前言:
目前比较流行的缓存技术无疑是Memcached和Redis,两套缓存技术有着诸多的相似之处,但又具备大量的显著差异,作为新生的方案,Redis被视为首选,但是有些场景Memcached发挥的作用是不容忽视的。
相似点:
1. Memcached和Redis都属于In-Memory、Key-Value数据存储方案,同属于NoSQL家族,都选择将全部数据存储在内存中。
2. 都是成熟的开源项目,Memcached由Brad Fitzpatrick 2003年开发而成,Redis则由Salvatore Sanfilippo于2009创建。
3. 简单易用,只需几分钟就可以完成安装工作。
不同之处:
1. Redis支持服务器端的数据操作: Redis相对Memcached拥有更多的数据结构,支持丰富的数据操作。
2. 内存使用率:Memcached简单的key-value存储,内存利用率更高,而如果Redis采用hash结构来做Key-value存储,由于组合式的压缩,内存利用率更高。
3.性能对比:Redis单核,Memcached可以使用多核,所以平均每一个核上Redis在存储小数据时比Memcached性能更高。而在100k以上的数据中,Memcached性能要高于Redis,虽然Redis最近也在存储大数据的性能上进行优化,但是比起Memcached,还有些差距。
结合以上特性下面从两者的事件模型,内存管理,数据类型、集群管理、持久化详细讲解一下
一、事件模型
相同之处:都是用epol来做事件循环
不同之处:redis是单线程服务器(这里的单线程是指除了主线程以外其他线程没有event loop),redis事件模型只有一个event loop,是最简单的reactor的实现。redis事件模型中有一个亮点,redis里面的fd(详细请百度)就是服务器与客户端连接socket的fd,通常根据fd找到具体的客户端信息,通常的处理方式就是用红黑树将fd与客户端信息保存起来,通过fd查找,效率是lgn,不过redis比较特殊,redis客户端的数量上限可以设置,即同一时刻知道redis打开的fd的上限,且进程的fd在同一时刻是不会重复的,所以redis使用一个数据,将fd作为数组的下标,数组的元素就是客户端的信息,这样通过fd就能订位客户端信息,查找效率是O(1),省去了红黑树的实现。
Memcached是多线程的,使用Master-Worker的方式,其中主线程负责接收连接,然后将连接分给各个worker线程,在各个worker线程中完成命令的接收,处理和返回结果。
二、内存管理
1. Memcached使用预先分配,预先分配一大块内存,然后接下来就从内存池中分配,这样可以减少内存的分配次数,提高效率。Memcached的采用Slab Allocation,内存的结构决定了Value值的大小最大只能为1MB。
Slab Allocation的原理:将分配的内存分割成各种尺寸的块(chunk),并把尺寸相同的块分成组,每一组被称为slab。Memcached的内存分配以Page为单位,Page默认值为1M,可以在启动时通过-I参数来指定。Slab是由多个Page组成的,Page按照指定大小切割成多个chunk。memcached在启动时通过-f选项可以指定 Growth Factor因子。该值控制slab之间的差异,chunk大小的差异。默认值为1.25。其结构图如下:
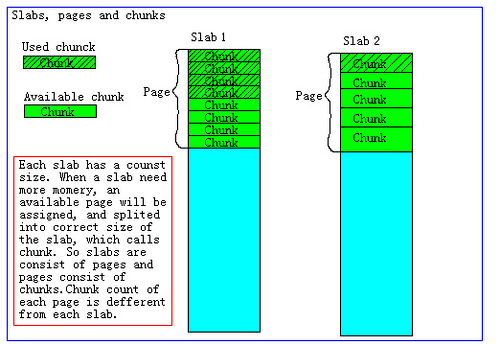

优缺点:Slab Allocation可以有效的解决内存碎片的问题,但是也会造成内存的浪费
1.每个slab的chunk大小是固定的,当item的占用空间实际小于chunk大小时,会出现内存浪费
2.每个slab的大小是固定的(因为page是固定的),当slab不能被他所拥有的chunk整除时,会出现内存浪费
3.按照Growth Factor因子生成指定大小的slab,而某slab id根本未被使用时,会出现内存浪费
2. Redis使用动态分配,由于C语言没有自带的GC,所以Redis的实现中封装了C的malloc,calloc,realloc和free函数来对自己的内存进行管理,这些实现都在zmalloc.h和zmalloc.c中。在Redis中,并不是所有的数据一直存储在内存中。当物理内存用完时,Redis可以将一些很久没用的Value交换到磁盘。Redis只会缓存所有的key,当Redis发现内存的使用量超过了一个阀值,将触发Swap操作,Redis根据“swappability = age*log(size_in_memory)”计算出哪些key对应的value需要swap到磁盘。然后再将这些key对应的value持久化到磁盘中,同时在内存中清除。这种特性使得Redis可以保持超过其机器本身内存大小的数据。当然,机器本身的内存必须要能够保持所有的key,毕竟这些数据是不会进行swap操作的。同时由于Redis将内存中的数据swap到磁盘中的时候,提供服务的主线程和进行swap操作的子线程会共享这部分内存,所以如果更新需要swap的数据,Redis将阻塞这个操作,直到子线程完成swap操作后才可以进行修改。当从Redis中读取数据的时候,如果读取的key对应的value不在内存中,那么Redis就需要从swap文件中加载相应数据,然后再返回给请求方。 这里就存在一个I/O线程池的问题。在默认的情况下,Redis会出现阻塞,即完成所有的swap文件加载后才会相应。这种策略在客户端的数量较小,进行批量操作的时候比较合适。但是如果将Redis应用在一个大型的网站应用程序中,这显然是无法满足大并发的情况的。所以Redis运行我们设置I/O线程池的大小,对需要从swap文件中加载相应数据的读取请求进行并发操作,减少阻塞的时间。
三、数据类型
Memcached仅支持简单的key-value结构的数据,Redis支持的数据类型要丰富得多。常用的由五种:String、Hash、List、Set和Sorted Set。Redis内部使用一个redisObject对象来表示所有的key和value。
四:集群管理
Memcached本身并不支持分布式,只能在客户端通过一致性hash这样的分布式算法来实现Memcached的分布式存储。 Redis更偏向服务端构建分布式存储,Redis Cluster是一个实现了分布式且允许单点故障的Redis高级版本,去中心化,具有线性可伸缩的功能。节点与节点之间通过二进制协议进行通信,节点与客户端之间通过ascii协议进行通信。在数据的放置策略上,Redis Cluster将整个key的数值域分成4096个哈希槽,每个节点上可以存储一个或多个哈希槽,也就是说当前Redis Cluster支持的最大节点数就是4096。Redis Cluster使用的分布式算法也很简单:crc16( key ) % HASH_SLOTS_NUMBER。
五:数据持久化
Memcached不支持数据持久化。Redis支持两种数据持久化RDB快照和AOF日志。
Redis Cluster引入了master-slave模式,每一个master都对应两个slave节点。
整体上说,两者的性能都很好,不必为哪个性能更高而纠结。不过,redis提供的持久化和数据同步机制,这些都是memcached没有的,所以如果你想要持久化,就只能用redis了。另外,memcached足以应付简单的键值存储,不过你要是想用更高级的数据结构,比如hash,list,set,zset之类的,redis提供了这些类型,用着更方便。