1. INFO

Title: SMASH: One-Shot Model Architecture Search through HyperNetworks
Author: Andrew Brock, Theodore Lim, & J.M. Ritchie
Link: https://arxiv.org/pdf/1708.05344.pdf
Date: ICLR 2018 Poster
Code:https://github.com/ajbrock/SMASH
2. Motivation
高性能的深度神经网络需要大量工程设计,而网络的细节比如深度、连接方式等往往遵从了一些网络设计规则,比如ResNet,Inception,FractalNets,DenseNets等。但即便在这些规则的指导下,也需要设计一系列实验来决定网络具体的配置,如深度,通道数等。
SMASH就是为了越过这个昂贵的训练候选模型的过程而提出来的,通过使用辅助网络生成权重来解决这个问题。
3. Contribution
SMASH通过引入HyperNet来根据候选网络的结构动态生成权重。
虽然通过辅助网络生成候选网络权重的方式得到的验证集精度不高,但是不同候选网络结果的表现和从头训练候选网络的表现具有相对一致性,所以可以作为挑选候选网络的指导。
搜索网络的设计使用了基于内存读写的灵活机制(memory read-write),从而定义了一个包括ResNet、DenseNet、FractalNets的搜索空间。
SMASH也有局限性:这个方法不能自己发现全新的结构,因为他只能动态生成模型参数的特定子集。
4. Method
SMASH的伪代码如下:

- 首先设计所有候选网络的搜索空间。
- 初始化超网权重H
- 对于一个batch的数据x,一个随机的候选网络c,和根据候选网络架构的生成的权重W=H(c)
- 得到loss,进行反向传播,并更新H
- 以上完成以后,就得到了一个训练完成的HyperNet。
- 采样随机的候选网络c,在验证集上得到验证loss,找到loss最小的候选网络。
- 对得到的候选网络进行从头训练,得到在验证机上的精度。
对于以上过程,有几个点需要搞清楚:
- 候选网络搜索空间是如何构建的?
- 如何根据候选网络架构得到权重?
4.1 候选网络搜索空间
对于第一个问题,从内存读写的角度来考虑采样复杂、带分支的拓扑,并将该拓扑编码为二进制特征向量。
普通的网络是从前向传播-反向传播信号的角度来设计的,这篇文章从内存的读写角度来看待网络结构,被称为Memory-Bank representation。
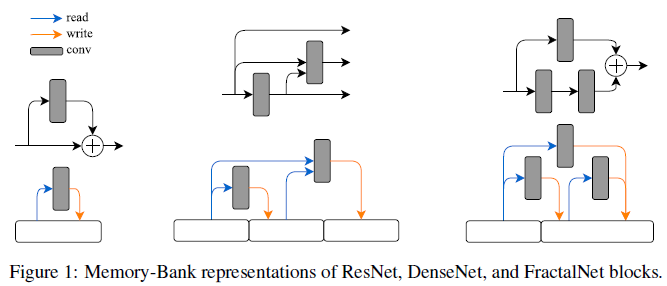
从这个角度,每个层就代表一个从内存中一部分读取数据的操作,比如左边的是resnet示意图,从内存中读取数据x,经过conv处理,得到conv(x),然后写到内存中x+conv(x)结果。中间的图展示的是DenseNet,回顾DenseNet,在每个block内部中,每个节点都和之前的所有节点相连接。

那么在Memory-Bank的表示方法中,以3个节点为例:
- 从第一块内存读取数据x
- 通过第一个conv1,得到conv1(x),并写回第二块内存。
- 从第二块内存读取conv1(x),经过第二个conv2,得到conv2(conv1(x))
- 从第一块内存读取x,经过第二个conv2,得到conv2(x)
- 两者concate到一起写回第三块内存concat(conv2(conv1(x)), conv2(x))
SMASH采用的网络结构和以上三种网络类似,由多个block组成,其中降采样部分使用的是1x1卷积,分辨率减半。其中全连接层和1x1卷积权重是通过学习得到的,不是通过HyperNet生成的。
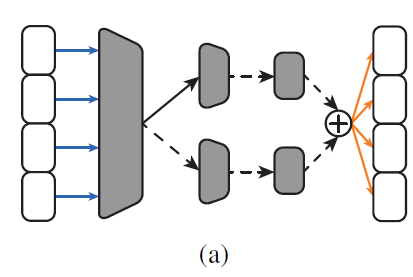
下图展示的是一个op的结构,一个1x1卷积在memory-bank上的操作,后边跟着最多两条卷积路径。左侧第一个灰色梯形代表1x1conv,用于调整channel个数,然后不同的分支代表选择不同类型的卷积。
在采样网络的过程中,每个block内部的memory bank的个数是随机的,每个memory-bank的channel个数也是随机的。block中的层随机选择读写模型以及相对应op。
当读入read了多个memory-bank, 在channel维度进行concat,写入write是将每个memory-bank中的结果相加。
实验中,op仅允许读取所属block的memory-bank。op有1x1卷积、若干常规卷积、非线性激活函数。
4.2 为给定网络生成权重
SMASH中提出的Dynamic Hypernet是基于网络结构c得到对应的权重W。
优化的目标是学习一个映射W=H(c)能够对任意一个架构c来说,H(c)能够尽可能接近最优的W。
HyperNet是一个全卷积组成的网络,所以其输出的张量W随着输入网络结构c的变化而变化,其标准的形式是4D的 BCHW,其中B=1。
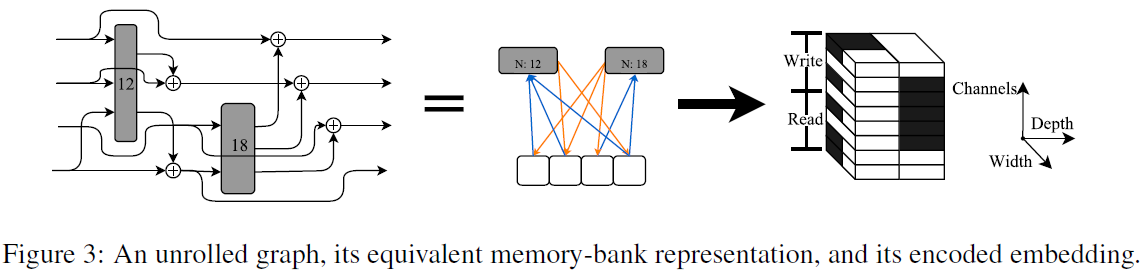
举个例子,如果op从第1,2,4个memory-bank中读取,然后写回第2,4个memory-bank。那么第1,2,4个通道对应的值被赋值为1(代表read模式,如上图所示),第6(2+4),8(4+4)个通道被赋值为1(代表write模式)。通过以上方式得到了对网络结构的编码。
通过以上例子,终于搞清楚了如何从memory-bank的角度来表征网络结构,剩下生成W权重的工作采用的是MLP来完成的。
5. Experiment
实验部分需要验证声明Claim:
- 通过HyperNet生成权重W的这种方式具有较好的排序一致性。
- 证明SMASH方法的有效性,架构表征c在整个算法中是否真正起到了作用。
- 验证算法的可扩展性,使用迁移学习的方法来证明。
- 和其他SOTA方法进行比较
5.1 测试SMASH的相关性
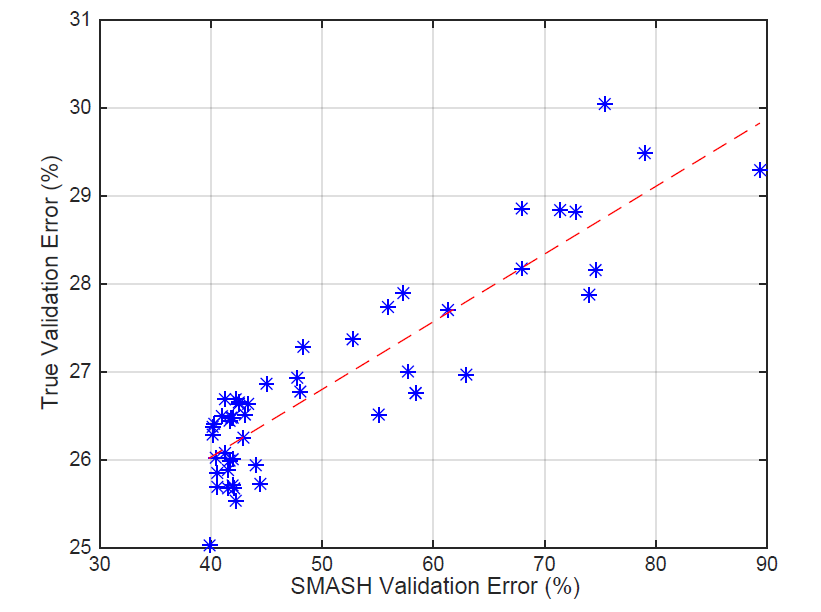
横坐标是HyperNet生成权重得到的验证集错误率,纵坐标代表模型真实训练得到的验证集错误率,红色线代表使用最小二乘法得到的结果。
根据这根线就得到了一致性?相当于使用目测的方法得到结论,感觉可以用统计学的方法计算出置信度,或者来计算一下kendall tau或者Person系数能更好的反映结果。
作者在说明这个结果的时候也很有意思:这个实验结果只能表明在当前设置的实验场景下是满足相关性的,但既不能保证相关性的通用性,也不能保证相关性成立的条件。由于实验代价过高,无法进一步得到结果。
所以需要第二个实验来辅助,设计一个代理模型,其中的模型权重相比于正常的SMASH要小很多,减少了实验代价。
而第三个实验,提出了更高预算的网络(因为参数量不够的情况下,模型表现会很差,为了和SOTA比较,所以需要提高预算),但是实验发现其SMASH分数和真实性能并不相关。发现了SMASH中存在的缺陷。
5.2 使用Proxy进一步证明SMASH有效性
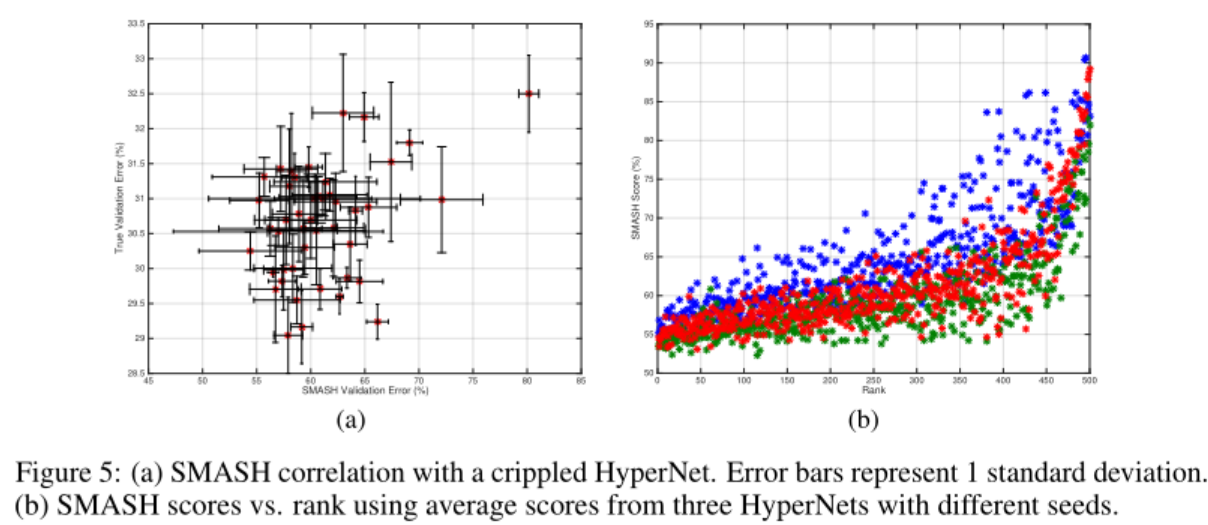
左图展示的是低预算情况下SMASH,并不存在明确的相关性。这说明在模型容量比较小的情况下,HyperNet很难学到良好的权值,导致SMASH得分和真实性能之前没有明确的相关性。
通过破坏网络架构表示c,发现对于给定的网络架构,使用正确的网络架构表示所能生成的SMASH验证性能是最高的,证明了网络架构表示的有效性。
5.3 迁移学习
作者发现这种算法搜出来的模型具有很好的可迁移性:CIFAR-100上搜出来的模型在STL-10上表现优于直接在STL-10上搜的模型。原因可能是CIFAR-100拥有更多的训练样例,能够使HyperNet更好地选择模型架构。
5.4 SOTA比较
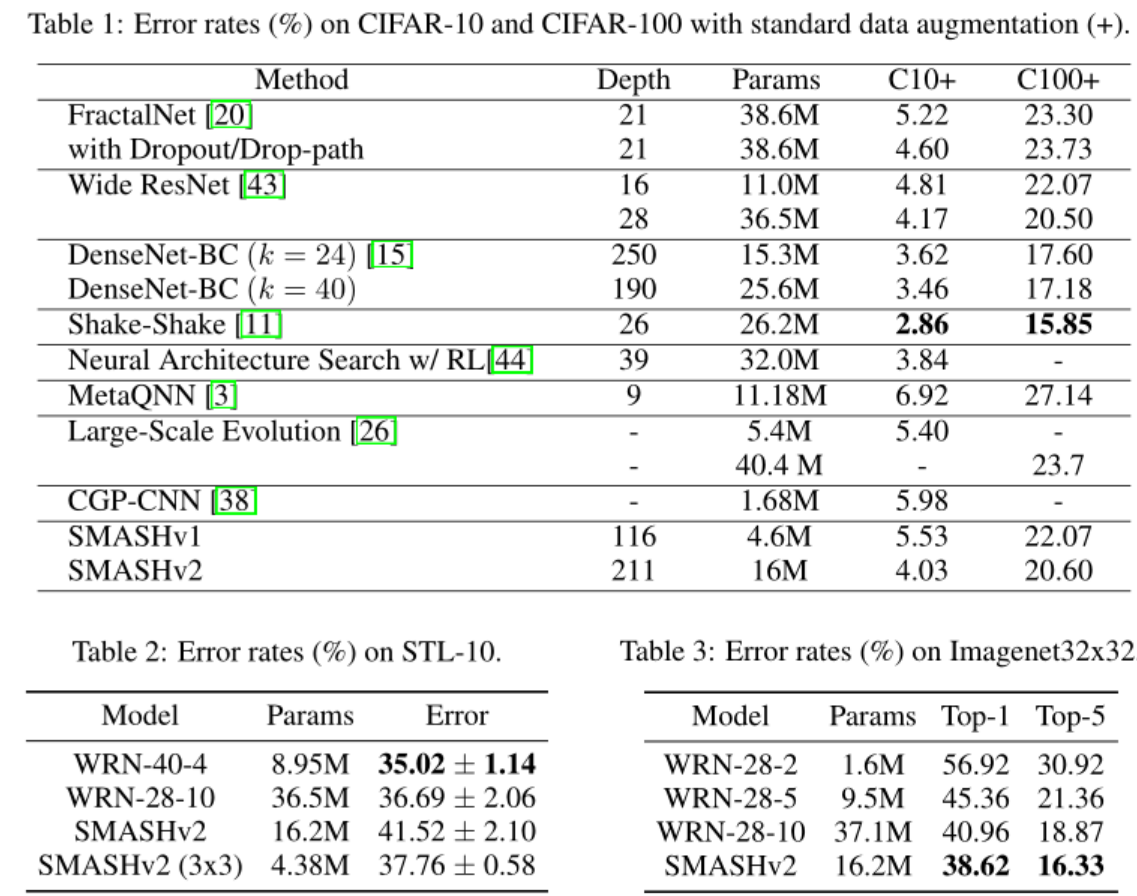
可以看到,SMASH的结果并没有达到SOTA,处于中等水平,但是总体上优于其他RL-based和进化算法。确实是比不上NASNet,但是SMASH并没有像NASNet一样进行了超参数网格搜索。
6. Revisiting
这篇文章读下来花费了好长时间,总结一下这篇奇怪的文章:
- 提出了HyperNet生成网络权重的想法,输入是网络架构表示,输出是网络的权重。并提出一个前提:HyperNet生成权重后的网络和真实训练的网络的性能具有相关性。
- 提出了一种从memory-bank角度来看待网络的方法,相比普通的前向反向传播角度,一开始比较难以接受。
- 从memory-bank角度提出了比较复杂的网络的编码方式,用于表达网络架构c。
- 使用MLP实现HyperNet,输出得到网络的权重。
想法:从个人角度出发,这篇文章想法很奇特,直接生成网络的权重。个人也是很佩服作者的工程能力,生成网络权重,并让整个模型work需要多大的工程量不必多言。作者也在文章中透露了各种不work的方式,不断地调整,比如使用weightNorm等来解决收敛问题。调整网络的容量来想办法尽可能提高网络的性能表现,最终能在cifar10上得到96%的top1已经很不容易了。
这个也给了我们启发,即便是并没有达到SOTA,这个创新的想法、扎实的工作也可以被顶会接收。
最后作者开源了源码,并且给源码附上了详细的注释。
7. Reference
https://arxiv.org/pdf/1608.06993.pdf