转载博客:https://www.cnblogs.com/luoyj/p/12515018.html#4526065
A*搜索算法详解:
A*算法的技术可以概况为:A*算法 = 贪心最优搜索 + BFS + 优先队列。
在图问题中,“Dijkstra + 优先队列”就是“BFS + 优先队列”,此时也可以概况为:“A算法 = 贪心最优搜索 + Dijkstra + 优先队列”。
下面以图的最短路径问题为例,推理出A算法的原理。
注意,除了图这种应用场合,A*算法还能在更多场合下得到应用。
贪心最优搜索:
贪心最优搜索(Greedy Best First Search )是一种启发式搜索,效率很高,但是得到的解不一定是最优的。
算法的基本思路就是贪心:从起点出发,在它的邻居结点中选择下一个结点时,挑那个到终点最近的结点。当然,实际上不可能提前知道结点到终点的距离,更不用说挑选出最近的邻居点了。所以,只能采用估计的方法,例如在网格图中,根据曼哈顿距离来估算邻
居
结点到终点的距离。
如何编程?仍然用“BFS + 优先队列”,不过,在优先队列中排序的,不是从起点s到当前点i的距离,而是从当前点i到终点t的距离。
很明显,贪心最优搜索避开了大量结点,只挑那些“好”结点,速度极快,但是显然得到的路径不一定最优。
在无障碍的网格图中,贪心最优搜索算法的结果是最优解。因为用于估算的曼哈顿距离就是实际存在的最短路,所以每次找到的下一个结点,显然是最优的。
在有障碍的网格图中,根据曼哈顿距离选下一跳结点,路线会一直走到碰壁,然后再绕路,最后得到的不一定是最短路径。
贪心搜索的算法思想是:“只看终点,不管起点”。走一步看一步,不回头重新选择,走错了也不改正。而且,用曼哈顿距离这种简单的估算,也不能提前绕开障碍。
贪心最优搜索的图解,见下面“1.5 三种算法对比”。
Dijkstra(BFS)
用优先队列实现的Dijkstra(BFS) ,能比较高效地求得一个起点到所有其他点的最短路径。Dijkstra算法有BFS的通病:下一步的搜索是盲目的,没有方向感。即使给定了终点,Dijkstra也需把几乎所有的点和边放进优先队列进行处理,直到优先队列弹出终点
为
止。所以它适合用来求一个起点到所有其他结点的最优路径,而不是只求到一个终点的路径。
Dijkstra的算法思想是:“只看起点,不管终点”。等遍历得差不多了,总会碰到终点的。
Dijkstra的图解,见下面“1.5 三种算法对比”。
A*算法的原理和复杂度
A算法是贪心最优搜索和Dijkstra的结合,“既看起点,又看终点”。它比Dijkstra快,因为它不像Dijkstra一样盲目;它有贪心搜索的预测能力,而且能得到最优解。
它是如何结合这两个算法的?
设起点是s,终点是t,算法走到当前位置i点,把s-t的路径分为两部分:s-i-t。
1)s-i的路径,由Dijkstra保证最优性;
2)i-t的路径,由贪心搜索进行预测,选择i的下一个结点;
3)当走到i碰壁时,i将被丢弃,并回退到上一层重新选择新的点j,j仍由Dijkstra保证最优性。
以上思路可以用一个估价函数来具体操作:
f(i) = g(i) + h(i)
f(i)是对i点的评估,g(i)是从s到k的代价,h(i)是从k到t的代价。
若g = 0,则f = h,A就退化为贪心搜索;
若h = 0,则f = g,A就退化为Dijkstra。
A每次根据最小的f(i)来选择下一个点。 g(i)是已经走过的路径,是已知的;h(i)是预测未走过的路径;所以f(i)的性能取决于h(i)的计算。
A*算法的复杂度,在最差情况下的上界是Dijkstra,或者BFS+队列,一般情况下会更优。
A*算法的最优性
A算法的解是最优的吗?答案是确定的,它的解和Dijkstra的解一样,是最短路径。
当k到达终点t时,有h(t) = 0,那么f(t) = g(t) + h(t) = g(t),而g(t)是通过Dijkstra求得的最优解,所以在终点t这个位置,A算法的解是最优的。
总结:A*算法通过Dijkstra获得最优性结果;通过贪心最优搜索预测扩展方向,减少搜索的结点数量。
三种算法对比
下面这张图 ,准确地说明了三种算法的区别。图中起点是s,终点是t,黑格是障碍。图中精心设置了障碍的位置,以演示三种算法是如何绕过障碍的。
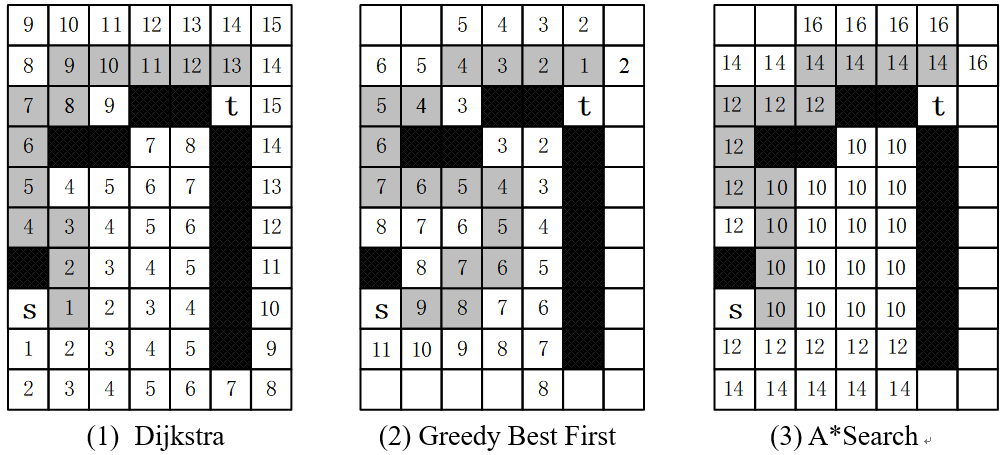
图1 三种算法对比
三个算法都基于"BFS+优先队列"。有数字的格子是搜索过的结点,并进入优先队列处理。阴影格是最后得到的一条完整路径。格子中的数字是距离,按曼哈顿距离计算。Dijkstra(BFS)算法遍历的格子最多,贪心最优搜索算法遍历的格子最少。
1)Dijkstra(BFS)算法。格子中的数字,是从起点s到这个格子的最短距离。算法搜索格子时,把这些格子到起点的距离送入优先队列,当弹出时,就得到了s到这些格子的最短路径。最后,当终点t从优先队列弹出时,即得到s到t的最短距离14。
2)贪心最优搜索。格子中的数字,是从这个格子到终点t的曼哈顿距离。读者可以仔细分析它的工作过程,这里简单说明如下:从s沿最小曼哈顿距离,一直走到碰壁处的2;2从优先队列弹出后,剩下最小的是3;3弹出后,剩下最小的是4;......;持续这个过 程,那些看起来更近但是最终碰壁的结点被逐个弹走,直到拐过障碍,最后到达t。得到的路径不是最优路径。
3)A搜索。例如格子i中的数字,是“s到i的最短路 + i到t的曼哈顿距离”。算法在扩展格子的过程中,标记数字的格子都会进入优先队列。在图示中,先弹出所有标记为10的格子,再弹出标记为12的格子,直到最后弹出终点t。最后得到的s-t最短路径也是14。
如何打印出完整的一条路径?三个算法都基于BFS,而BFS记录路径是非常简单的:在结点u扩展邻居点v的时候,在v上记录它的前驱结点u,即可以从v回溯到u;到达目的后,从终点逐步回溯到起点,就得到了路径。在Dijkstra算法中,每次从优先队列中弹出的,都是得到了最短路径的结点,从它们扩展出来的邻居结点,也会继续形成最短路径,所以能根据前驱和后继结点的关系,方便地打印出一条完整的最短路径 [如果需要打印出最短路径,参考《算法竞赛入门到进阶》“10.9 最短路”,给出了路径打印的代码]。A算法用Dijkstra算法来确定前驱后继的关系,也一样可以打印出一条最短路径。贪心最优搜索的路径打印最简单,就是普通BFS的路径打印。
函数h的设计
在二维平面上,有3种方法可以近似计算h。下面的(i.x, i.y)是i点的坐标,(t.x, t.y)是终点t的坐标。
1)曼哈顿距离。应用场景:只能在四个方向(上,下,左,右)移动。
h(i) = abs (i.x – t.x) + abs (i.y – t.y)
2)对角线距离。应用场景:可以在八个方向上移动,例如国际象棋的国王的移动。
h(i) = max {abs(i.x – t.x), abs(i.y – t.y)}
3)欧几里得距离。应用场景:可以向任何方向移动。
h(i) = sqrt ( (i.x – t.x)2 + (i.y – t.y)2 )
非平面问题,需要设计合适的h函数,后面的例题中有一些比较复杂的h函数。
设计h时注意以下基本规则:
1)g和h应该用同样的计算方法。例如h是曼哈顿距离,g也应该是曼哈顿距离。如果计算方法不同,f = g + h就没有意义了。
2)根据应用情况正确选择h。各个结点的h值,应该能正确反映它们到终点的距离远近。例如下一跳结点有2个选项:A(280, 319)、B(300, 300),如果用曼哈顿距离应该选A,用欧氏距离应该选B。如果只能走四个方向(需要按曼哈顿距离计算路径),用欧式距
离计算就会出错。
3)h应该优于实际存在的所有路径。前面的例子中,h(i)小于等于i-t的所有可能路径长度,也就是说,最后得到的实际路径,长度大于h(i)。这个规则可以用下面两点讨论来说明。
1)h(i)比i-t的实际存在的最优路径长。假设这条实际的最优路径是path,由于程序是根据h(i)来扩展下一个结点的,所以很可能会放弃path,而选择另一条非最优的路径,这会造成错误。
2)h(i)比i-t的所有实际存在的路径都短。此时i-t上并不存在一条长度为h(i)的路径,如果程序根据h(i)来扩展下一结点,最后肯定会碰壁;但是不要紧,程序会利用BFS的队列操作弹走这些错误的点,退回到合适的结点,从而扩展出实际的路径,所以仍能保证正确性。
上面第(3)点最重要,应用A*算法时应特别注意。
A*算法例子
A*算法的主要难点是设计合适的h函数,而编码很容易。例如图问题中,Dijkstra或BFS使用g函数,A*使用f = g + h函数,那么编码时只要用f代替g即可。读者可以尝试把图论的最短路径题目改成用A*算法实现,例如[poj 2243](http://poj.org/problem?id=2243)。
下面给出2个复杂一点的例题。
K短路
问题描述[poj 2249](http://poj.org/problem?id=2449) :给定一个图,定义起点s和终点t,以及数字k;求s到t的第k短的路。允许环路。相同长度的不同路径,也被认为是完全不同的。
下面分别用暴力法和A*算法求解。
1)暴力法:BFS + 优先队列
用BFS搜索所有的路径,用优先队列让路径按从短到长的顺序输出。
“BFS+优先队列”求最短路,在“BFS+优先队列”这一节中曾讲解过。其原理是当再次扩展到某个点i时,如果这次的新路径比上次到达i的路径更短,就替代它;优点队列可以让结点按路径长短先后输出,从而保证最优性。队列的元素是一个二元组(i, dist(s-i)),即结点i和路径s-i的长度。
BFS求所有路径,就是最简单的“BFS + 优先队列”,再次扩展邻居i时,计算它到s的距离,然后直接进队列,并不与上次i进队列的情况进行比较。一个结点i会进入优先队列很多次,因为可以从它的多个邻居分别走过来;每一次代表了一个从s到i的路径。优先队列可以让这些路径按dist从短到长的顺序输出,i从优先队列中第x次弹出,就是s到i的第x个短路。对于终点t,统计它出队列的次数,第K次时停止,这就是第K短路。
在K短路问题中,路径有可能形成环路。有的题目允许环路,有的不允许。如果允许环路,那么想在环路上绕多少圈都可以,环路上的结点反复进入队列,K可以无限大。 在最短路算法中并不需要判断环路,因为更新操作有去掉环路的隐含作用。
复杂度:因暴力法需要生成几乎所有的路径,而路径数量是指数增长的,所以暴力法的复杂度非常高。
下面用一个简单的图例解释BFS暴力搜索所有路径的过程。
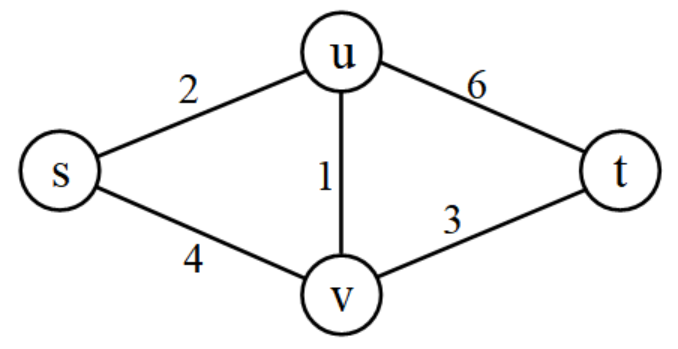
图2 一个简单图
下面的表格给出了算法的步骤。结点后面的下标表示从s到这个结点的路径长度,例如u2u2,就是二元组(u, 2),即结点u,以及s-u的路径长度2。步骤中没有列出环路。
| 步骤 | 出队 | 邻居进队 | 优先队列 | 新得到的路径 | 输出队头的路径 | |
|---|---|---|---|---|---|---|
| 1 | ss | {s0s0} | ||||
| 2 | s0s0 | u,v | {u2,v4u2,v4} | {ss-u2u2, ss-v4v4} | ||
| 3 | u2u2 | v,tv,t | v3,v4,t8v3,v4,t8 | {ss-u2u2-v3v3,ss-u2u2-t8t8} | ss-u2u2 | |
| 4 | v3v3 | tt | {v4,t8,t6v4,t8,t6} | ss-u2u2-v3v3-t6t6 | ss-u2u2-v3v3 | |
| 5 | v4v4 | u,tu,t | {t8,t6,u5,t7t8,t6,u5,t7} | ss-v4v4-u5u5, ss-v4v4-t7t7 | ss-v4v4 | |
| 6 | u5u5 | tt | {t8,t6,t7,t11t8,t6,t7,t11} | ss-v4v4-u5u5-t11t11 | ss-v4v4-u5u5 | |
| 7 | t6t6 | {t8,t7,t11t8,t7,t11} | ss-u2u2-v3v3-t6t6 | |||
| 8 | t7t7 | uu | {t8,t11,u13t8,t11,u13} | ss-v4v4-t7t7-u13u13 | ss-v4v4-t7t7 | |
| 9 | t8t8 | vv | {t11,u13,v11t11,u13,v11} | ss-u2u2-t8t8-v11v11 | ss-u2u2-t8t8 | |
| 10 | t11t11 | {u13,v11u13,v11} | ss-v4v4-u5u5−t11−t11 | |||
| 11 | v11v11 | {u13u13} | ss-u2u2-t8t8-v11v11 | |||
| 12 | u13u13 | {} | ss-v4v4-t7t7-u13u13 |
从第二列的“出队”可以看到,共产生10个路径,按从短到长的顺序排队输出。从起点s到终点t共有4条路径,t在第7、8、9、10步出队的时候,输出了第1、第2、第3、第4路径。表格中也列出了s到每个结点的多个路径和它们的长度,例如s-u有3个路径,s-v有3个路径。
2)A*算法求K短路
从暴力法可以知道:
1)从优先队列弹出的顺序,是按这些结点到s的距离排序的。
2)一个结点i从优先队列第x次弹出,就是s-i的第x短路;终点t从队列中第K次弹出,就是s-t的第K短路。
如何优化暴力法?是否可以套用A*算法?
联想前面讲解A*算法求最短路的例子,A*算法的估价函数f(i) = g(i) + h(i),g是从起点s到i的距离,h是i到终点t的最短距离(例子中是曼哈顿距离)。
那么在K短路问题中,可以设计几乎一样的估价函数。g(i)仍然是起点s到i的距离;而h(i),只是把曼哈顿距离改为从i到t的最短距离。这个最短距离如何求?用Dijkstra算法,以终点t为起点,求所有结点到t的最短距离即可。
编程非常简单。仍用暴力法的“BFS+优先队列”,但是在优先队列中,用于计算的不再是g(i),而是f(i)。当终点t第K次弹出队列时,就是第K短路。
根据前面对A*算法原理的解释,求K短路的过程将得到很大优化。虽然在最差情况下,算法复杂度的上界仍是暴力法的复杂度,但优化是很明显的。
poj 1945
Power Hungry Cows http://poj.org/problem?id=1945
**题目描述**:两个变量a、b,初始值a = 1, b = 0。每一步可以执行一次a×2,b×2,a+b,|a-b|之一的操作,并把结果再存回a或者b。问最快多少步能得到一个整数P,1 <= P <= 20,000。
例如P = 31,需要6步:
a b
初始值: 1 0
a×2,存到b: 1 2
b×2: 1 4
b×2: 1 8
b×2: 1 16
b×2: 1 32
b-a: 1 31
样例输入:
31
样例输出:
6
--------------------------------------------------------------
**题解**:
1)BFS+剪枝
这一题是典型的BFS。从{a, b}可以转移到8种情况,即{2a, a}、{2a, b}、{2b,a}、{2b,b}等等。把每种{a, b}看成一个状态,那么1个状态可以转移到8个状态。编码时,再加上去重和剪枝。此题P不是太大,“BFS+剪枝”可行。
2)A*算法
如何设计估价函数f(i) = g(i) + h(i) ?
g(i)是从初始态到i状态的步数。h(i)是从i状态到终点的预估最少步数,它应该小于实际的步数。如何设计呢?容易观察到,{a, b}中的较大数,一直乘以2递增,是最快的。例如样例中的31,在起点状态,2525 > 31,经5步可以超过目标值,所以h = 5。
一些习题
下面的题目有多种实现方法,尝试用A*算法来做。
洛谷P1379 八数码难题,https://www.luogu.com.cn/problem/P1379。八数码有多种解法,A*也是经典解法之一。
洛谷 2324 骑士精神,https://www.luogu.com.cn/problem/P2324
洛谷P2901 Cow Jogging https://www.luogu.com.cn/problem/P2901,K短路。