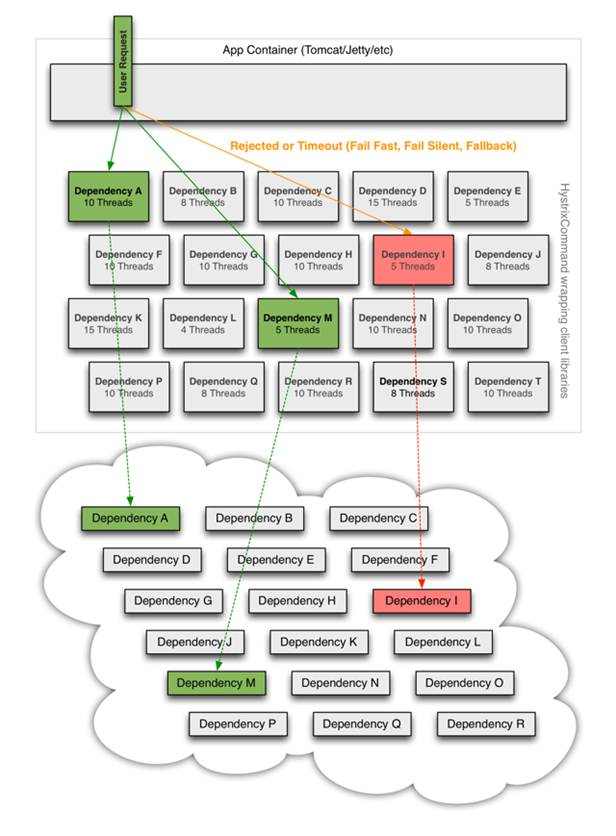
在大中型分布式系统中,通常系统很多依赖(HTTP,hession,Netty,Dubbo等),如下图:

在高并发访问下,这些依赖的稳定性与否对系统的影响非常大,但是依赖有很多不可控问题:如网络连接缓慢,资源繁忙,暂时不可用,服务脱机等.
如下图:QPS为50的依赖 I 出现不可用,但是其他依赖仍然可用.
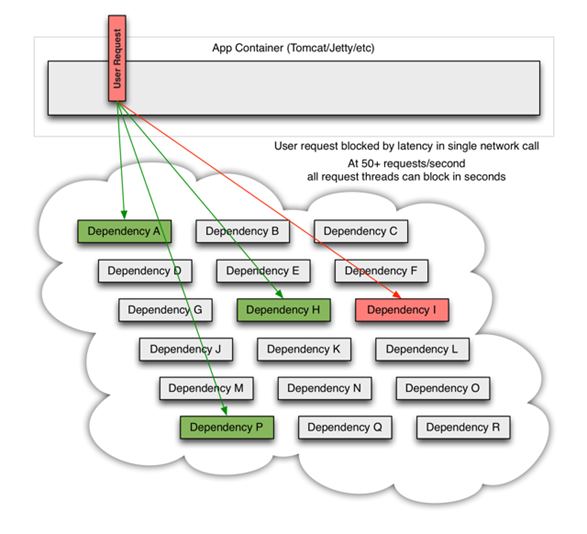
当依赖I 阻塞时,大多数服务器的线程池就出现阻塞(BLOCK),影响整个线上服务的稳定性.如下图:

在复杂的分布式架构的应用程序有很多的依赖,都会不可避免地在某些时候失败。高并发的依赖失败时如果没有隔离措施,当前应用服务就有被拖垮的风险。
Java代码 
- 例如:一个依赖30个SOA服务的系统,每个服务99.99%可用。
- 99.99%的30次方 ≈ 99.7%
- 0.3% 意味着一亿次请求 会有 3,000,00次失败
- 换算成时间大约每月有2个小时服务不稳定.
- 随着服务依赖数量的变多,服务不稳定的概率会成指数性提高.
解决问题方案:对依赖做隔离,Hystrix就是处理依赖隔离的框架,同时也是可以帮我们做依赖服务的治理和监控.
Netflix 公司开发并成功使用Hystrix,使用规模如下:
Java代码 
- The Netflix API processes 10+ billion HystrixCommand executions per day using thread isolation.
- Each API instance has 40+ thread-pools with 5-20 threads in each (most are set to 10).
二:Hystrix如何解决依赖隔离
1:Hystrix使用命令模式HystrixCommand(Command)包装依赖调用逻辑,每个命令在单独线程中/信号授权下执行。
2:可配置依赖调用超时时间,超时时间一般设为比99.5%平均时间略高即可.当调用超时时,直接返回或执行fallback逻辑。
3:为每个依赖提供一个小的线程池(或信号),如果线程池已满调用将被立即拒绝,默认不采用排队.加速失败判定时间。
4:依赖调用结果分:成功,失败(抛出异常),超时,线程拒绝,短路。 请求失败(异常,拒绝,超时,短路)时执行fallback(降级)逻辑。
5:提供熔断器组件,可以自动运行或手动调用,停止当前依赖一段时间(10秒),熔断器默认错误率阈值为50%,超过将自动运行。
6:提供近实时依赖的统计和监控
Hystrix依赖的隔离架构,如下图: