History in Threads似乎是唯一一个业余项目里有确认用户的. 大部分JavaScript源码(300+行)也用了中文命名.
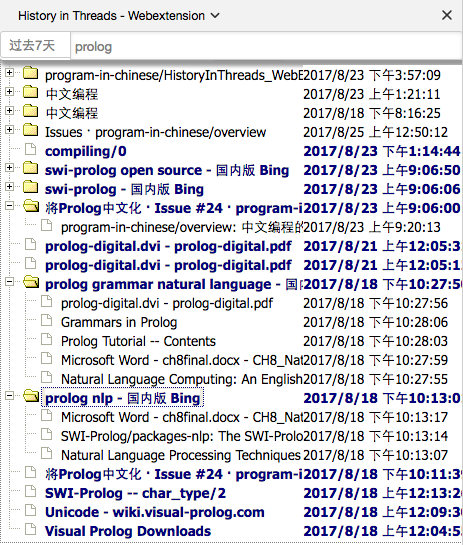
插件功能很简单, 就是根据网页点击顺序生成树, 每个树可以认为是主题相关的. 比如, 从一个B搜索页A点开了其中一个页面B, 显示搜索结果时B就是A的子节点(如下图的"proglog nlp - 国内版 Bing"). 火狐浏览器对页面点击顺序的保存维护好像比Chrome好一些. 生成的树比较完整(相比Chrome版).
最新版的界面很简陋(图源自源码库program-in-chinese/HistoryInThreads_WebExtension):
这个"新版"是由于火狐浏览器旧API失效被逼出来的(port to WebExtensions · Issue #6 · nobodxbodon/HistoryInThreads). 顺便在主要算法部分改用了中文命名:
- 访问缓冲表.js: 主要数据结构
- utils.js: 所有不依赖于浏览器API的方法, 包括树的生成, 搜索时间处理, 根据关键词高亮历史记录等等
- history.js: 根据关键词获取所有可能相关的浏览历史. 由于新版火狐API除去了根据多个URL获取历史记录的功能(优化运行速度 · Issue #1 · program-in-chinese/HistoryInThreads_WebExtension), 只好搜索两次, 一次按照(搜索关键词+历史时间)搜索, 一次只按照历史时间搜索(多搜了很多, 只好用上面的缓冲表避免每次搜索时都搜几万项历史记录). 相关的部分代码如下:
var 按关键词搜索历史 = function(关键词, 历史时间范围) {
计时("调用前")
带关键词访问记录 = [];
未处理url数 = 0;
if (关键词 != null) {
当前关键词 = 关键词;
}
if (当前时间范围 == null || !不需重新索引(历史时间范围, 当前时间范围)) {
无关键词访问记录 = [];
访问细节表 = {};
var 新回溯时间 = 取历史回溯时间(历史时间范围);
历史回溯时间 = 新回溯时间;
当前时间范围 = 历史时间范围;
// TODO: 如果先按关键词搜索, 如果没有匹配, 可以省去搜索所有历史
// 首先搜索所有浏览历史
var 无关键词搜索选项 = 生成搜索选项('', 历史回溯时间);
var 无关键词搜索 = browser.history.search(无关键词搜索选项);
无关键词搜索.then(遍历无关键词历史记录);
} else {
var 带关键词搜索选项 = 生成搜索选项(当前关键词, 历史回溯时间);
var 带关键词搜索 = browser.history.search(带关键词搜索选项);
带关键词搜索.then(遍历带关键词历史记录);
}
};
最近疏于插件开发. 如有兴趣参与, 欢迎联系.