1、在spider文件夹同级目录创建commands python包
2、在包下创建command.py文件
3、从scrapy.commands包下引入ScrapyCommand
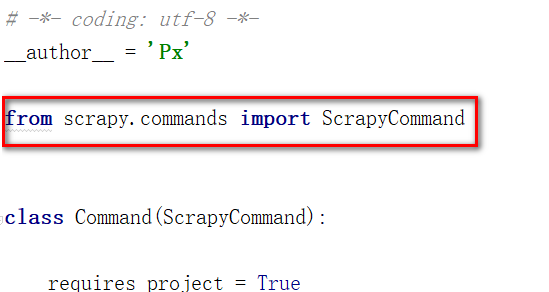
4、创建一个类,继承ScrapyCommand
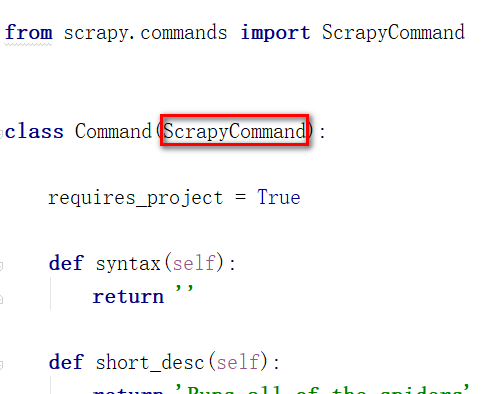
5、重新定义类变量 requires_project = True

6、重写syntax short_desc方法,syntax返回空字符串 short_desc返回描述字符串

7、重写run方法。
8、在settings.py 中添加配置 COMMANDS_MODULE = '项目名称.目录名称'
def run(self, args, opts): spider_list = self.crawler_process.spiders.list() #通过self.crawler_process.spider.list()获得所有爬虫 for name in spider_list: #遍历所有爬虫 self.crawler_process.crawl(name, **opts.__dict__) #运行爬虫 self.crawler_process.start() #启动进程
crawler_process 来自父类
完整代码
# -*- coding: utf-8 -*-
__author__ = 'Px'
from scrapy.commands import ScrapyCommand
class Command(ScrapyCommand):
requires_project = True
def syntax(self):
return ''
def short_desc(self):
return 'Runs all of the spiders'
def run(self, args, opts):
spider_list = self.crawler_process.spiders.list()
for name in spider_list:
self.crawler_process.crawl(name, **opts.__dict__)
self.crawler_process.start()