资源缓存
资源缓存的目的是为了提高资源使用的效率,其基本思想是建立一个资源的缓存池,当需要请求资源的时候先去资源池查找是否有相应的资源,如果没有则向服务器发送请求,webkit收到资源后将其设置到该资源类的对象中去,以便于缓存后下次使用,webkit从资源池中查找资源的关键字是URL,URL标记了资源的唯一性。
以上说明一个问题,如果ulr不同,就算内容相同也会被重新请求。
资源加载
鉴于从网络获取资源时一个非常耗时的过程,通常一些资源的加载是异步执行的,也就是说资源的获取和加载不会阻碍 当前 WebKit的渲染过程,例如图片、CSS文件。当然,网页也存在某些特别的资源会阻碍主线程的渲染过程,例如 JavaScript 代码文件。这会严重影响 WebKit 下载资源的效率,因为后面可能还有许多需要下载的资源,WebKit会怎么做?因为主线程被阻碍了,后面的解析工作没办法继续往下进行,所以对于 HTML 网页中后面使用的资源也没有办法知道并发送下载请求。当遇到这种情况的时候,WebKit的做法是这样的:当前的主线程被阻碍时。WebKit会启动另外一个线程去遍历后面的HTML页面,收集需要的资源URL,然后发送请求,这样就可以避免被阻碍。与此同时,WebKit 能够并发下载这些资源,甚至并发下载 JavaScript 代码资源。
为了验证以上是否正确,在本地搭了个服务器测试,其中有一个index.html页面,和一个服务器脚本,服务器脚本用来延迟加载js。
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<h2>h2</h2>
<script src="http://localhost:8081/index.js"></script>
<h3>h3</h3>
<img src="test/images/0.png" alt="">
<img src="test/images/1.png" alt="">
<img src="test/images/2.png" alt="">
<script src="index.js"></script>
<script>
console.log("ok");
</script>
</body>
</html>
nodejs脚本 index.js
var http = require("http");
http.createServer(function(req,res){
}).listen(8081);
index.html请求了8081端口的一个js脚本,但是我始终不给它响应。

可以看到加载js的那一块始终是一个pending状态,但是在js后面的资源还是被下载了,也就是说webkit确实是开了多个线程去下载资源的,但你也可以看到,它虽然是开了多个线程去下载资源,但是并没有去执行后面的代码,如下图
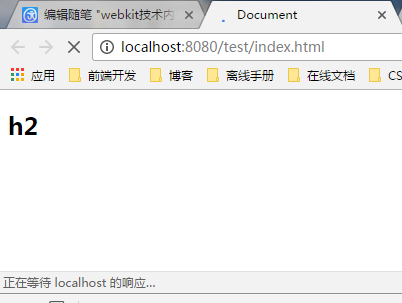
从另外一个方面也可以看出它没有去执行后面的代码,我在index.html中写了这么一段代码<script src="index.js"></script>假如说它执行了,那么应该报错才对,因为这段代码的内容就是那个nodejs中的,如果我返回内容,效果就是下面这样

也就是说,虽然资源webkit可能开多个线程去下载,但是执行代码,始终用的是一个线程,对于执行javascript代码使用一个线程执行,还算好理解,因为某些js文件可能依赖于其他的js文件,如果说使用多线程,这必然是一个比较麻烦的问题,另外如果某些js文件必须早于其他文件执行,那么多线程依然还是个问题,对于图片和dom大概也是同样的道理吧,如果说下载下来的图片,马上就去显示,那如果说我在前面的js中给body加了一个display:none;那么你说是这个图片是显示呢还是不显示呢?不能因为前面的js堵塞了后面的代码执行,你就乱显示吧,这也是多线程了一些烦恼吧。
资源的生命周期
同CachedResourceLoader对象一样,资源池也属于HTML文档对象,由于资源池不能无限大,因此要用相应的机制来替换其中的资源,从而加入新的资源,这种机制采用的算法为LRU(最近最少使用)算法。对于打开网页刷新当前页面的场景,对于某些资源,webkit需要直接重新发送请求,要求服务器端将内容重新发送过来,但对于大多数资源,Webkit则可以利用HTTP协议减少网络负载,在HTTP协议中对此有规定,游览器可以发送消息确认是否需要更新,如果有则游览器重新获取该资源,否则就需要利用该资源。
webkit的做法如下,首先判断资源是否在资源池中,如果在则发送一个HTTP请求给服务器,说明该资源在本地的一些信息,例如修改时间等,服务器根据该信息进行判断,如果没有更新则返回状态码304表示不需要更新,直接利用资源池中的资源,否则webkit申请下载最新的资源内容。
DNS预取和TCP预连接
一次DNS查询的平均时间大概在60~120ms之间或者更长,而TCP的三次握手时间大概也是几十毫秒或者更长,看似是一个很短的时间,但是相对于网页的渲染来说,这是一个相当长的时间,如何有效的缩短这段时间,Chromium给出了自己的解决方案—DNS预取和TCP预连接。
首先讲一下DNS预取,他的主要思想就是利用现有的DNS机制,提前解析网页中可能的网络连接。具体来说,就是当用户正在浏览当前网页的时候,Chromium提取网页中的超链接,将域名抽取出来,利用比较少的CPU和网络带宽来解析这部分域名或IP地址,这样一来,用户根本感觉不到这一过程。但是当用户单击这些链接的时候,由于已经提前做好了DNS解析,可以节省不少时间,特别是对于域名解析比较慢的时候,效果尤其明显。(DNS预取技术针对多个域名采取并行处理的方式,每个域名的解析均是由新开启的一个线程来处理的,结束后此线程即退出)
当然,我们也可以显式指定预取哪些域名来让Chromium解析,这非常直接了当。特别是对于那些需要重定向的域名,具体做法如下:
<link rel="dns-prefetch" href="http://this-is-a-dns-prefetch-example.com">。DNS预取技术不仅应用于网页中的超链接,当我们在地址栏中输入地址后,候选项同输入的地址很匹配的时候,在我们敲下回车键获取该网页之前,Chromium已经开始使用DNS预取技术解析该域名了。
接下来是TCP预连接,Chromium使用追踪技术来获取用户从什么网页跳转到另外一个网页,可以利用这些数据,一些启发式的规则和其他暗示来预测用户下面回单击什么超链接,当有足够的把握的时候,他便会DNS预取,更进一步,还可以预先简历TCP连接。听起来是不是特别6?不错,Chromium就是这么6!同DNS预取技术一样,追踪技术不仅应用于网页中的超链接,当用户在地址栏中输入地址的时候,也同样适用!