看了很多网上关于weblogic t3协议解析,基本没人好好分析。
先说一下为什么要分析T3协议,主要是受朋友所托使用python模拟调用T3协议。目前的weblogic T3攻击工具,大体都是java或者python等编写,有两大特点:
- java 编写的攻击工具一般集成weblogic的t3.jar,攻击者通过反序列化漏洞造成的任意代码执行向weblogic安装一个T3实例,攻击者调用这个实例去完成回显等复杂操作。
- python等语言编写的工具为了实现weblogic反序列化攻击,一般直接替换weblogic t3流中
aced 0005部分实现反序列化攻击。这种方式的缺点在于无法完成T3协议的交互,导致无法回显等弊端。
而网上关于weblogic t3协议根本搜索不到任何相关信息,因为T3协议是oracle独有的,非开源协议。如果要是分析T3协议,只能对着weblogic 的源码,静态分析加动态调试。只知道T3也称为丰富套接字,是BEA内部协议,功能丰富,可扩展性好。T3是多工双向和异步协议,经过高度优化,只使用一个套接字和一条线程。借助这种方法,基于Java的客户端可以根据服务器方需求使用多种RMI对象,但仍使用一个套接字和一条线程。这也为我们静态分析t3协议带来了很多麻烦
T3的交互过程如下
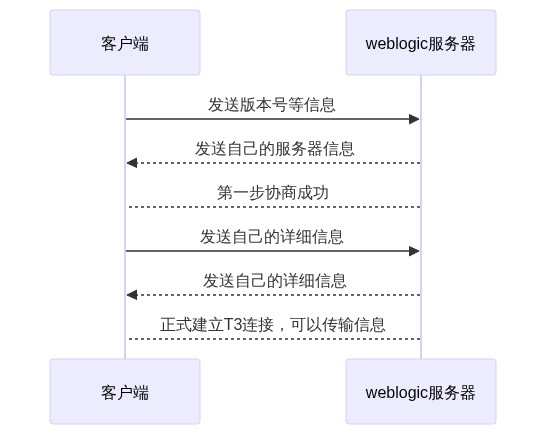
协议协商
客户端首先发送下面的信息给weblogic服务器
t3 10.3.6
AS:255
HL:19
表明这是一个T3协议,而服务器接收到信息后,也会回复类似的消息。
HELO:12.2.1.4.false
AS:2048
HL:19
MS:10000000
PN:DOMAIN
代码分析有点复杂,这里不再赘述,只讲重点。
客户端通过下面的代码发起socket请求
weblogic.rjvm.t3.MuxableSocketT3#connect(java.net.InetAddress, int, int)

服务端则在weblogic.rjvm.t3.MuxableSocketT3#readIncomingConnectionBootstrapMessage处理T3的启动。当然,每个头的含义可以在weblogic.rjvm.MsgAbbrevJVMConnection找到详细的定义。

一般而言,AS与HL头比较常见,下面重点说一下这两个头
- HL头,标识自己后面发起的t3的协议头长度。
- AS头,因为T3的反序列化使用了一个特别的数据结构Stack,AS头用来标识这个stack的容量,这个与T3协议反序列化分隔符
FFFE0001相关。现在我们先不理会这个头的具体含义
通信双方根据对方发来的协议协商信息,开始建立连接
T3协议分析
再协商完毕上面的信息后,由客户端向服务端发送自己的详细信息,这个叫peerinfo。从这里开始就全部是二进制流了,变得不可读。我们需要开始分析T3协议的每个bytes
每个T3协议前4位bytes标识本次请求的数据长度,这个没什么好说的
在weblogic.rjvm.MsgAbbrevJVMConnection#dispatch处,解读T3协议流,并处理

T3协议头处理
我们首先看一下协议头是怎么被处理的
相关代码在weblogic.rjvm.MsgAbbrevInputStream#init中。首先调用readHeader

这些内容加在一起正好是19字节,也就是上一阶段协商中HL的内容。每个字段的含义如下,因为我也是通过逆向分析得到的结果,有些可能不太准确。
cmd
表明本次请求的类型。请求类型一共有十余种,值分别如下

其中,T3交互peerInfo初始化,类型为CMD_IDENTIFY_REQUEST,执行rebind lookup等操作,cmd类型为CMD_REQUEST。t3也支持c#调用
flags
标志位
responseId
这个头的作用为标识每条流的请求顺序,是自增的,初始值为-1。一般而言,服务端的responseId设置与客户端在本次请求的responseId值相同,这个字段有点类似于tcp 的syn。相关代码如图

invokeableId
这个字段比较重要。客户端将根据这个字段的值去查找响应的处理程序。t3与java rmi不同之处在于,java rmi协议在客户端的lookup查找对象中返回该对象的动态代理。t3返回一个数字代表该对象。后续操作中,设置invokeableId为该对象代表的数字,完成rpc调用。
如果客户端执行的是rebind,交换彼此信息,lookup操作,则 invokeableId为9。不要问我为什么,wlc就这样设计的。具体有哪些invokeableid,可以在OIDManager中查看。
当然,如果是响应,这种情况下invokeableId将不再重要。weblogic一般设置为与responseid相同。

abbrevOffset
abbrev这个数据结构在本次请求中相对于开始部分的偏移
T3 Abbrev 处理
读取完头信息后,开始读取MsgAbbrevs。这个数据结构我不能很好的描述它,因为T3协议并没有全部实现java反序列化协议,而是自己由魔改了一部分。比如readClassDescriptor的class部分,T3协议在abbrevs中读取。这个后面将会讲到,现在你不理解也无所谓
这里将会跳转到abbrevOffset标识的部分并开始读取数据。代码如下
void read(MsgAbbrevInputStream in, BubblingAbbrever at) throws IOException, ClassNotFoundException {
int numAbbrevs = in.readLength();
for(int i = 0; i < numAbbrevs; ++i) {
int abbrev = in.readLength();
Object o;
if (abbrev > at.getCapacity()) {
o = this.readObject(in);
at.getAbbrev(o);
this.abbrevs.push(o);
} else {
o = at.getValue(abbrev);
this.abbrevs.push(o);
}
}
}
首先读取msgAbbrev的数量。然后再读取length,如果length大于本次T3请求中存放abbrev的容量,则读取对象,否则读取值。而本次T3请求的abbrev的容量,就是由前面协议协商的AS标识的值,默认为255。
下面我们看一下简化后的readLength代码。这里我用python重写一遍,反编译的代码可读性很差,相关代码在
weblogic.utils.io.ChunkedDataInputStream#readLength

而客户端中,如果需要写入对象,则直接写入256,也就是FE01。
服务端调用readObject的代码如下

而一般来说,在协商T3协议部分中,交换的信息有限,所以这部分将会weblogic.rjvm.JVMID weblogic.rjvm.ClassTableEntry weblogic.rjvm.ImmutableServiceContext 组成。
这里很好地解释了网上流传的内容

T3 Context处理
读取完上面的内容后,开始读取context

这部分主要内容是在例如rebind,lookup请求中,恢复请求上下文。T3协议是不分rebind等请求的,在最终处理阶段由调用方法,也就是context去区分。
T3 协议内容处理
T3 协议在建立之初交换彼此的详细信息,这部分被称为PeerInfo。t3协议内容没有具体定义,由被调用的方法参数类型决定
CMD_IDENTIFY_REQUEST
这个就是交换信息时的cmd头。也就是1,响应则为2。
具体处理代码在
weblogic.rjvm.ConnectionManagerServer#handleIdentifyRequest
协议体的具体内容如下

从这里可以看出,其实在每条T3流中,ACED标识前面也是反序列化流,只不过修改起来比较复杂罢了。
CMD_REQUEST
客户端在执行rebind,lookup操作以及调用实例等操作,cmd都为CMD_REQUEST。服务端只能通过invokeadbleId去区分客户端的具体操作。具体代码在weblogic.rjvm.RJVMImpl#dispatchRequest中

rid可用的列表如下

最终将请求包装为线程调用
rmi指令
这种指令用来绑定,查找实例,这种操作的invokeableId为9。不要问我为什么,weblogic 就只这样设计的
客户端的代码

服务端最终调用weblogic.jndi.internal.RootNamingNode_WLSkel#invoke(int, weblogic.rmi.spi.InboundRequest, weblogic.rmi.spi.OutboundResponse, java.lang.Object)
去处理每个具体的请求。在这里每一个case都对应rmi的一种操作。例如lookup对应16

这里将会读取t3协议体内容,处理完成后返回。
lookup操作,最终返回这个实例所代表的rid
实例操作
回到rid处理部分,在这里查找到rid所代表的实例处理后,分发并处理。例如我现在通过weblogic的反序列化漏洞安装一个实例后,通过lookup查找,该实例的rid为295。处理程序如下

CMD_ONE_WAY
这种请求与上面类似,只不过不需要向客户端显示执行后的结果。

T3内存马的构想
前面我们说过,目前T3协议的反序列化攻击回显大多数都是通过反序列化漏洞绑定一个实例。例如我的攻击程序代码如下

绑定完成后,客户端再通过lookup查找该实例去调用,实现T3的后门。但是这种攻击方式有一个弊端在于很容易被发现,管理员可以通过查看weblogic的jndi树去判断是否被植入基于t3协议的后门。
当然,分析一遍T3协议的处理方式,有助于我们发现新的乐趣
T3的CMD_REQUEST请求,包装为线程后,最终由weblogic.rmi.internal.BasicServerRef#handleRequest去处理

代码如上所述,这里存在一个preInvoke,在权限校验之前。这个东西类似于java web的Filter功能。

在这里我们只需要向commonInterceptors插入一个自定义的拦截器,即可实现t3版本的内存马。
这种方法的缺点: 需要实现一个T3协议,不过好在了解协议后,重写一个就十分方便了。
后面将分享一下python模拟调用T3的相关代码