这一节讲述rpn-data层,和这一层有关的结构图如下:
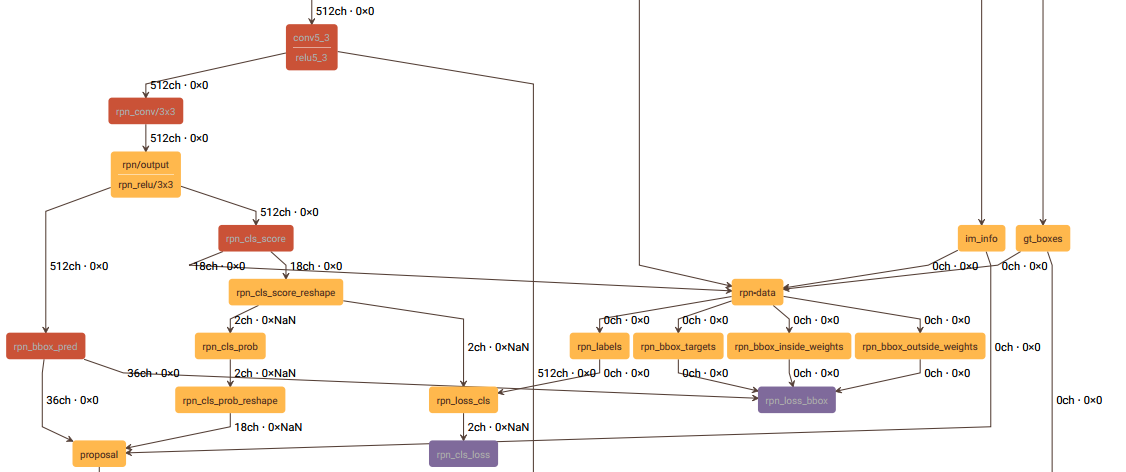
rpn-data层的prototxt定义如下:
layer { name: 'rpn-data' type: 'Python' bottom: 'rpn_cls_score' bottom: 'gt_boxes' bottom: 'im_info' bottom: 'data' top: 'rpn_labels' top: 'rpn_bbox_targets' top: 'rpn_bbox_inside_weights' top: 'rpn_bbox_outside_weights' python_param { module: 'rpn.anchor_target_layer' layer: 'AnchorTargetLayer' param_str: "'feat_stride': 16" } }
这一层的主要工作如下:
一、生成anchor,并将超出图像区域的anchor去除,得到有效的anchor;
二、给每一个anchor分配label,-1表示忽略该anchor,0表示背景,1表示前景(物体),得到labels;
三、计算RPN阶段的回归目标bbox_targets;
四、计算bbox_inside_weights、bbox_outside_weights,在计算SmoothL1Loss时用于加权;
五、上述过程得到的labels, bbox_targets, bbox_inside_weights, bbox_outside_weights,它们第一个维度的长度和有效anchor的个数是相同的,最后对它们进行扩充,将无效的anchor所对应的labels, bbox_targets, bbox_inside_weights, bbox_outside_weights分别加入其中,使这四个输出第一个维度的长度等于生成anchor的个数。
下面分别介绍这5个部分。
一、生成anchor
1、先生成一个base_anchor,长宽都为16,得出base_anchor的宽高和中心点:w, h, x_ctr, y_ctr;
2、由基准尺度(base_size=16)和3种长宽比0.5, 1, 2计算出3种宽高,再由步骤1得到的中心点计算出3个anchor的坐标;
3、再将3种尺度8, 16, 32和步骤2所得anchor的尺度相乘,得出9种宽高,结合步骤1所得中心点坐标,最终得到9个anchor的坐标。
4、使backbone输出的feature map的每一个位置的坐标间隔为feature map的降采样率(VGG为16),这样,feature map像素坐标的尺度就和输入网络的图像像素的坐标尺度一样了。将步骤3所得到的9个anchor的中心点分别移动到feature map每个像素的坐标位置上,便得到了最终的anchor。
二、分配label
1、构建一个label数组,长度有效anchor的数量,每个元素都初始化为-1;
2、计算每个anchor和所有gt的交并比;
3、将和所有gt的交并比都小于0.3的anchor,label分配为0,即为背景;
4、将和每一个gt交并比最大的anchor,label分配为1,即为前景;
5、将和任意一个gt交并比能大于0.7的anchor,label分配为1,即为前景;
6、RPN阶段的batchsize为256,前景anchor占比为0.5,因此有128个。如果前面得到的前景anchor的数量超过了128,则随机剔除多余的anchor,剔除的部分label置为-1;
7、batchsize为256,除去前景anchor的数量,剩余的即为背景anchor的数量。若背景anchor数量过多,则随机剔除多余的背景,剔除的部分label仍置为-1。
三、计算RPN阶段的回归目标
回归目标其实就是anchor的中心点坐标、宽、高和与之交并比最大的gt的偏差dx, dy, dw, dh,这些偏差不是二者直接作差得到的,而是经过一些转换才得到的,具体见下面的代码:
def bbox_transform(ex_rois, gt_rois): ex_widths = ex_rois[:, 2] - ex_rois[:, 0] + 1.0 ex_heights = ex_rois[:, 3] - ex_rois[:, 1] + 1.0 ex_ctr_x = ex_rois[:, 0] + 0.5 * ex_widths ex_ctr_y = ex_rois[:, 1] + 0.5 * ex_heights gt_widths = gt_rois[:, 2] - gt_rois[:, 0] + 1.0 gt_heights = gt_rois[:, 3] - gt_rois[:, 1] + 1.0 gt_ctr_x = gt_rois[:, 0] + 0.5 * gt_widths gt_ctr_y = gt_rois[:, 1] + 0.5 * gt_heights targets_dx = (gt_ctr_x - ex_ctr_x) / ex_widths targets_dy = (gt_ctr_y - ex_ctr_y) / ex_heights targets_dw = np.log(gt_widths / ex_widths) targets_dh = np.log(gt_heights / ex_heights) targets = np.vstack( (targets_dx, targets_dy, targets_dw, targets_dh)).transpose() return targets
四、计算一些权重,用于SmoothL1Loss的计算
1、bbox_inside_weights:将label为1的anchor权重赋为1,其他的都赋为0;
2、bbox_outside_weights:将前景和背景anchor的总数记为n,则前景和背景anchor权重都赋为1/n,其它的anchor权重都赋为0。
五、结果扩充
这一步的目的是为了使这一层的输出结果的维度和其它层的结果相匹配,直接能和其它层的输出结合起来,一起参与网络的前向和反向计算。
最后给出SmoothL1Loss的主要代码:
template <typename Dtype> void SmoothL1LossLayer<Dtype>::LayerSetUp( const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { SmoothL1LossParameter loss_param = this->layer_param_.smooth_l1_loss_param(); sigma2_ = loss_param.sigma() * loss_param.sigma(); has_weights_ = (bottom.size() >= 3); if (has_weights_) { CHECK_EQ(bottom.size(), 4) << "If weights are used, must specify both " "inside and outside weights"; } } template <typename Dtype> void SmoothL1LossLayer<Dtype>::Reshape( const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { LossLayer<Dtype>::Reshape(bottom, top); CHECK_EQ(bottom[0]->channels(), bottom[1]->channels()); CHECK_EQ(bottom[0]->height(), bottom[1]->height()); CHECK_EQ(bottom[0]->width(), bottom[1]->width()); if (has_weights_) { CHECK_EQ(bottom[0]->channels(), bottom[2]->channels()); CHECK_EQ(bottom[0]->height(), bottom[2]->height()); CHECK_EQ(bottom[0]->width(), bottom[2]->width()); CHECK_EQ(bottom[0]->channels(), bottom[3]->channels()); CHECK_EQ(bottom[0]->height(), bottom[3]->height()); CHECK_EQ(bottom[0]->width(), bottom[3]->width()); } diff_.Reshape(bottom[0]->num(), bottom[0]->channels(), bottom[0]->height(), bottom[0]->width()); errors_.Reshape(bottom[0]->num(), bottom[0]->channels(), bottom[0]->height(), bottom[0]->width()); // vector of ones used to sum ones_.Reshape(bottom[0]->num(), bottom[0]->channels(), bottom[0]->height(), bottom[0]->width()); for (int i = 0; i < bottom[0]->count(); ++i) { ones_.mutable_cpu_data()[i] = Dtype(1); } } template <typename Dtype> __global__ void SmoothL1Forward(const int n, const Dtype* in, Dtype* out, Dtype sigma2) { // f(x) = 0.5 * (sigma * x)^2 if |x| < 1 / sigma / sigma // |x| - 0.5 / sigma / sigma otherwise CUDA_KERNEL_LOOP(index, n) { Dtype val = in[index]; Dtype abs_val = abs(val); if (abs_val < 1.0 / sigma2) { out[index] = 0.5 * val * val * sigma2; } else { out[index] = abs_val - 0.5 / sigma2; } } } template <typename Dtype> void SmoothL1LossLayer<Dtype>::Forward_gpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { int count = bottom[0]->count(); caffe_gpu_sub( count, bottom[0]->gpu_data(), bottom[1]->gpu_data(), diff_.mutable_gpu_data()); // d := b0 - b1 if (has_weights_) { // apply "inside" weights caffe_gpu_mul( count, bottom[2]->gpu_data(), diff_.gpu_data(), diff_.mutable_gpu_data()); // d := w_in * (b0 - b1) } SmoothL1Forward<Dtype><<<CAFFE_GET_BLOCKS(count), CAFFE_CUDA_NUM_THREADS>>>( count, diff_.gpu_data(), errors_.mutable_gpu_data(), sigma2_); CUDA_POST_KERNEL_CHECK; if (has_weights_) { // apply "outside" weights caffe_gpu_mul( count, bottom[3]->gpu_data(), errors_.gpu_data(), errors_.mutable_gpu_data()); // d := w_out * SmoothL1(w_in * (b0 - b1)) } Dtype loss; caffe_gpu_dot(count, ones_.gpu_data(), errors_.gpu_data(), &loss); top[0]->mutable_cpu_data()[0] = loss / bottom[0]->num(); }
其中:
1、bottom[0]为rpn_bbox_pred,即网络预测出的anchor与gt的偏差;
2、bottom[1]为rpn_bbox_targets,即为第三步计算出的anchor与gt的实际偏差;
3、bottom[2]为bbox_inside_weights;
4、bottom[3]为bbox_outside_weights。
这一层的代码链接见这里,此外涉及到的其它函数有generate_anchors,bbox_overlaps。