需求:模拟登录知乎,因为知乎首页需要登录才可以查看,所以想爬知乎上的内容首先需要登录,那么问题来了,怎么用python进行模拟登录以及会遇到哪些问题?
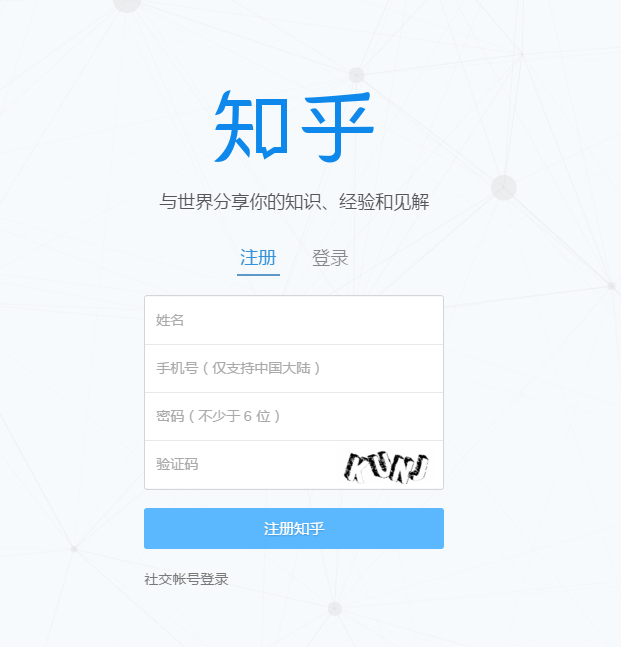
前期准备:
环境:ubuntu,python2.7
需要的包:requests包、正则表达式包
安装requests:pip install requests,关于requests的介绍可以看官方介绍:http://cn.python-requests.org/zh_CN/latest/user/quickstart.html , 以及 http://cuiqingcai.com/2556.html 讲的也很好,简单明了
requests包其实是代替了urllib2,并且提供了大量简洁好用的方法调用。
注意:通过Chrome Devtool可以看到知乎登录的URL是:https//www.zhihu.com/login/email,使用邮箱进行登录。
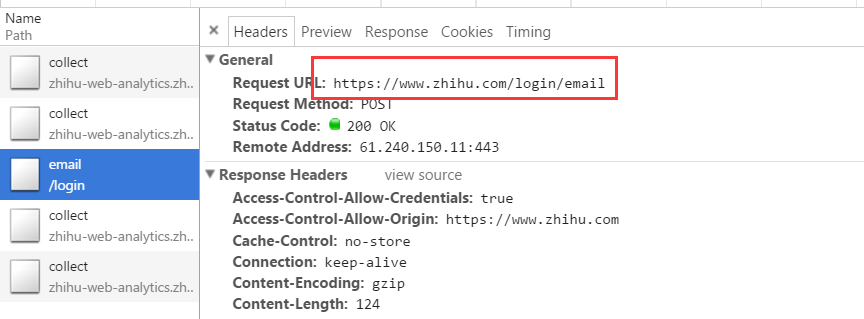
登录的方式为POST,需要的参数有四个分别是:_xsrf、password、remember_me和email,除了第一个都很好理解,那么第一个参数是什么?
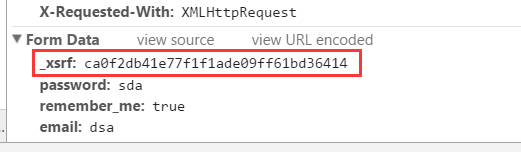
XSRF为跨站请求伪造(Cross-site request forgery),通过搜集资料,在大神的博客里找到有相应资料,http://cuiqingcai.com/2076.html ,说的也很清楚,有兴趣可以查看。这个参数目的就是为了防范XSRF攻击而设置的一个hash值,每次访问主页都会生成这样一个唯一的字符串。那么怎么获取这个参数的值,经过对知乎首页(https://www.zhihu.com)的代码查看可以看到有一个隐藏的标签:

那么就好解决了,直接在爬下来的网页内容中用正则表达式去匹配就OK了。
代码:
import requests import re def getContent(url):
#使用requests.get获取知乎首页的内容 r = requests.get(url)
#request.get().content是爬到的网页的全部内容 return r.content
#获取_xsrf标签的值 def getXSRF(url):
#获取知乎首页的内容 content = getContent(url)
#正则表达式的匹配模式 pattern = re.compile('.*?<input type="hidden" name="_xsrf" value="(.*?)"/>.*?')
#re.findall查找所有匹配的字符串 match = re.findall(pattern, content) xsrf = match[0]
#返回_xsrf的值 return xsrf
#登录的主方法 def login(baseurl,email,password):
#post需要的表单数据,类型为字典 login_data = { '_xsrf': getXSRF(baseurl), 'password': password, 'remember_me': 'true', 'email': email, }
#设置头信息 headers_base = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate, sdch', 'Accept-Language': 'en-US,en;q=0.8,zh-CN;q=0.6,zh;q=0.4,zh-TW;q=0.2', 'Connection': 'keep-alive', 'Host': 'www.zhihu.com', 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.130 Safari/537.36', 'Referer': 'http://www.zhihu.com/', } #使用seesion登录,这样的好处是可以在接下来的访问中可以保留登录信息 session = requests.session()
#登录的URL baseurl += "/login/email"
#requests 的session登录,以post方式,参数分别为url、headers、data content = session.post(baseurl, headers = headers_base, data = login_data)
#成功登录后输出为 {"r":0,
#"msg": "u767bu9646u6210u529f"
#} print content.text
#再次使用session以get去访问知乎首页,一定要设置verify = False,否则会访问失败 s = session.get("http://www.zhihu.com", verify = False) print s.text.encode('utf-8')
#把爬下来的知乎首页写到文本中 f = open('zhihu.txt', 'w') f.write(s.text.encode('utf-8'))
url = "http://www.zhihu.com" #进行登录,将星号替换成你的知乎登录邮箱和密码即可 login(url,"******@***.com","************")
最后,就成功把知乎首页的内容抓取下来了!下一步可以进行分析和筛选了。