定义测试的数据大小
#define DATASIZE 100000000
float * fArr = new float[DATASIZE];
for (int i = 0; i < DATASIZE; i++)
{
fArr[i] = i;
}
1、 for代码(常规写法)
for (int i = 0; i < DATASIZE; i++)
{
for (int j = 0; j < 10; j++)
{
fArr[i] = fArr[i] * fArr[i];
}
}
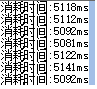 计算时间在5S左右。
2、 用AMP 方式的GPU 技术
#include <amp.h>
using namespace concurrency;
void Square_array(float* arr, int n)
{
array_view<float, 1> dataView(n, &arr[0]);
parallel_for_each(dataView.extent, [=](index<1> idx) restrict(amp)
{
dataView[idx] = dataView[idx] * dataView[idx];
});
// Copy data from GPU to CPU
dataView.synchronize();
}
for (int j = 0; j < 10; j++)
{
Square_array(fArr, DATASIZE);
}
计算时间在5S左右。
2、 用AMP 方式的GPU 技术
#include <amp.h>
using namespace concurrency;
void Square_array(float* arr, int n)
{
array_view<float, 1> dataView(n, &arr[0]);
parallel_for_each(dataView.extent, [=](index<1> idx) restrict(amp)
{
dataView[idx] = dataView[idx] * dataView[idx];
});
// Copy data from GPU to CPU
dataView.synchronize();
}
for (int j = 0; j < 10; j++)
{
Square_array(fArr, DATASIZE);
}
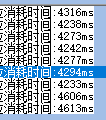 计算时间在4S左右。
3、 用OpenMP 并行技术
启用OpenMP功能
计算时间在4S左右。
3、 用OpenMP 并行技术
启用OpenMP功能
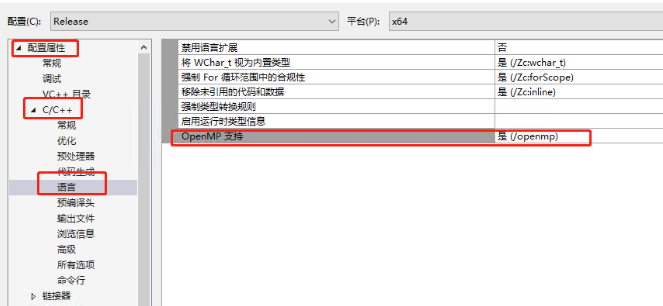 #include<omp.h>
#pragma omp parallel for
for (int i = 0; i < DATASIZE; i++)
{
for (int j = 0; j < 10; j++)
{
fArr[i] = fArr[i] * fArr[i];
}
}
#include<omp.h>
#pragma omp parallel for
for (int i = 0; i < DATASIZE; i++)
{
for (int j = 0; j < 10; j++)
{
fArr[i] = fArr[i] * fArr[i];
}
}
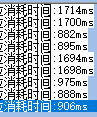 计算时间在800—1800ms 左右
计算时间在800—1800ms 左右
经测试,OPENMP 会带来3-7倍的效率提升。