2.6、与 Hive 的集成
2.6.1、HBase 与 Hive 的对比
1) Hive
(1) 数据仓库
Hive 的本质其实就相当于将 HDFS 中已经存储的文件在 Mysql 中做了一个双射关系,以方 便使用 HQL 去管理查询。
(2) 用于数据分析、清洗
Hive 适用于离线的数据分析和清洗,延迟较高。
(3) 基于 HDFS、MapReduce
Hive 存储的数据依旧在 DataNode 上,编写的 HQL 语句终将是转换为 MapReduce 代码执行。
2) HBase
(1) 数据库
是一种面向列存储的非关系型数据库。
(2) 用于存储结构化和非结构话的数据 适用于单表非关系型数据的存储,不适合做关联查
询,类似JOIN 等操作
(3) 基于 HDFS
数据持久化存储的体现形式是 Hfile,存放于 DataNode 中,被 ResionServer 以 region 的形式 进行管理。
(4) 延迟较低,接入在线业务使用
面对大量的企业数据,HBase 可以直线单表大量数据的存储,同时提供了高效的数据访问速 度。
2.6.2、HBase 与 Hive 集成使用
尖叫提示:HBase 与 Hive 的集成在最新的两个版本中无法兼容。所以,我们只能含着泪勇 敢的重新编译:hive-hbase-handler-1.2.2.jar!!好气!!
环境准备
因为我们后续可能会在操作 Hive 的同时对 HBase 也会产生影响,所以 Hive 需要持有操作
HBase 的 Jar,那么接下来拷贝 Hive 所依赖的 Jar 包(或者使用软连接的形式)。
$ export HBASE_HOME= ~/hadoop_home/hbase-1.2.6
$ export HIVE_HOME= ~/hadoop_home/apache-hive-2.3.4-bin
$ ln -s $HBASE_HOME/lib/hbase-common-1.2.6.jar HIVE_HOME/lib/hbase-common-1.2.6.jar
$ ln -s $HBASE_HOME/lib/hbase-server-1.2.6.jar $HIVE_HOME/lib/hbase-server-1.2.6.jar
$ ln -s $HBASE_HOME/lib/hbase-client-1.2.6.jar $HIVE_HOME/lib/hbase-client-1.2.6.jar
$ ln -s $HBASE_HOME/lib/hbase-protocol-1.2.6.jar $HIVE_HOME/lib/hbase-protocol-1.2.6.jar
$ ln -s $HBASE_HOME/lib/hbase-it-1.2.6.jar $HIVE_HOME/lib/hbase-it-1.2.6.jar
$ ln -s $HBASE_HOME/lib/htrace-core-3.1.0-incubating.jar HIVE_HOME/lib/htrace-core-3.1.0-incubating.jar
$ ln -s $HBASE_HOME/lib/hbase-hadoop2-compat-1.2.6.jar HIVE_HOME/lib/hbase-hadoop2-compat-1.2.6.jar
$ ln -s $HBASE_HOME/lib/hbase-hadoop-compat-1.2.6.jar HIVE_HOME/lib/hbase-hadoop-compat-1.2.6.jar
同时在 hive-site.xml 中修改 zookeeper 的属性,如下:
<property>
<name>hive.zookeeper.quorum</name>
<value>master,node1,node2</value>
<description>The list of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
<description>The port of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
1) 案例一
目标:建立 Hive 表,关联 HBase 表,插入数据到 Hive 表的同时能够影响 HBase 表。
分步实现:
(1) 在 Hive 中创建表同时关联 HBase
CREATE TABLE hive_hbase_emp_table( empno int,
ename string,
job string, mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" =
":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
尖叫提示:完成之后,可以分别进入 Hive 和 HBase 查看,都生成了对应的表
(2) 在 Hive 中创建临时中间表,用于 load 文件中的数据
尖叫提示:不能将数据直接 load 进 Hive 所关联 HBase 的那张表中
CREATE TABLE emp(
empno int, ename string, job string, mgr int,
hiredate string, sal double, comm double, deptno int)
row format delimited fields terminated by ' ';
(3) 向 Hive 中间表中 load 数据
hive> load data local inpath '/home/hadoop_home/emp.txt' into table emp;
(4) 通过 insert 命令将中间表中的数据导入到 Hive 关联 HBase 的那张表中
hive> insert into table hive_hbase_emp_table select * from emp;
(5) 查看 Hive 以及关联的 HBase 表中是否已经成功的同步插入了数据
Hive:hive> select * from hive_hbase_emp_table;
HBase:
hbase> scan ‘hbase_emp_table’
2) 案例二
目标:在 HBase 中已经存储了某一张表 hbase_emp_table,然后在 Hive 中创建一个外部表来
关联 HBase 中的 hbase_emp_table 这张表,使之可以借助 Hive 来分析 HBase 这张表中的数 据。
注:该案例 2 紧跟案例 1 的脚步,所以完成此案例前,请先完成案例 1。
分步实现:
(1) 在 Hive 中创建外部表
CREATE EXTERNAL TABLE relevance_hbase_emp( empno int,
ename string, job string, mgr int,
hiredate string, sal double, comm double, deptno int)
STORED BY
'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" =
":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
(2) 关联后就可以使用 Hive 函数进行一些分析操作了
hive (default)> select * from relevance_hbase_emp;
2.7、与 Sqoop 的集成
Sqoop supports additional import targets beyond HDFS and Hive. Sqoop can also import records into a table in HBase.
之前我们已经学习过如何使用 Sqoop 在 Hadoop 集群和关系型数据库中进行数据的导入导出
工作,接下来我们学习一下利用 Sqoop 在 HBase 和 RDBMS 中进行数据的转储。

1) 案例
目标:将 RDBMS 中的数据抽取到 HBase 中
分步实现:
(1) 配置 sqoop-env.sh,添加如下内容:
export HBASE_HOME=~/hadoop_home/hbase-1.2.6
(2) 在 Mysql 中新建一个数据库 db_library,一张表 book
CREATE DATABASE db_library; CREATE TABLE db_library.book(
id int(4) PRIMARY KEY NOT NULLAUTO_INCREMENT, name VARCHAR(255) NOT NULL,
price VARCHAR(255) NOT NULL);
(3) 向表中插入一些数据
INSERT INTO db_library.book (name, price) VALUES('Lie Sporting', '30');
INSERT INTO db_library.book (name, price) VALUES('Pride & Prejudice', '70');
INSERT INTO db_library.book (name, price) VALUES('Fall of Giants', '50');
(4) 执行 Sqoop 导入数据的操作
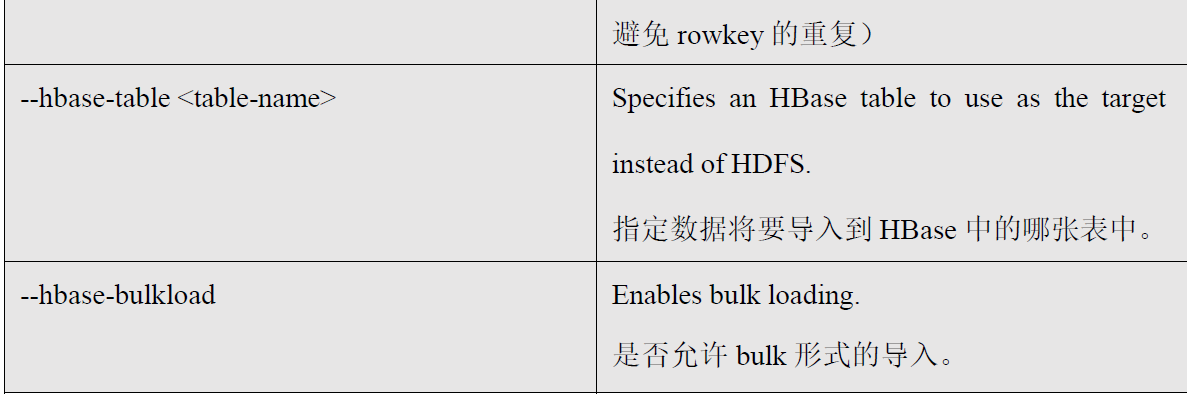
$ bin/sqoop import
--connect jdbc:mysql://master:3306/db_library
--username root
--password 111111
--table book
--columns "id,name,price"
--column-family "info"
--hbase-create-table
--hbase-row-key "id"
--hbase-table "hbase_book"
--num-mappers 1
--split-by id
尖叫提示:sqoop1.4.6 只支持 HBase1.0.1 之前的版本的自动创建 HBase 表的功能
解决方案:手动创建 HBase 表
hbase> create 'hbase_book','info'
(5) 在 HBase 中 scan 这张表得到如下内容
hbase> scan ‘hbase_book’
思考:尝试使用复合键作为导入数据时的 rowkey。
2.8、常用的 Shell 操作
1) satus
例如:显示服务器状态
hbase> status ‘master’
2) whoami
显示 HBase 当前用户,例如:
hbase> whoami
3) list
显示当前所有的表
hbase> list
4) count
统计指定表的记录数,例如:
hbase> count 'hbase_book'
5) describe
展示表结构信息
hbase> describe 'hbase_book'
6) exist
检查表是否存在,适用于表量特别多的情况
hbase> exist 'hbase_book'
7) is_enabled/is_disabled
检查表是否启用或禁用
hbase> is_enabled 'hbase_book'
hbase> is_disabled 'hbase_book'
8) alter
该命令可以改变表和列族的模式,例如:
为当前表增加列族:
hbase> alter 'hbase_book', NAME => 'CF2', VERSIONS => 2
为当前表删除列族:
hbase> alter 'hbase_book', 'delete' => ’CF2’
9) disable
禁用一张表
hbase> disable 'hbase_book'
10) drop
删除一张表,记得在删除表之前必须先禁用
hbase> drop 'hbase_book'
11) delete
删除一行中一个单元格的值,例如:
hbase> delete ‘hbase_book’, ‘rowKey’, ‘CF:C’
12) truncate
清空表数据,即禁用表-删除表-创建表
hbase> truncate 'hbase_book'
13) create
创建表,例如:
hbase> create ‘table’, ‘cf’
创建多个列族:
hbase> create 't1', {NAME => 'f1'}, {NAME => 'f2'}, {NAME => 'f3'}
2.9、数据的备份与恢复
2.9.1、备份
停止 HBase 服务后,使用 distcp 命令运行 MapReduce 任务进行备份,将数据备份到另一个 地方,可以是同一个集群,也可以是专用的备份集群。 即,把数据转移到当前集群的其他目录下(也可以不在同一个集群中):
hadoop fs -cp 即可
$ bin/hadoop distcp hdfs://master:9000/hbase
hdfs://master:9000/HbaseBackup/backup20190315
尖叫提示:执行该操作,一定要开启 Yarn 服务
2.9.2、恢复
非常简单,与备份方法一样,将数据整个移动回来即可。
$ bin/hadoop distcp
hdfs://master:9000/HbaseBackup/backup20190315 hdfs://master:9000/hbase
2.10、节点的管理
2.10.1、服役(commissioning)
当启动 regionserver 时,regionserver 会向 HMaster 注册并开始接收本地数据,开始的时候, 新加入的节点不会有任何数据,平衡器开启的情况下,将会有新的 region 移动到开启的 RegionServer 上。如果启动和停止进程是使用 ssh 和 HBase 脚本,那么会将新添加的节点的 主机名加入到 conf/regionservers 文件中。
2.10.2、退役(decommissioning)
顾名思义,就是从当前 HBase 集群中删除某个 RegionServer,这个过程分为如下几个过程:
1) 停止负载平衡器
hbase> balance_switch false
2) 在退役节点上停止RegionServer
hbase> hbase-daemon.sh stop regionserver
3) RegionServer 一旦停止,会关闭维护的所有region
Zookeeper 上的该RegionServer 节点消失
Master 节点检测到该RegionServer 下线
RegionServer 的region 服务得到重新分配
该关闭方法比较传统,需要花费一定的时间,而且会造成部分region 短暂的不可用。
另一种方案:
1) RegionServer 先卸载所管理的region
$ bin/graceful_stop.sh <RegionServer-hostname>
2) 自动平衡数据
3) 和之前的2~6 步是一样的
2.11、版本的确界
1) 版本的下界
默认的版本下界是 0,即禁用。row 版本使用的最小数目是与生存时间(TTL Time To Live) 相结合的,并且我们根据实际需求可以有 0 或更多的版本,使用 0,即只有 1 个版本的值写 入 cell。
2) 版本的上界
之前默认的版本上界是 3,也就是一个 row 保留 3 个副本(基于时间戳的插入)。该值不要 设计的过大,一般的业务不会超过 100。如果 cell 中存储的数据版本号超过了 3 个,再次插 入数据时,最新的值会将最老的值覆盖。(现版本已默认为 1)