Asp.net,它就是一个底层框架平台,它负责接收HTTP请求(从IIS传入),将请求分配给一个线程, 再把请求放到它的处理管道中,由一些其它的【管道事件订阅者】来处理它们,最后将处理结果返回给客户端。 而WebForms或者MVC框架,都属于Asp.net平台上的【管道事件订阅者】而已,Web Service也是哦。如果你不想受限于WebForms或者MVC框架, 或者您还想用Asp.net做点其它的事情,比如:自己的服务框架,就像WebService那样。 但希望用其它更简单的序列化方式来减少网络流量,或者还有加密要求。 那么了解Asp.net提供了哪些功能就很有必要了。Asp.net负责接收请求,并将请求分配给一个线程来执行。最终执行什么呢?当然就是我们的处理逻辑。 但我们在处理时,用户输入的数据又是从哪里来的呢?只能是HTTP请求。但它又可分为二个部分:请求头和请求体。 在Asp.net中,我们并不需要去分析请求头和请求体,比如:我们可以直接访问QueryString,Form就可以得到用户传过来的数据了, 然而QueryString其实是放在请求头上,在请求头上的还有Cookie,Form;PostFile则放在请求体中。
在我的看来,Asp.net有三大核心对象:HttpContext, HttpRequest, HttpResponse。除此之外,还有二个仍然比较重要:HttpRuntime,HttpServerUtility
今天我按照从轻到重的排序来分析:
HttpRuntime
HttpRuntime,其实这个对象算是整个Asp.net平台最核心的对象,从名字可以看出它的份量。 但它包含的很多方法都不是public类型的,它在整个请求的处理过程中,做了许多默默无闻但非常重要的工作。 反而公开的东西并不多,因此需要我们掌握的东西也较少。
HttpRuntime公开了一个静态方法 UnloadAppDomain() ,这个方法可以让我们用代码重新启动网站。 通常用于用户通过程序界面修改了一个比较重要的参数,这时需要重启程序了。
HttpRuntime还公开了一个大家都熟知的静态属性 Cache 。可能有些人认为在使用Page.Cache或者HttpContext.Cache, 事实上后二个属性都是HttpRuntime.Cache的【快捷方式】。HttpRuntime.Cache是个非常强大的东西,主要用于缓存一些数据对象, 提高程序性能。虽然缓存实现方式比较多,一个static变量也算是能起到缓存的作用,但HttpRuntime.Cache的功能绝不仅限于一个简单的缓存集合, 如果说实现“缓存项的滑动过期和绝对过期”算是小儿科的话,缓存依赖的功能应该可以算是个强大的特性吧。 更有意义的是:它缓存的内容还可以在操作系统内存不足时能将一些缓存项释放(可指定优先级),从而获得那些对象的内存,并能在移除这些缓项时能通知您的代码。 可能有人认为当内存不足时自动释放一些缓存对象容易啊,使用WeakReference类来包装一下就可以了。但WeakReference不提供移除时的通知功能。
这里我还想说说缓存依赖。我曾经见过一个使用场景:有人从一堆文件(分为若干类别)中加载数据到Cache中, 但是他为了想在这些数据文件修改时能重新加载,而采用创建线程并轮询文件的最后修改时间的方式来实现,总共开了60多个线程,那些线程每隔15去检查各自所“管辖”的文件是否已修改。 如果您也是这样处理的,我今天就告诉您:真的没必要这么复杂,您只要在添加缓存项时创建一个CacheDependency的实例并调用相应的重载方法就可以了。具体CacheDependency有哪些参数, 您还是参考一下MSDN吧。这里我只告诉您:它能在一个文件或者目录,或者多个文件在修改时,自动通知Cache将缓存项清除, 而且还可以设置到依赖其它的缓存项,甚至能将这些依赖关系组合使用,非常强大。
可能还有人会担心往Cache里放入太多的东西会不会影响性能,因此有人还想到控制缓存数量的办法。我只想说: 缓存容器决定一个对象的保存位置是使用Hash算法的,并不会因为缓存项变多而影响性能,更有趣的是Asp.net的Cache的容器还并非只有一个, 它能随着CPU的数量而调整,看这个架式,应该在设计Cache时还想到了高并发访问的性能问题。 如果这时你还在统计缓存数量并手工释放某些缓存项,我只能说您在写损害性能的代码。
HttpServerUtility , HttpUtility
由于HttpServerUtility的实例通常以Server的属性公开, 但它的提供一些Encode, Decode方法其实调用的是HttpUtility类的静态方法。所以我就把它们俩一起来说了。
HttpUtility公开了一些静态方法,如:
HtmlEncode(),应该是使用频率比较高的方法,用于防止注入攻击,它负责安全地生成一段HTML代码。
有时我们还需要生成一个URL,那么UrlEncode()方法就能派上用场了,因为URL中并不能包含所有字符,所以要做相应的编码。
HttpUtility还有一个方法HtmlAttributeEncode(),它也是用于防止注入攻击,安全地输出一个HTML属性。
在.net4中,HttpUtility还提供了另一个方法:JavaScriptStringEncode(),也是为了防止注入攻击,安全地在服务端输出一段JS代码。
HttpUtility还公开了一些静态方法,如:
HtmlDecode(), UrlDecode(),通常来说,我们并不需要使用它们。尤其是UrlDecode ,除非您要自己的框架,一般来说, 在我们访问QueryString, Form时,已经做过UrlDecode了,您就不用再去调用了。
HttpServerUtility除了公开了比较常用的Encode, Decode方法外,还公开了一个非常有用的方法:Execute(),是的,它非常有用, 尤其是您需要在服务端获取一个页面或者用户控件的HTML输出时。
HttpRequest
第一个核心对象出场了。MSDN给它作了一个简短的解释:“使 ASP.NET 能够读取客户端在 Web 请求期间发送的 HTTP 值。”
这个解释还算是到位的。HttpRequest的实例包含了所有来自客户端的所有数据,我们可以把这些数据看成是输入数据, Handler以及Module就相当于是处理过程,HttpResponse就是输出了。
在HttpRequest包含的所有输入数据中,有我们经常使用的QueryString, Form, Cookie,它还允许我们访问一些HTTP请求头、 浏览器的相关信息、请求映射的相关文件路径、URL详细信息、请求的方法、请求是否已经过身份验证,是否为SSL等等。
HttpRequest的公开属性绝大部分都是比较重要的,这里就简单地列举一下吧


// 获取服务器上 ASP.NET 应用程序的虚拟应用程序根路径。 public string ApplicationPath { get; } // 获取应用程序根的虚拟路径,并通过对应用程序根使用波形符 (~) 表示法(例如,以“~/page.aspx”的形式)使该路径成为相对路径。 public string AppRelativeCurrentExecutionFilePath { get; } // 获取或设置有关正在请求的客户端的浏览器功能的信息。 public HttpBrowserCapabilities Browser { get; set; } // 获取客户端发送的 cookie 的集合。 public HttpCookieCollection Cookies { get; } // 获取当前请求的虚拟路径。 public string FilePath { get; } // 获取采用多部分 MIME 格式的由客户端上载的文件的集合。 public HttpFileCollection Files { get; } // 获取或设置在读取当前输入流时要使用的筛选器。 public Stream Filter { get; set; } // 获取窗体变量集合。 public NameValueCollection Form { get; } // 获取 HTTP 头集合。 public NameValueCollection Headers { get; } // 获取客户端使用的 HTTP 数据传输方法(如 GET、POST 或 HEAD)。 public string HttpMethod { get; } // 获取传入的 HTTP 实体主体的内容。 public Stream InputStream { get; } // 获取一个值,该值指示是否验证了请求。 public bool IsAuthenticated { get; } // 获取当前请求的虚拟路径。 public string Path { get; } // 获取 HTTP 查询字符串变量集合。 public NameValueCollection QueryString { get; } // 获取当前请求的原始 URL。 public string RawUrl { get; } // 获取有关当前请求的 URL 的信息。 public Uri Url { get; } // 从 QueryString、Form、Cookies 或 ServerVariables 集合中获取指定的对象。 public string this[string key] { get; } // 将指定的虚拟路径映射到物理路径。 // 参数: virtualPath: 当前请求的虚拟路径(绝对路径或相对路径)。 // 返回结果: 由 virtualPath 指定的服务器物理路径。 public string MapPath(string virtualPath);
下面我来说说一些不被人注意的细节。
HttpRequest的QueryString, Form属性的类型都是NameValueCollection,它个集合类型有一个特点:允许在一个键下存储多个字符串值。
以下代码演示了这个特殊的现象:
protected void Page_Load(object sender, EventArgs e) { string[] allkeys = Request.QueryString.AllKeys; if( allkeys.Length == 0 ) Response.Redirect( Request.RawUrl + "?aa=1&bb=2&cc=3&aa=" + HttpUtility.UrlEncode("5,6,7"), true); StringBuilder sb = new StringBuilder(); foreach( string key in allkeys ) sb.AppendFormat("{0} = {1}<br />", HttpUtility.HtmlEncode(key), HttpUtility.HtmlEncode(Request.QueryString[key])); this.labResult.Text = sb.ToString(); }
页面最终显示结果如下(注意键值为aa的结果):
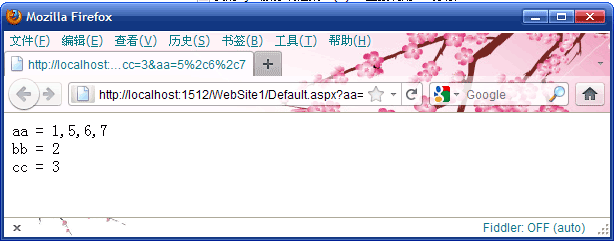
说明:
1. HttpUtility.ParseQueryString(string)这个静态方法能帮助我们解析一个URL字符串,返回的结果也是NameValueCollection类型。
2. NameValueCollection是一个不区分大小写的集合。
HttpRequest有一个Cookies属性,MSDN给它的解释是:“获取客户端发送的 Cookie 的集合。”,这次MSDN的解释就不完全准确了。
请看如下代码:
protected void Page_Load(object sender, EventArgs e) { string key = "Key1"; HttpCookie c = new HttpCookie(key, DateTime.Now.ToString()); Response.Cookies.Add(c); HttpCookie cookie = Request.Cookies[key]; if( cookie != null ) this.labResult.Text = cookie.Value; Response.Cookies.Remove(key); }
这段代码的运行结果就是【能显示当前时间】,我就不贴图了。
如果写成如下形式:
protected void Page_Load(object sender, EventArgs e) { string key = "Key1"; HttpCookie cookie = Request.Cookies[key]; if( cookie != null ) this.labResult.Text = cookie.Value; HttpCookie c = new HttpCookie(key, DateTime.Now.ToString()); Response.Cookies.Add(c); Response.Cookies.Remove(key); }
此时就读不到Cookie了。这也提示我们:Cookie的读写次序可能会影响我们的某些判断。
HttpRequest还有二个用于方便获取HTTP数据的属性Params,Item ,后者是个默认的索引器。
这二个属性都可以让我们方便地根据一个KEY去【同时搜索】QueryString、Form、Cookies 或 ServerVariables这4个集合。 通常如果请求是用GET方法发出的,那我们一般是访问QueryString去获取用户的数据,如果请求是用POST方法提交的, 我们一般使用Form去访问用户提交的表单数据。而使用Params,Item可以让我们在写代码时不必区分是GET还是POST。 这二个属性唯一不同的是:Item是依次访问这4个集合,找到就返回结果,而Params是在访问时,先将4个集合的数据合并到一个新集合(集合不存在时创建), 然后再查找指定的结果。
为了更清楚地演示这们的差别,请看以下示例代码:
<body>
<p>Item结果:<%= this.ItemValue %></p>
<p>Params结果:<%= this.ParamsValue %></p>
<hr />
<form action="<%= Request.RawUrl %>" method="post">
<input type="text" name="name" value="123" />
<input type="submit" value="提交" />
</form>
</body>
public partial class ShowItem : System.Web.UI.Page { protected string ItemValue; protected string ParamsValue; protected void Page_Load(object sender, EventArgs e) { string[] allkeys = Request.QueryString.AllKeys; if( allkeys.Length == 0 ) Response.Redirect("ShowItem.aspx?name=abc", true); ItemValue = Request["name"]; ParamsValue = Request.Params["name"]; } }
页面在未提交前浏览器的显示:
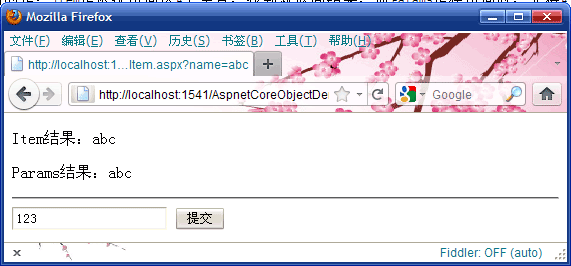
点击提交按钮后,浏览器的显示:

差别很明显,我也不多说了。说下我的建议吧:尽量不要使用Params,不光是上面的结果导致的判断问题, 没必要多创建一个集合出来吧,而且更糟糕的是写Cookie后,也会更新集合。
HttpRequest还有二个很【低调】的属性:InputStream, Filter ,这二位的能量很巨大,却不经常被人用到。
HttpResponse也有这二个对应的属性,本文的后面部分将向您展示它们的强大功能。
HttpResponse
我们处理HTTP请求的最终目的只有一个:向客户端返回结果。而所有需要向客户端返回的操作都要调用HttpResponse的方法。 它提供的功能集中在操作HTTP响应部分,如:响应流,响应头。
我把一些认为很重要的成员简单列举了一下:
// 获取网页的缓存策略(过期时间、保密性、变化子句)。 public HttpCachePolicy Cache { get; } // 获取或设置输出流的 HTTP MIME 类型。默认值为“text/html”。 public string ContentType { get; set; } // 获取响应 Cookie 集合。 public HttpCookieCollection Cookies { get; } // 获取或设置一个包装筛选器对象,该对象用于在传输之前修改 HTTP 实体主体。 public Stream Filter { get; set; } // 启用到输出 Http 内容主体的二进制输出。 public Stream OutputStream { get; } // 获取或设置返回给客户端的输出的 HTTP 状态代码。默认值为 200 (OK)。 public int StatusCode { get; set; } // 将 HTTP 头添加到输出流。 public void AppendHeader(string name, string value); // 将当前所有缓冲的输出发送到客户端,停止该页的执行,并引发EndRequest事件。 public void End(); // 将客户端重定向到新的 URL。指定新的 URL 并指定当前页的执行是否应终止。 public void Redirect(string url, bool endResponse); // 将指定的文件直接写入 HTTP 响应输出流,而不在内存中缓冲该文件。 public void TransmitFile(string filename); // 将 System.Object 写入 HTTP 响应流。 public void Write(object obj);
这些成员都有简单的解释,应该了解它们。
这里请关注一下属性StatusCode。我们经常用JQuery来实现Ajax,比如:使用ajax()函数,虽然你可以设置error回调函数, 但是,极有可能在服务端即使抛黄页了,也不会触发这个回调函数,除非是设置了dataType="json",这时在解析失败时, 才会触发这个回调函数,如果是dataType="html",就算是黄页了,也能【正常显示】。
怎么办?在服务端发生异常不能返回正确结果时,请设置StatusCode属性,比如:Response.StatusCode = 500;
HttpContext
应该可以这么说:有了HttpRequest, HttpResponse分别控制了输入输出,就应该没有更重要的东西了。 但我们用的都是HttpRequest, HttpResponse的实例,它们在哪里创建的呢,哪里保存有它们最原始的引用呢? 答案当然是:HttpContext 。没有老子哪有儿子,就这么个关系。更关键的是:这个老子还很牛,【在任何地方都能找到它】, 而且我前面提到另二个实力不错的选手(HttpServerUtility和Cache),也都是它的手下。 因此,任何事情,找到它就算是有办法了。
不仅如此,在Asp.net的世界,还有黑白二派。Module像个土匪,什么请求都要去“检查”一下,Handler更像白道上的人物, 点名了只做某某事。有趣的是:HttpContext真像个大人物,黑白道的人物有时都要找它帮忙。 帮什么忙呢?可怜的土匪没有仓库,它有东西没地方存放,只能存放在HttpContext那里, 有时惹得Handler也盯上了它,去HttpContext去拿土匪的战利品。
虽然HttpContext也公开了一些属性和方法,但我认为最重要的还是上面提到的那些对象的引用。
这里再补充二个上面没提到的实例属性:User, Items
User属性保存于当前请求的用户身份信息。如果判断当前请求的用户是不是已经过身份认证,可以访问:Request.IsAuthenticated这个实例属性。
前面我在故事中提到:“可怜的土匪没有仓库,它有东西没地方存放,只能存放在HttpContext那里”,其实这些东西就是保存在Items属性中。 这是个字典,因此适合以Key/Value的方式来访问。如果希望在一次请求的过程中保存一些临时数据,那么,这个属性是最理想的存放容器了。 它会在下次请求重新创建,因此,不同的请求之间,数据不会被共享。
如果希望提供一些静态属性,并且,只希望与一次请求关联,那么建议借助HttpContext.Items的实例属性来实现。
我曾经见过有人用ThreadStaticAttribute来实现这个功能,然后在Page.Init事件中去修改那个字段。
哎,MSDN上说:【用 ThreadStaticAttribute 标记的 static 字段不在线程之间共享。每个执行线程都有单独的字段实例,并且独立地设置及获取该字段的值。如果在不同的线程中访问该字段,则该字段将包含不同的值。】 注意了:一个线程可以执行多次请求过程,且Page.Init事件在Asp.net的管道中属于较中间的事件啊,要是请求不使用Page呢,再想想吧。
前面我提到HttpContext有种超能力:【在任何地方都能找到它】,是的,HttpContext有个静态属性Current,你说是不是【在任何地方都能找到它】。 千万别小看这个属性,没有它,HttpContext根本牛不起来。
也正是因为这个属性,在Asp.net的世界里,您可以在任何地方访问Request, Response, Server, Cache, 还能在任何地方将一些与请求有关的临时数据保存起来,这绝对是个非常强大的功能。Module的在不同的事件阶段,以及与Handler的”沟通“有时就通过这个方式来完成。
比如:每个页面使用Session的方式是使用Page指令来说明的,但Session是由SessionStateModule来实现的, SessionStateModule会处理所有的请求,所以,它不知道当前要请求的要如何使用Session,但是,HttpContext提供了一个属性Handler让它们之间有机会沟通,才能处理这个问题。
我再来举个Module自身沟通的例子,就说UrlRoutingModule吧,它订阅了二个事件:
protected virtual void Init(HttpApplication application) { application.PostResolveRequestCache += new EventHandler(this.OnApplicationPostResolveRequestCache); application.PostMapRequestHandler += new EventHandler(this.OnApplicationPostMapRequestHandler); }
在OnApplicationPostResolveRequestCache方法中,最终做了以下调用:
public virtual void PostResolveRequestCache(HttpContextBase context) { // ............... RequestData data2 = new RequestData { OriginalPath = context.Request.Path, HttpHandler = httpHandler }; context.Items[_requestDataKey] = data2; context.RewritePath("~/UrlRouting.axd"); }
再来看看OnApplicationPostMapRequestHandler方法中,最终做了以下调用:
public virtual void PostMapRequestHandler(HttpContextBase context) { RequestData data = (RequestData)context.Items[_requestDataKey]; if( data != null ) { context.RewritePath(data.OriginalPath); context.Handler = data.HttpHandler; } }
看到了吗,HttpContext.Items为Module在不同的事件中保存了临时数据,而且很方便。
HttpContext强大的背后的麻烦事
前面我们看到了HttpContext的强大,而且还提供HttpContext.Current这个静态属性。这样一来,的确是【在任何地方都能找到它】。 想想我们能做什么?我们可以在任何一个类库中都可以访问QueryString, Form,够灵活吧。 我们还可以在任何地方(比如BLL中)调用Response.Redirect()让请求重定向,是不是很强大?
不过,有个很现实的问题摆在面前:到处访问这些对象会让代码很难测试。 原因很简单:在测试时,这些对象没法正常工作,因为HttpRuntime很多幕后的事情还没做,没有运行它们的环境。 是不是很扫兴?没办法,现在的测试水平很难驾驭这些功能强大的对象。
很多人都说WebForms框架搞得代码没法测试,通常也是的确如此。
我看到很多人在页面的CodeFile中写了一大堆的控件操作代码,还混有很多调用业务逻辑的代码, 甚至在类库项目中还中访问QueryString, Cookie。 再加上诸如ViewState, Session这类【有状态】的东西大量使用,这样的代码是很难测试。
换个视角,看看MVC框架为什么说可测试性会好很多,理由很简单, 你很少会需要使用HttpRequest, HttpRespons,从Controller开始,您需要的数据已经给您准备好了,直接用就可以了。 但MVC框架并不能保证写的代码就一定能方便的测试,比如:您继续使用HttpContext.Current.XXXXX而不使用那些HttpXxxxxBase对象。
一般说来,很多人会采用三层或者多层的方式来组织他们的项目代码。此时,如果您希望您的核心代码是可测试的, 并且确实需要使用这些对象,那么应该尽量集中使用这些强大的对象,应该在最靠近UI层的地方去访问它们。 可以把调用业务逻辑的代码再提取到一个单独的层中,比如就叫“服务层”吧, 由服务层去调用下面的BLL(假设BLL的API的粒度较小),服务层由表示层调用, 调用服务层的参数由表示层从HttpRequest中取得。 需要操作Response对象时,比如:重定向这类操作,则应该在表示层中完成。
记住:只有表示层才能访问前面提到的对象,而且要让表示层尽量简单,简单到不需要测试, 真正需要测试的代码(与业务逻辑有关)放在表示层以下。 如此设计,您的表示层将非常简单,以至于不用测试(MVC框架中的View也能包含代码,但也没法测试,是一样的道理)。 甚至,服务层还可以单独部署。
如果您的项目真的采用分层的设计,那么,就应该可以让界面与业务处理分离。比如您可以这样设计:
1. 表示层只处理输入输出的事情,它应该仅负责与用户的交互处理,建议这层代码简单到可以忽略测试。
2. 处理请求由UI层以下的逻辑层来完成,它负责请求的具体实现过程,它的方法参数来自于表示层。
使用InputStream、OutputStream
前面我提到HttpRequest有个InputStream属性, HttpResponse有一个OutputStream属性,它们对应的是输入输出流。 直接使用它们,我们可以非常简单地提供一些服务功能,比如:我希望直接使用JSON格式来请求和应答。 如果采用这种方案来设计,我们只需要定义好输入输出的数据结构,并使用这们来传输数据就好了。 当然了,也有其它的方法能实现,但它们不是本文的主题,我也比较喜欢这种简单又直观地方式来解决某些问题。
比如:1、短信的接口,官方提供几个URL做为服务的地址,调用参数以及返回值就直接通过HTTP请求一起传递。2、目前比较火爆的云服务的调用数据传输;都是直接使用HTTP协议,数据结构有着明确的定义格式,直接随HTTP一起传递。 就这么简单,却非常有用,而且适用性很广,基本上什么语言都能很好地相互调用。
下面我以一个简单的示例演示这二个属性的强大之处。
在示例中,服务端要求数据的输入输出采用JSON格式,服务的功能是一个订单查询功能,输入输出的类型定义如下:
// 查询订单的输入参数 public sealed class QueryOrderCondition { public int? OrderId; public int? CustomerId; public DateTime StartDate; public DateTime EndDate; } // 查询订单的输出参数类型 public sealed class Order { public int OrderID { get; set; } public int CustomerID { get; set; } public string CustomerName { get; set; } public DateTime OrderDate { get; set; } public double SumMoney { get; set; } public string Comment { get; set; } public bool Finished { get; set; } public List<OrderDetail> Detail { get; set; } } public sealed class OrderDetail { public int OrderID { get; set; } public int Quantity { get; set; } public int ProductID { get; set; } public string ProductName { get; set; } public string Unit { get; set; } public double UnitPrice { get; set; } }
服务端的实现:创建一个QueryOrderService.ashx,具体实现代码如下:
public class QueryOrderService : IHttpHandler { public void ProcessRequest(HttpContext context) { context.Response.ContentType = "application/json"; string input = null; JavaScriptSerializer jss = new JavaScriptSerializer(); using( StreamReader sr = new StreamReader(context.Request.InputStream) ) { input = sr.ReadToEnd(); } QueryOrderCondition query = jss.Deserialize<QueryOrderCondition>(input); // 模拟查询过程,这里就直接返回一个列表。 List<Order> list = new List<Order>(); for( int i = 0; i < 10; i++ ) list.Add(DataFactory.CreateRandomOrder()); string json = jss.Serialize(list); context.Response.Write(json); }
代码很简单,经过了以下几个步骤:
1. 从Request.InputStream中读取客户端发送过来的JSON字符串,
2. 反序列化成需要的输入参数,
3. 执行查询订单的操作,生成结果数据,
4. 将结果做JSON序列化,转成字符串,
5. 写入到响应流。
很简单吧,我可以把它看作是一个服务吧,但它没有其它服务框架的种种约束,而且相当灵活, 比如我可以让服务采用GZIP的方式来压缩传输数据:
public void ProcessRequest(HttpContext context) { context.Response.ContentType = "application/json"; string input = null; JavaScriptSerializer jss = new JavaScriptSerializer(); using( GZipStream gzip = new GZipStream(context.Request.InputStream, CompressionMode.Decompress) ) { using( StreamReader sr = new StreamReader(gzip) ) { input = sr.ReadToEnd(); } } QueryOrderCondition query = jss.Deserialize<QueryOrderCondition>(input); // 模拟查询过程,这里就直接返回一个列表。 List<Order> list = new List<Order>(); for( int i = 0; i < 10; i++ ) list.Add(DataFactory.CreateRandomOrder()); string json = jss.Serialize(list); using( GZipStream gzip = new GZipStream(context.Response.OutputStream, CompressionMode.Compress) ) { using( StreamWriter sw = new StreamWriter(gzip) ) { context.Response.AppendHeader("Content-Encoding", "gzip"); sw.Write(json); } } }
修改也很直观,在输入输出的地方,加上Gzip的操作就可以了。
如果您想加密传输内容,也可以在读写之间做相应的处理,或者,想换个序列化方式,也简单,我想您应该懂的。
总之,如何读写数据,全由您来决定。喜欢怎样处理就怎样处理,这就是自由。
不仅如此,我还可以让服务端判断客户端是否要求使用GZIP方式来传输数据,如果客户端要求使用GZIP压缩,服务就自动适应, 最后把结果也做GZIP压缩处理,是不是更酷?
public void ProcessRequest(HttpContext context) { context.Response.ContentType = "application/json"; string input = null; JavaScriptSerializer jss = new JavaScriptSerializer(); bool enableGzip = (context.Request.Headers["Content-Encoding"] == "gzip"); if( enableGzip ) context.Request.Filter = new GZipStream(context.Request.Filter, CompressionMode.Decompress); using( StreamReader sr = new StreamReader(context.Request.InputStream) ) { input = sr.ReadToEnd(); } QueryOrderCondition query = jss.Deserialize<QueryOrderCondition>(input); // 模拟查询过程,这里就直接返回一个列表。 List<Order> list = new List<Order>(); for( int i = 0; i < 10; i++ ) list.Add(DataFactory.CreateRandomOrder()); string json = jss.Serialize(list); if( enableGzip ) { context.Response.Filter = new GZipStream(context.Response.Filter, CompressionMode.Compress); context.Response.AppendHeader("Content-Encoding", "gzip"); } context.Response.Write(json); }
注意:这次我为了不想写二套代码,使用了Request.Filter属性。前面我就说过这是个功能强大的属性。 这个属性实现的效果就是装饰器模式,因此您可以继续对输入输出流进行【装饰】,但是要保证输入和输出的装饰顺序要相反。 所以使用多次装饰后,会把事情搞复杂,因此,建议需要多次装饰时,做个封装可能会好些。 想想:我这几行代码与此服务完全没有关系,而且照这种做法,每个服务都要写一遍,是不是太麻烦了?
bool enableGzip = (context.Request.Headers["Content-Encoding"] == "gzip"); if( enableGzip ) context.Request.Filter = new GZipStream(context.Request.Filter, CompressionMode.Decompress); // ............................................................. if( enableGzip ) { context.Response.Filter = new GZipStream(context.Response.Filter, CompressionMode.Compress); context.Response.AppendHeader("Content-Encoding", "gzip"); }
其实,岂止是这一个地方麻烦。照这种做法,每个服务都要创建一个ahsx文件,读输入,写输出,也是重复劳动。