标号、变量和数据结构
当程序中要跳转到另一位置时,需要有一个标识来指示位置,这就是标号,通过在目的地址的前面放上一个标号,可以在指令中使用标号来代替直接使用地址。
关于变量的使用是任何编程语言都要遇到的工作,Win32汇编也不例外,在MASM中使用变量也有需要注意的几个问题,错误地使用变量定义或用错误的方法初始化变量会带来难以定位的错误。
变量是计算机内存中已命名的存储位置,在C语言中有很多种类的变量,如整数型、浮点型和字符型等,不同的变量有不同的用途和尺寸,比如说虽然长整数和单精度浮点数都是32位长,但它们的用途不同。
变量的值在程序运行中是经常改变的,所以它必须定义在可写的段内,如.data和.data?,或者在堆栈内。按照定义的位置不同,MASM中的变量也分为全局变量和局部变量两种。
在MASM中标号和变量的命名规范是相同的,它们是:
1)可以用字母、数字、下划级及符号@、$和?。
2)第一个符号不能是数字。
3)长度不能超过240个字符。
4)不能使用指令名等关键字。
5)在作用域内必须是唯一的。
这些规则是大部分编程语言约定俗成的!
标号的定义
当在程序中使用一条跳转指令的时候,可以用标号来表示跳转的目的地,编译器在编译的时候会把它替换成地址。
标号既可以定义在目的指令同一行的头部,也可以在目的指令前一行单独用一行定义,标号定义的格式是:
格式一 标号名: 目的指令
格式二 标号名:: 目的指令
我们比较常用的方法是使用格式一(一个冒号那个),注意这时候标号的作用域是当前的子程序,在不同子程序中可以存在同样名字的标号,这也就意味着这种格式不能从一个子程序通过标号跳转到另一个子程序中。
那如果实在痒,想跳,怎么办?
格式二就应运而生了!没错,当我们需要从一个子程序中用指令跳到另一个子程序中的标号位置时候,我们用格式二,但代码并不和谐!
@@
OK,大家一定想到了很多类似的肥猪流火星文***符号,很高兴我们学Win32汇编居然赶上了时代的主流阿,尼玛啊,有木有啊!
在DOS时代,为标号起名是个麻烦的事情,因为汇编指令用到跳转指令特别多,任何比较和测试等都要涉及跳转,所以在程序中会有很多标号,在整个程序范围内起个不重名的标号要费一番功夫,结果常常用addr1和addr2之类的标号一直延续下去……
事实上很多标号会使用一到两次,而且不一定非要起个有意义的名称,如汇编程序中下列代码结构很多:
mov cx,1234h
cmp flag,1
je loc1
mov cx,1000h
loc1:
loop loc1
在别的地方事实上就不会用到loc1了,尼玛啊,编程要讲究低碳,低碳啊,有木有?!
对于这种不环保的做法,我们用@@来取而代之!程序改下如下:
mov cx,1234h
cmp flag,1
je @F
mov cx,1000h
@@:
loop @B // B 这里是Before的意思
是不是既方便,又美观?!
当用@@做标号时,@F表示本条指令后的第一个@@标号,@B表示本条指令前的第一个@@标号,注意,当程序中可以有多个@@标号,@B和@F只寻找匹配最近的一个。
不要在间隔太远的代码中使用@@标号,因为在以后的修改中@@和@B,@F中间可能会被无意中插入一个新的@@,这样一来,@B或@F就会引用到错误的地方去,距离最好限制在编辑器能够显示的同一屏幕的范围内。
变量 -- 全局变量
全局变量的定义
全局变量的作用域是整个程序,Win32汇编的全局变量定义在.data 或.data? 段内,可以同时定义变量的类型和长度,格式如:
变量名 类型 初始值1, 初始值2,…
变量名 类型 重复数量 dup (初始值1,初始值2,…)
MASM中可以定义的变量类型相当多,也很实在,都是表达占地多少?!

注意:所有使用到变量类型的情况中,只有定义全局变量的时候类型才可以用缩写!
【举例】
.data
wHour dw ? ;例1
wMinute dw 10 ;例2
_hWnd dd ? ;例3
word_Buffer dw 100 dup (1,2) ;例4
szBuffer byte 1024 dup (?) ;例5
szText db ‘Hello,world!’ ;例6
在byte类型变量的定义中,可以用引号定义字符串和数值定义的方法混用。
假设要定义两个字符串Hello,World! 和 Hello again,每个字符串后面中回车和换行符,最后以一个0字符结尾,可以定义如下:
szText db ‘Hello,World!’, 0dh, 0ah,
’Hello again’, 0dh, 0ah, 0
关于 CR 和 LF
Dos 和 windows采用回车+换行(CR/LF)表示下一行
而UNIX/Linux 采用换行符( LF )表示下一行
苹果机( MAC OS系统 )则采用回车符( CR )表示下一行
CR用符号'
'表示, 十进制ASCII代码是13, 十六进制代码为0x0D
LF使用‘
’符号表示, ASCII代码是10, 十六制为0x0A
全局变量的初始化值
全局变量在定义中既可以指定初值,也可以只用问号预留空间,在.data? 段中,只能用问号预留空间,因为.data? 段中不能指定初始值。
这里就有一个问题:既然可以用问号预留空间,那么在实际运行的时候,这个未初始化的值是随机的还是确定的呢?
答:在全局变量中,这个值就是0,所以用问号指定的全局变量如果要以0为初始值的话,在程序中可以不必为它赋值。
变量 -- 局部变量
局部变量这个名称最早源于高级语言,主要是为了定义一些仅在单个函数里面有用的变量而提出的,使用局部变量能带来一些额外的好处,它使程序的模块化封装变得可能!
试想一下,如果要用到的变量必须定义在程序的数据段里面,假设在一个子程序中要用到一些变量,当把这个子程序移植到别的程序时,除了把代码移过去以外,还必须把变量定义移过去。
而即使把变量定义移过去了,由于这些变量定义在大家都可以用的数据段中,就无法对别的代码保持透明,别的代码有可能有意无意地修改它们
还有,在一个大的工程项目中,存在很多的子程序,所有的子程序要用到的变量全部定义在数据段中,会使数据段变得很大,混在一起的变量也使维护变得非常不方便。
局部变量这个概念出现以后,两个以上子程序都要用到的数据才被定义为全局变量统一放在数据段中,仅在子程序内部使用的变量则放在堆栈中,这样子程序可以编成黑匣子的模样,使程序的模块结构更加分明。
局部变量的作用域是单个子程序,在进入子程序的时候,通过修改堆栈指针esp来预留出需要的空间,在用ret指令返回主程序之前,同样通过恢复esp丢弃这些空间,这些变量就随之无效了。
用C反汇编举例演示!
局部变量的缺点就是因为空间是临时分配的,所以无法定义含有初始化值的变量,对局部变量的初始化一般在子程序中由指令完成。
全局变量的内存分配是静态的,局部变量的内存分配是动态的,这句话我们现在是否有了真正的理解?!
局部变量的定义
MASM用local伪指令提供了对局部变量的支持。定义的格式是:
local 变量名1 [[重复数量]] [:类型], 变量名2 [[重复数量]] [:类型] ……
local伪指令必须紧接在子程序定义的伪指令proc后、其他指令开始前,这是因为局部变量的数目必须在子程序开始的时候就确定下来系统才知道怎么分配,在一个local语句定义不下的时候,可以有多个local语句,语法中的数据类型不能用缩写。
Win32汇编默认的类型是dword,如果定义dword类型的局部变量,则类型可以省略。
当定义数组的时候,可以[]括号起来。不能使用定义全局变量的dup伪指令。
局部变量不能和已定义的全局变量同名。
局部变量的作用域是当前子程序,所以在不同的子程序中可以有同名的局部变量。
定义局部变量的例子:
local loc1[1024]:byte ;例1
local loc2 ;例2
local loc3:WNDCLASS ;例3
例1定义了一个1024字节长的局部变量loc1
例2定义了一个名为loc2的局部变量,类型是默认值dword
例3定义了一个WNDCLASS数据结构,名为loc3
局部变量的使用
TestProc proc ;名为TestProc的子程序
local @loc1:dword, @loc2:word
local @loc3:byte ;用local语句定义了3个变量
mov eax, @loc1 ;对应类型进行存储,然后返回
mov ax, @loc2
mov al, @loc3
ret
TestProc endp
我们来看看它反汇编之后是什么样子的:
:00401000 55 push ebp
:00401001 8BEC mov ebp, esp
:00401003 83C4F8 add esp, FFFFFFF8
:00401006 8B45FC mov eax, dword ptr [ebp-04]
:00401009 668B45FA mov ax, word ptr [ebp-06]
:0040100D 8A45F9 mov al, byte ptr [ebp-07]
:00401010 C9 leave
:00401011 C3 ret
可以看到,反汇编后的指令比源程序多了前后两段指令,它们是:
:00401000 55 push ebp
:00401001 8BEC mov ebp, esp
:00401003 83C4F8 add esp, FFFFFFF8
:00401010 C9 leave
这些就是使用局部变量所必需的指令,分别用于局部变量的准备工作和扫尾工作。
【分析过程】
当调用者执行了call TestProc指令后,CPU把返回的地址(当前地址)压入堆栈,再转移(jmp)到子程序执行。
esp在程序的执行过程中可能随时用到,不可能用esp来随时存取局部变量,ebp寄存器(可以理解为小三)是以堆栈段为默认数据段的,所以,可以用ebp做指针指向堆栈替代esp。
于是,在初始化前,先用一句push ebp指令把原来的ebp保存起来,然后把esp的值放到ebp中。
(介绍局部变量怎么腾出空间的)再后面就是堆栈中预留空间了,由于堆栈是向下增长的。所以要在esp中加一个负值,FFFFFFF8就是-8。

我们来考虑另一个问题:一个dword加一个word加一个byte不是7吗,为什么刚刚我们在堆栈为局部变量让出了8个字节的空间呢?
这是因为在80386处理器中,以dword (32位)为界对齐时存取内存速度最快,所以MASM宁可浪费一个字节,执行了这3句指令后,初始化完成,就可以进行正常的操作了,从指令中可以看出局部变量在堆栈中的位置排列。
在程序退出的时候,必须把正确的esp设置回去,否则,ret指令会从堆栈中取出错误的地址返回,看程序可以发现,ebp就是正确的esp值,因为子程序开始的时候已经有一句mov ebp,esp,所以要返回的时候只要先mov esp,ebp,然后再pop ebp,堆栈就是正确的了。
在80386指令集中有一条指令可以在一句中实现这些功能,就是leave指令,所以,编译器在ret指令之前只使用了一句leave指令。
明白了局部变量使用的原理,就很容易理解使用时的注意点:ebp寄存器是关键(第一次听说小三是关键)
因为它起到保存原始esp的作用,并随时用做存取局部变量的指针基址,所以在任何时刻,不要尝试把ebp用于别的用途,否则会带来意想不到的后果。(在任何时候不要做对不起小三的事情,不然后果很严重 T_T)
闲言碎语
Win32汇编中局部变量的使用方法可以解释一个很有趣的现象:在DOS汇编的时候,如果在子程序中的push指令和pop指令不配对,那么返回的时候ret指令从堆栈里得到的肯定是错误的返回地址,程序也就死掉了。但在Win32汇编中,push指令和pop指令不配对可能在逻辑上产生错误,却不会影响子程序正常返回,原因就是在返回的时候esp不是靠相同数量的push和pop指令来保持一致的,而是靠leave指令从保存在ebp中的原始值中取回来的,也就是说,即使把esp改得一塌糊涂也不会影响到子程序的返回,当然,窍门就在ebp,把ebp改掉,程序就玩完了!
局部变量的初始化值
显然,局部变量是无法在定义的时候指定初始化值的,因为local伪指令只是简单地把空间给留出来,那么开始使用时它里面是什么值呢?
和全局变量不一样,局部变量的初始值是随机的,是其他子程序执行后在堆栈里留下的垃圾(因为我们知道,腾出空间只是改变栈指针esp),所以,对局部变量的值一定要初始化,特别是定义为结构后当参数传递给API函数的时候。
在API函数使用的大量数据结构中,往往用0做默认值,如果用局部变量定义数据结构,初始化时只定义了其中的一些字段,那么其余字段的当前值可以是编程者预想不到的数值,传给API函数后,执行的结果可能是意想不到的,这是初学者很容易忽略的一个问题。所以最好的办法是:在赋值前首先将整个数据结构填0,然后再初始化要用的字段,这样其余的字段就不必一个个地去填0了,RtlZeroMemory这个API函数就是实现填0的功能的。
变量的使用
接着上一节的话题,我们继续谈变量,书本原本的数据结构我们后边介绍。
这个话题有点像C语言中的数据类型强制转换,C语言中的类型转换指的是把一个变量的内容转换成另外一种类型,转换过程中,数据的内容已经发生了变化,如把浮点数转换成整数后,小数点后的内容就丢失了。在MASM中以不同的类型访问不会对变量造成影响。
例如,以db方式定义一个缓冲区:
szBuffer db 1024 dup (?)
然后 mov ax,szBuffer
编译器会报一个错:
error A2070: invalid instruction operands
意思是无效的指令操作,为什么呢?因为szBuffer是用db定义的,而ax的尺寸是一个word,等于两个字节,尺寸不符合。
在MASM中,如果要用指定类型之外的长度访问变量,必须显式地指出要访问的长度,这样编译器忽略语法上的长度检验,仅使用变量的地址。
使用的方法是: 类型 ptr 变量名
类型可以是byte, word, dword, fword, qword, real8和real10。
如:
mov ax, word ptr szBuffer
mov eax, dword ptr szBuffer
在这里要注意的是,指定类型的参数访问并不会去检测长度是否溢出,看下面一段代码:
.data
bTest1 db 12h
wTest2 dw 1234h
dwTest3 dd 12345678h
……
.code
mov al, bTest1
mov ax, word ptr bTest1
mov eax, dword ptr bTest1
……
上面的程序片断,每一句执行后寄存器中的值是什么呢?
mov al, bTest1 这一句很显然使 al 等于 12h,下面的两句呢,ax 和 eax难道等于 0012h 和00000012h吗?
实际运行结果是 3412h 和 78123412h,为什么呢?(DOS汇编基础不错的同学,应该能理解)
因为:在内存中的存放顺序是:12 34 12 78 56 34 12
所以说呢,刚才这个例子说明了汇编中用ptr强制覆盖变量长度的时候,实质上是只用了变量的地址而禁止编译器进行检验。
编译器并不会考虑定界的问题,程序员在使用的时候必须对内存中的数据排列有个全局概念,以免越界存取到意料之外的数据。
如果程序员的本意是类似于C语言的强制类型转换,想把bTest1的一个字节扩展到一个字或一个双字再放到ax 或 eax中,高位保持0而不是越界存取到其他的变量,要肿么办呢?
80386处理器提供的 movzx 指令可以实现这个功能,例如:
movzx ax,bTest1 ; ax == 0012h
movzx eax,bTest1 ; eax == 00000012h
movzx eax,cl ; eax == 000000(cl)
movzx eax,ax ; eax == 0000(ax)
用movzx指令进行数据长度扩展是Win32汇编中经常用到的技巧。
变量的尺寸和数量
在源程序中用到变量的尺寸和数量的时候,可以用sizeof和lengthof伪指令来实现,格式是:
sizeof 变量名、数据类型或数据结构名
lengthof 变量名
他们的区别是:sizeof 伪指令可以取得变量、数据类型或数据结构以字节为单位的长度,然而 lengthof 则可以取得变量中数据的项数。
stWndClass WNDCLASS <>
szHello db ‘Hello,world!’,0
dwTest dd 1,2,3,4
……
.code
……
mov eax, sizeof stWndClass
mov ebx, sizeof WNDCLASS
mov ecx, sizeof szHello
mov edx, sizeof dword
mov esi, sizeof dwTest
执行后eax 的值是stWndClass 结构的长度:40
ebx同样是:40
ecx的值是Hello,world! 字符串的长度加上一个字节的0结束符:13
edx的值是一个双字的长度:4
esi等于4个双字的长度:16
如果把所有的sizeof 换成 lengthof,那么eax会等于1,因为只定义了1项WNDCLASS
而ecx同样等于13
esi则等于4
lenghof WNDCLASST 和 lengthof dword 是非法的用法,编译程序会报错。
要注意的是,sizeof 和lengthof 的数值是编译时产生的,由编译器传递到指令中去,上边的指令最后产生的代码就是:
mov eax, 40
mov ebx, 40
mov ecx, 13
mov edx, 4
mov esi, 16
如果为了把Hello和World分两行定义,szHello是这样定义的:
szHello db ‘Hello’, odh, oah
db ‘World’, 0
那么 sizeof szHello 是多少呢?
注意!是7,而不是13。MASM 中的变量定义只认一行,后一行db ‘World’, 0 实际上是另一个没有名称的数据定义,编译器认为sizeof szHello 是第一行字符的数量。(尝试一下)
虽然把 szHello 的地址当参数传给 MessageBox 等函数显示时会把两行都显示出来,但严格地说这是越界使用变量。
虽然在实际的应用中这样定义长字符串的用法很普遍,因为如果要显示一屏幕帮助,一行是不够的。
但要注意的是:要用到这种字符串的长度时,千万不要用 sizeof 去表示,最好是在程序中用lstrlen 函数去计算。
获取变量地址
获取变量地址的操作对于全局变量和局部变量是不同的。
对于全局变量,它的地址在编译的时候已经由编译器确定了,它的用法大家都不陌生:
mov 寄存器, offset 变量名
其中offset 是取变量地址的伪操作符,和sizeof伪操作符一样,它仅把变量的地址带到指令中去,这个操作是在编译时而不是在运行时完成的。
对于局部变量,它是用 ebp 来做指针操作的,假设 ebp 的值是 40100h,那么第一个局部变量的地址是 ebp – 4 即 400FCh。
由于 ebp 的值随着程序的执行环境不同可能是不同的,所以局部变量的地址值在编译的时候也是不确定的,不可能用 offset 伪操作符来获取它的地址。
强调:offset 伪操作符是在编译的时候将变量替换为地址。
80386处理器中有一条指令用来取指针的地址,就是lea指令,如:lea eax, [ebp-4]
该指令可以在运行时按照 ebp 的值实际计算出地址放到 eax 中。
如果要在 invoke 伪指令的参数中用到一个局部变量的地址,该怎么办呢?参数中是不可能写入lea指令的,用offset又是不对的。
MASM对此有一个专用的伪操作符addr,其格式为: addr 局部变量名 或 全局变量名
当 addr 后跟全局变量名的时候,用法和 offset是相同的;
当addr后面跟局部变量名的时候,编译器自动用lea指令先把地址取到 eax 中,然后用 eax 来代替变量地址使用。
注意addr伪操作符只能在invoke的参数中使用,不能用在类似于下列的场合:
mov eax, addr 局部变量名 ;注意:错误用法
原理进一步解析
假设在一个子程序中有如下invoke指令:
invoke Test, eax, addr szHello
其中 Test 是一个需要两个参数的子程序,szHello 是一个局部变量,会发生什么结果呢?
3、2、1…… Go……
编译器会把invoke伪指令和addr翻译成下面这个模样:
lea eax,[ebp-4]
push eax ;参数2:addr szHello
push eax ;参数1:eax
call Test
发现了什么?到push第一个参数eax之前,eax的值已经被lea eax,[ebp-4]指令覆盖了!
也就是说,要用到的eax的值不再有效,所以,当在invoke中使用addr伪操作符时,注意在它的前面不能用eax,否则eax的值会被覆盖掉,当然eax在addr的后面的参数中用是可以的。
MASM编译器对这种情况有如下错误提示:
error A2133:register value overwritten by INVOKE
否则,不知道又会引出多少莫名其妙的错误!所以小甲鱼语录又多了一句:编程就像女人一样 –- 有时候总让你感觉莫名其妙!
使用子程序
当程序中相同功能的一段代码用得比较频繁时,可以将它分离出来写成一个子程序,在主程序中用 call 指令来调用它。
这样可以不用重复写相同的代码,而用 call 指令就可以完成多次同样的工作了。
Win32 汇编中的子程序采用堆栈来传递参数,这样就可以用 invoke 伪指令来进行调用和语法检查工作。
子程序的定义
子程序的定义方式如下所示:
子程序名 proc [距离] [语言类型] [可视区域] [USES寄存器列表] [,参数:类型]…[VARARG]
local 局部变量列表
指令
子程序名 endp
proc 和 endp 伪指令定义了子程序开始和结束的位置,proc 后面跟的参数是子程序的属性和输入参数。
proc 和 endp 伪指令定义了子程序开始和结束的位置,proc 后面跟的参数是子程序的属性和输入参数。
子程序的属性有:
【距离】可以是NEAR,FAR,NEAR16,NEAR32,FAR16 或 FAR32,Win32中只有一个平坦的段,无所谓距离,所以对距离的定义往往忽略。
【语言类型】表示参数的使用方式和堆栈平衡的方式,可以是 StdCall,C,SysCall,BASIC,FORTRAN 和 PASCAL,如果忽略,则使用程序头部.model定义的值。
【可视区域】可以是 PRIVATE,PUBLIC 和EXPORT。PRIVATE 表示子程序只对本模块可见;PUBLIC表示对所有的模块可见(在最后编译链接完成的.exe文件中);EXPORT表示是导出的函数,当编写DLL的时候要将某个函数导出的时候可以这样使用。默认的设置是PUBLIC。
【USES寄存器列表】表示由编译器在子程序指令开始前自动安排 push 这些寄存器的指令,并且在 ret 前自动安排 pop 指令,用于保存执行环境,但笔者认为不如自己在开头和结尾用 pushad 和 popad 指令一次保存和恢复所有寄存器来得方便。
【参数和类型】参数指参数的名称,在定义参数名的时候不能跟全局变量和子程序中的局部变量重名。
对于类型,由于 Win32 中的参数类型只有 32 位(dword)一种类型,所以可以省略。
在参数定义的最后还可以跟 VARARG,表示在已确定的参数后还可以跟多个数量不确定的参数,在Win32 汇编中唯一使用 VARARG 的 API 就是wsprintf,类似于 C 语言中的 printf,其参数的个数取决于要显示的字符串中指定的变量个数。
完成了定义之后,可以用 invoke 伪指令来调用子程序,当 invoke 伪指令位于子程序代码之前的时候,处理到 invoke 语句的时候编译器还没有扫描到子程序定义信息的记录,所以会有以下错误的信息:
error A2006: undefined symbol: _ProcWinMain
学过类似C语言的朋友就会举手说话啦,这个问题其实很简单:不就是没有定义的错误表现嘛~
invoke 伪指令无法得知子程序的定义情况,所以无法进行参数的检测。相当于 没有声明。
在这种情况下,为了让 invoke 指令能正常使用,必须在程序的头部用 proto 伪操作定义子程序的信息。
功能是提前告诉 invoke 语句关于子程序的信息,当然,如果子程序定义在前的话,用 proto 的定义就可以省略了。
由于程序的调试过程中可能常常对一些子程序的参数个数进行调整,为了使它们保持一致,就需要同时修改 proc 语句和 proto 语句。
在写源程序的时候有意识地把子程序的位置提到invoke 语句的前面,省略掉 proto 语句,可以简化程序和避免出错。
因此,我们看到的Win32 汇编代码基本是先写子程序,然后最后才是主程序的。
参数传递和堆栈平衡
我们在了解子程序的定义方法后,接着让我们继续深入了解了程序的使用细节。
原来在调用子程序时,参数的传递是通过堆栈进行的,也就是说,调用者把要传递给子程序的参数压入堆栈,子程序在堆栈中取出相应的值再使用。
比如要调用:SubRouting(Var1, Var2, Var3)
经过编译后的最终代码可能是(注意这里只是可能,具体情况根据不同的环境、约定而定)=>>
我们看到参数是最右边的先入堆栈还是最左边的先入堆栈、还有由调用者还是被调用者来修正堆栈都必须有个约定,不然就会产生错误的结果。
因为有几种不同的约定,所以就是在上述文字中使用“可能”这两个字的原因。
各种语言中调用子程序的约定是不同的,所以在proc以及proto语句的语言属性中确定语言类型后,编译器才可能将invoke伪指令翻译成正确的样子,不同语言的不同点如下
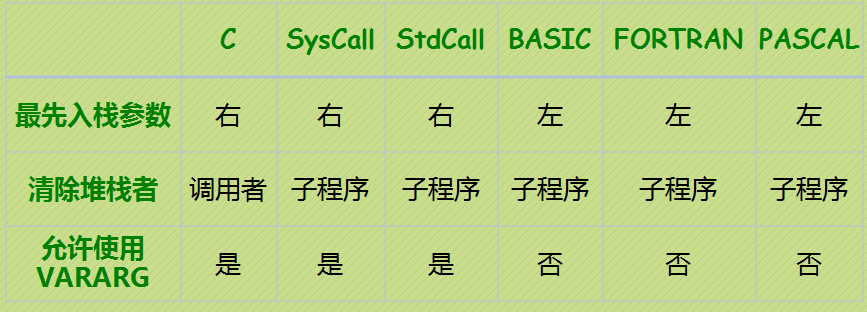
注:VARARG表示参数的个数可以是不确定的,如wsprintf函数,本表中特殊的地方是StdCall的堆栈清除平时是由子程序完成的,但使用VARARG时是由调用者清除的。
我们来反汇编一个程序看下我们都学习了些什么:Example & Disassembly
我们发现,虽然是完成一样的功能,但是实现的方式各不相同,所谓殊途同归。
Win32约定的类型是StdCall,所以在程序中调用子程序或系统API后,不必自己来平衡堆栈,免去了很多麻烦。