几天前偶尔看到有人发帖子问“如何自动识别判断url中的中文参数是GB2312还是Utf-8编码”
也拜读了wcwtitxu使用巨牛的正则表达式检测UTF8编码的算法。
使用无数或条件的正则表达式用起来却是性能不高。
刚好曾经在项目中有类似的需求,这里把处理思路和整理后的源代码贴出来供大家参考
先聊聊原理:
UTF8的编码规则如下表
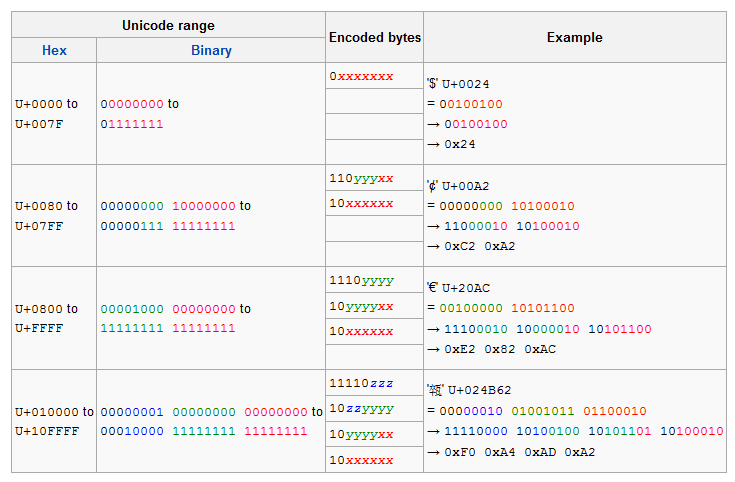
看起来很复杂,总结起来如下:
ASCII码(U+0000 - U+007F),不编码
其余编码规则为
•第一个Byte二进制以形式为n个1紧跟个0 (n >= 2), 0后面的位数用来存储真正的字符编码,n的个数说明了这个多Byte字节组字节数(包括第一个Byte)
•结下来会有n个以10开头的Byte,后6个bit存储真正的字符编码。
因此对整个编码byte流进行分析可以得出是否是UTF8编码的判断。
根据这个规则,我给出的C#代码如下:
/// <summary>
/// Determines whether the given <paramref name="inputStream"/>is UTF8 encoding bytes.
/// </summary>
/// <param name="inputStream">
/// The input stream.
/// </param>
/// <returns>
/// <see langword="true"/> if given bystes stream is in UTF8 encoding; otherwise, <see langword="false"/>.
/// </returns>
/// <remarks>
/// All ASCII chars will regards not UTF8 encoding.
/// </remarks>
public static bool IsTextUTF8(ref byte[] inputStream)
{
int encodingBytesCount = 0;
bool allTextsAreASCIIChars = true;
for (int i = 0; i < inputStream.Length; i++)
{
byte current = inputStream[i];
if ((current & 0x80) == 0x80)
{
allTextsAreASCIIChars = false;
}
// First byte
if (encodingBytesCount == 0)
{
if ((current & 0x80) == 0)
{
// ASCII chars, from 0x00-0x7F
continue;
}
if ((current & 0xC0) == 0xC0)
{
encodingBytesCount = 1;
current <<= 2;
// More than two bytes used to encoding a unicode char.
// Calculate the real length.
while ((current & 0x80) == 0x80)
{
current <<= 1;
encodingBytesCount++;
}
}
else
{
// Invalid bits structure for UTF8 encoding rule.
return false;
}
}
else
{
// Following bytes, must start with 10.
if ((current & 0xC0) == 0x80)
{
encodingBytesCount--;
}
else
{
// Invalid bits structure for UTF8 encoding rule.
return false;
}
}
}
if (encodingBytesCount != 0)
{
// Invalid bits structure for UTF8 encoding rule.
// Wrong following bytes count.
return false;
}
// Although UTF8 supports encoding for ASCII chars, we regard as a input stream, whose contents are all ASCII as default encoding.
return !allTextsAreASCIIChars;
}
再附上单元测试代码:
/// <summary>
///This is a test class for EncodingHelperTest and is intended
///to contain all EncodingHelperTest Unit Tests
///</summary>
[TestClass()]
public class EncodingHelperTest
{
/// <summary>
/// Normal test for this method.
///</summary>
[TestMethod()]
public void IsTextUTF8Test()
{
for (int i = 0; i < 1000; i++)
{
List<Char> chars = new List<char>();
chars.Add('中');
List<UnicodeCategory> temp = new List<UnicodeCategory>();
Random rd = new Random((int)(DateTime.Now.Ticks & 0x7FFFFFFF));
for (int j = 0; j < 255; j++)
{
char ch = (char)rd.Next(0xFFFF);
UnicodeCategory uc = System.Globalization.CharUnicodeInfo.GetUnicodeCategory(ch);
if (uc == UnicodeCategory.Surrogate || // Single surrogate could not be encoding correctly.
uc == UnicodeCategory.PrivateUse || // Private use blocks should be excluded.
uc == UnicodeCategory.OtherNotAssigned
)
{
j--;
}
else
{
chars.Add(ch);
temp.Add(uc);
}
}
string str = new string(chars.ToArray());
byte[] inputStream = Encoding.UTF8.GetBytes(str);
bool expected = true;
bool actual;
actual = EncodingHelper.IsTextUTF8(ref inputStream);
Assert.AreEqual(expected, actual, string.Format("UTF8_Assert Fails at:{0}", str));
inputStream = Encoding.GetEncoding(932).GetBytes(str);
expected = false;
actual = EncodingHelper.IsTextUTF8(ref inputStream);
Assert.AreEqual(expected, actual, string.Format("ShiftJIS_Assert Fails at:{0}", str));
}
}
/// <summary>
/// Check with All ASCII chars
/// </summary>
[TestMethod]
public void IsTextUTF8Test_AllASCII()
{
string str = "ABCDEFGHKLHSJKLDFHJKLHAJKLSHJKLHAJKLSHDJKLAHSDJKLHAJKLSDHJKLASHDJKLHASJKLDHJKLASD";
byte[] inputStream = Encoding.UTF8.GetBytes(str);
bool expected = false;
bool actual;
actual = EncodingHelper.IsTextUTF8(ref inputStream);
Assert.AreEqual(expected, actual, string.Format("UTF8_Assert Fails at:{0}", str));
}
}
另:
如果是判断一个文件是否使用了UTF8编码,不一定非用这种方法,因为通常以UTF8格式保存的文件最初两个字符是BOM头,标示该文件使用了UTF8编码。
参考: