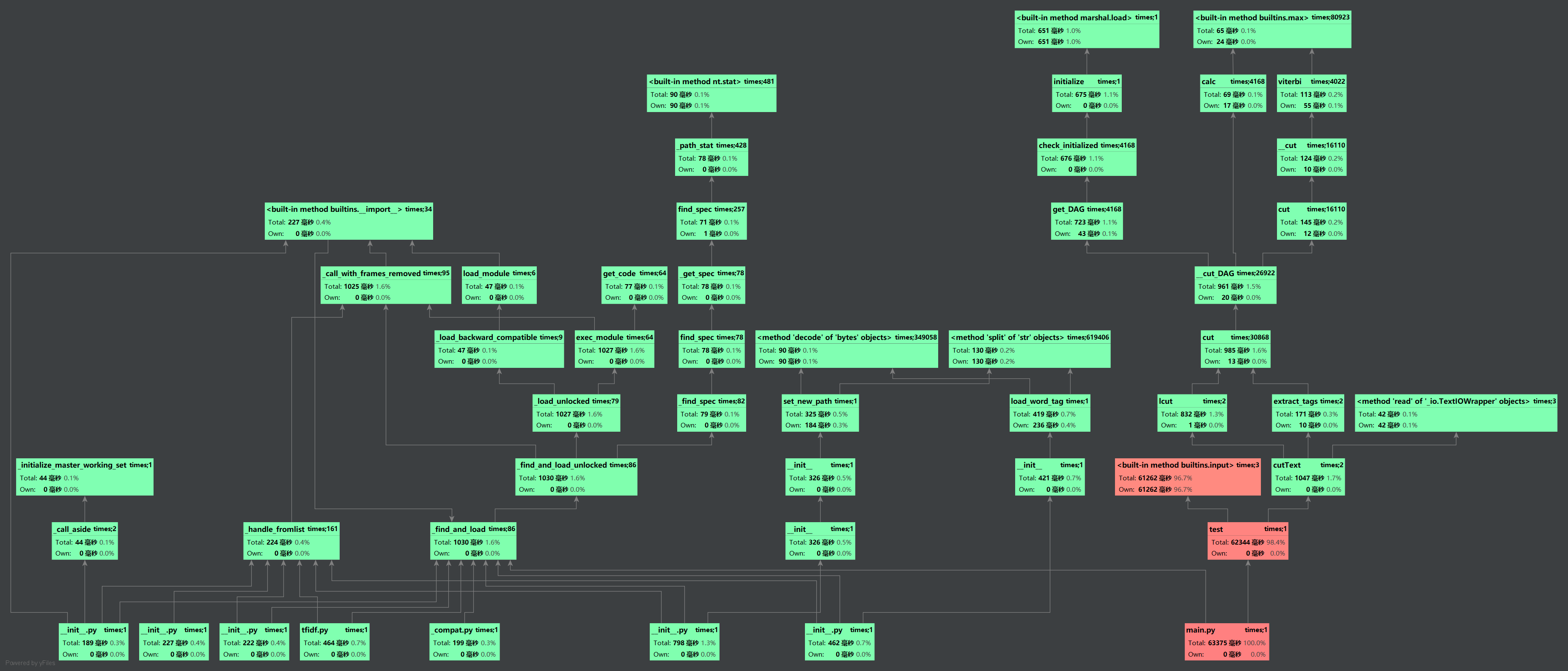
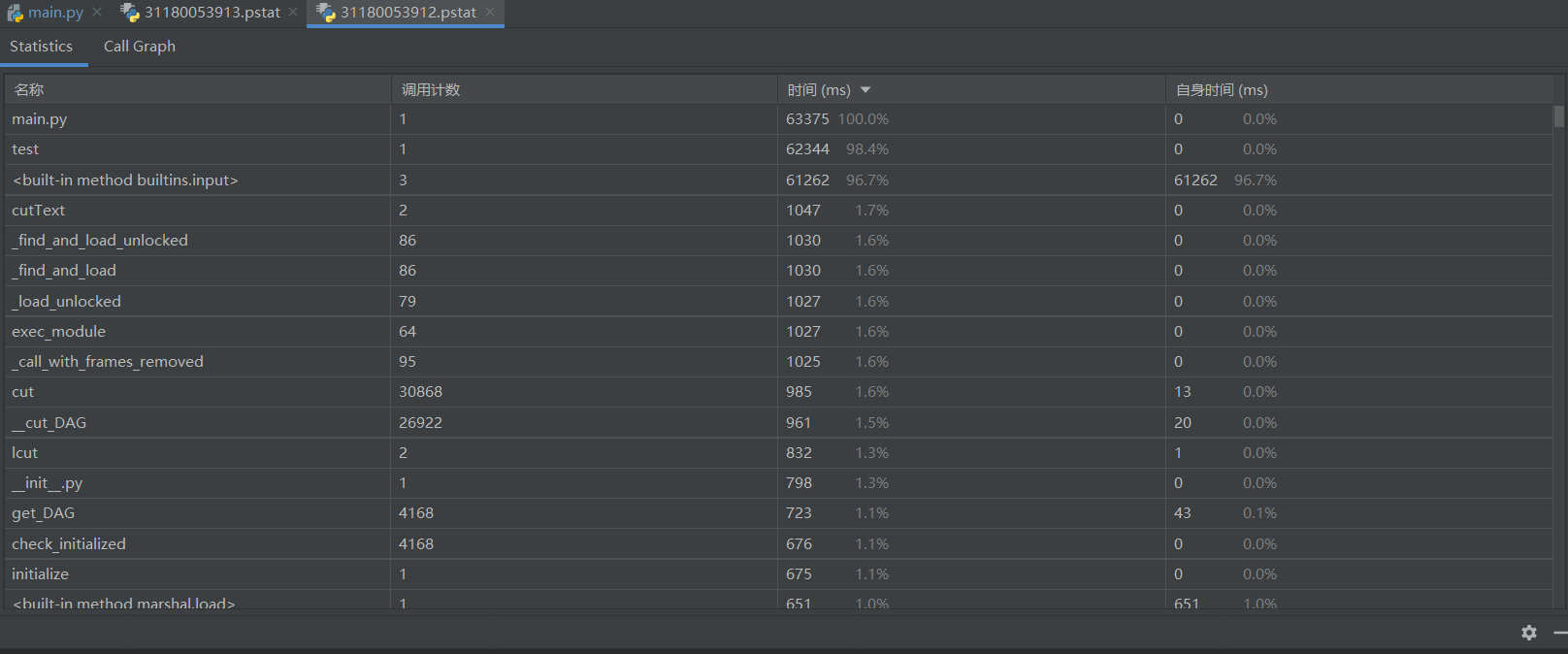
最初版本是需要携带参数[文件路径]运行,不便于性能分析
-
后改为手动输入文件路径,但可以看出input函数调用时间很长

-
为了便于得到性能分析结果,在test()中将文件路径提前输入

-
消耗时间最长的函数是cutText()
-
算法是经过消耗蛮多时间,查阅资料及多次动手改动编写后才进行性能分析的,所以没有展现改进计算模块性能上花费的时间。
4.0 单元测试
-
运行结果
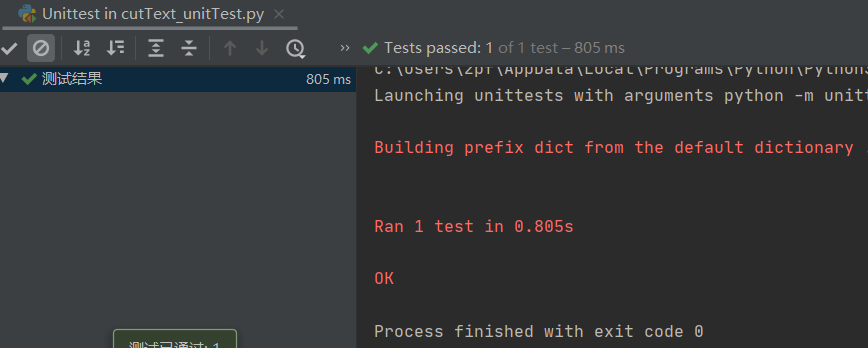
4.1 cutText()


-
使用PyCharm中的单元测试,可得到测试通过。
4.2 getSimhash()
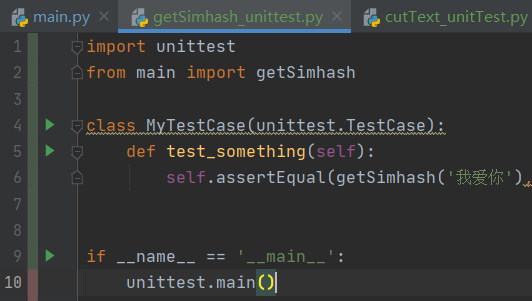
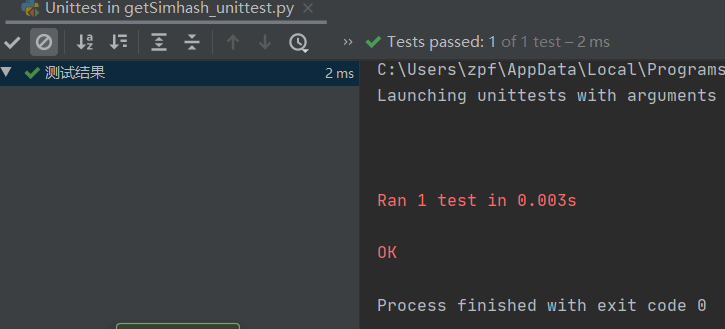

5.0 异常处理
5.1 运行python脚本时文件参数输入错误

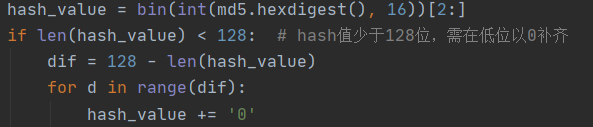
5.2 利用MD5()得到的hash值位数达不到128位
6.0 PSP
| *PSP2.1* | *Personal Software Process Stages* | *预估耗时(分钟)* | *实际耗时(分钟)* |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 60 |
| Development | 开发 | 1130 | 1350 |
| · Analysis | · 需求分析 (包括学习新技术) | 300 | 300 |
| · Design Spec | · 生成设计文档 | 60 | 30 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 90 | 120 |
| · Coding | · 具体编码 | 360 | 500 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 200 | 250 |
| Reporting | 报告 | 150 | 220 |
| · Test Report | · 测试报告 | 60 | 90 |
| · Size Measurement | · 计算工作量 | 30 | 40 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 90 |
| · 合计 | 1340 | 1630 |
7.0 总结
-
不能眼高手低,编程还是得踏踏实实敲键盘
-
要提前做好计划,且能及时适应变化 ,必须必须提前浏览作业要求(需求),拟好对应计划。